This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizational data is often fragmented across multiple lines of business, leading to inconsistent and sometimes duplicate datasets. This fragmentation can delay decision-making and erode trust in available data. This solution enhances governance and simplifies access to unstructureddata assets across the organization.
This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Companies that implement DataOps find that they are able to reduce cycle times from weeks (or months) to days, virtually eliminate data errors, increase collaboration, and dramatically improve productivity.
“It is a capital mistake to theorize before one has data.”– Data is all around us. Data has changed our lives in many ways, helping to improve the processes, initiatives, and innovations of organizations across sectors through the power of insight. Let’s kick things off by asking the question: what is a data dashboard?
Finance is poised to undergo a transformation, as Artificial Intelligence (AI) steps in to make real-time decisions using vast data sets. Mr. Cao highlighted that globally, there will soon be 100 billion connections, and with those, an explosion of data to the zettabyte level. This model treats entire data centres as computers. “We
Finance is poised to undergo a transformation, as Artificial Intelligence (AI) steps in to make real-time decisions using vast data sets. Mr. Cao highlighted that globally, there will soon be 100 billion connections, and with those, an explosion of data to the zettabyte level. This model treats entire data centres as computers. “We
During this period, those working for each city’s Organising Committee for the Olympic Games (OCOG) collect a huge amount of data about the planning and delivery of the Games. At the Information, Knowledge, and Games Learning (IKL) unit, we anticipate collecting about 1TB of data from primary sources.
But with all the excitement and hype, it’s easy for employees to invest time in AI tools that compromise confidential data or for managers to select shadow AI tools that haven’t been through security, data governance, and other vendor compliance reviews.
We use leading-edge analytics, data, and science to help clients make intelligent decisions. We developed and host several applications for our customers on Amazon Web Services (AWS). Data ingestion: The data ingestion layer is the first step of the proposed framework.
No matter if you need to conduct quick online data analysis or gather enormous volumes of data, this technology will make a significant impact in the future. An exemplary application of this trend would be Artificial Neural Networks (ANN) – the predictive analytics method of analyzing data.
Cloud technology and innovation drives data-driven decision making culture in any organization. Cloud washing is storing data on the cloud for use over the internet. Storing data is extremely expensive even with VMs during this time. The platform is built on S3 and EC2 using a hosted Hadoop framework.
Digging into quantitative data Why is quantitative data important What are the problems with quantitative data Exploring qualitative data Qualitative data benefits Getting the most from qualitative data Better together. Almost every modern organization is now a data-generating machine. or “how often?”
We just announced Cloudera DataFlow for the Public Cloud (CDF-PC), the first cloud-native runtime for Apache NiFi data flows. Apache Nifi is a powerful tool to build data movement pipelines using a visual flow designer. Implementing an automated scale up and scale down procedure for NiFi clusters is complex and time consuming.
With the rise of highly personalized online shopping, direct-to-consumer models, and delivery services, generative AI can help retailers further unlock a host of benefits that can improve customer care, talent transformation and the performance of their applications. trillion in that year.
This collaboration is set to enhance Allitix’s offerings by leveraging Cloudera’s secure, open data lakehouse, empowering enterprises to scale advanced predictive models and data-driven solutions across their environments. These large, regulated organizations depend heavily on data management and security.
Over the past 5 years, big data and BI became more than just data science buzzwords. Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on.
If you play fantasy football, you are no stranger to data-driven decision-making. And this year, ESPN Fantasy Football is using AI models built with watsonx to provide 11 million fantasy managers with a data-rich, AI-infused experience that transcends traditional statistics. But numbers only tell half the story. Not anymore.
Paco Nathan ‘s latest article covers program synthesis, AutoPandas, model-drivendata queries, and more. In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated.
Organizations are collecting and storing vast amounts of structured and unstructureddata like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. We think of this concept as inside-out data movement. Example Corp.
With data at the heart of its business, SMG has for many years pursued the most cutting-edge data management technologies. As SMG continued to innovate, the scale, variety and velocity of data made its legacy warehouse environment show its limits. The case for a new Data Warehouse? Data-driven Proof of Concept.
These dis-integrated resources are “data platforms” in name only: in addition to their high maintenance costs, their lack of interoperability with other critical systems makes it difficult to respond to business change. The top-line benefits of a hybrid data platform include: Cost efficiency. Simplified compliance. Flexibility.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”. This is partly because integrating and moving data is not the only problem.
Data and content are organized in a way that facilitates discoverability, insights and decision making rather than be bound by limitations of data formats and legacy systems. GraphQL has a number of advantages for developers, especially for data-centric applications. Data silos are as costly as they are inevitable.
In today’s world, data warehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed data warehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
To provide the ability to integrate diverse data sources. To support the need to connect AI-driven decisions directly with existing business applications and services, like Snowflake, Salesforce, and ServiceNow. We’re building a platform for all users: data scientists, analytics experts, business users, and IT.
Businesses are increasingly embracing data-intensive workloads, including high-performance computing, artificial intelligence (AI) and machine learning (ML). Their activity requires active cooling and management of the data center spaces that they operate in. This metric varies based on the energy source.
Data warehouse vs. databases Traditional vs. Cloud Explained Cloud data warehouses in your data stack A data-driven future powered by the cloud. We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. And where does all this data live?
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional data lake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
It enriched their understanding of the full spectrum of knowledge graph business applications and the technology partner ecosystem needed to turn data into a competitive advantage. Content and data management solutions based on knowledge graphs are becoming increasingly important across enterprises.
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to big data while machine learning focuses on learning from the data itself. What is data science? One challenge in applying data science is to identify pertinent business issues.
Continue to conquer data chaos and build your data landscape on a sturdy and standardized foundation with erwin® Data Modeler 14.0. The gold standard in data modeling solutions for more than 30 years continues to evolve with its latest release, highlighted by: PostgreSQL 16.x
And in this episode, we bring you one such self-driven and ambitious woman who chose her own path. I’m your host, Sushmita Krishnakumar. And today, it’s an honor to host such a talent. Sushmita: So Rajani, you started as a data science practitioner a few years back. Hey, Rajani, welcome to the podcast.
As the world becomes increasingly digitized, the amount of data being generated on a daily basis is growing at an unprecedented rate. This has led to the emergence of the field of Big Data, which refers to the collection, processing, and analysis of vast amounts of data. What is Big Data? What is Big Data?
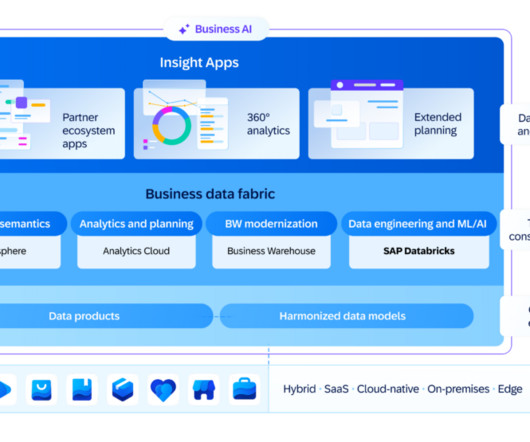
On February 13 th 2025, SAP announced the new managed software-as-a-service offering SAP Business Data Cloud (BDC). Business Data Cloud (BDC) consists of multiple existing and new services built by SAP and its partners: Object store which is an OEM from Databricks Databricks Data Engineering and AI/ML Tools SAP Datasphere SAP BW 7.5
The coup started with data at the heart of delivering business value. Start with data as an AI foundation Data quality is the first and most critical investment priority for any viable enterprise AI strategy. Data trust is simply not possible without data quality.
Amazon EMR has long been the leading solution for processing big data in the cloud. Amazon EMR is the industry-leading big data solution for petabyte-scale data processing, interactive analytics, and machine learning using over 20 open source frameworks such as Apache Hadoop , Hive, and Apache Spark.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



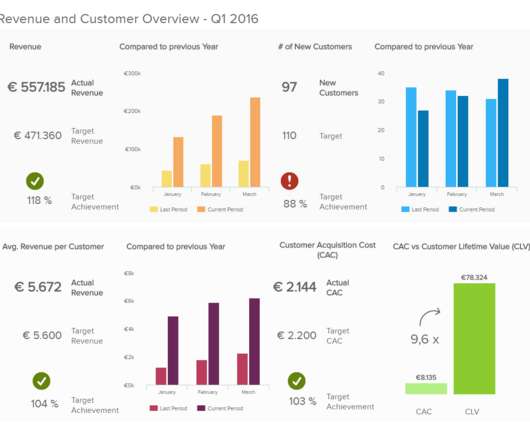





































Let's personalize your content