This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
As you experience the benefits of consolidating your data governance strategy on top of Amazon DataZone, you may want to extend its coverage to new, diverse data repositories (either self-managed or as managed services) including relational databases, third-party data warehouses, analytic platforms and more.
For the past 5 years, BMS has used a custom framework called Enterprise Data Lake Services (EDLS) to create ETL jobs for business users. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). It retrieves the specified files and available metadata to show on the UI.
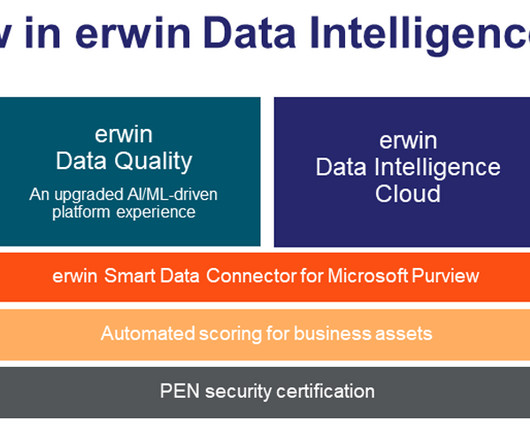
Added dataquality capability ready for an AI era Dataquality has never been more important than as we head into this next AI-focused era. erwin DataQuality is the dataquality heart of erwin Data Intelligence. erwin DataQuality is the dataquality heart of erwin Data Intelligence.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. You might have millions of short videos , with user ratings and limited metadata about the creators or content.
Data governance is best defined as the strategic, ongoing and collaborative processes involved in managing data’s access, availability, usability, quality and security in line with established internal policies and relevant data regulations. erwin Data Intelligence. Click here to read our success story on how E.ON
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure.
Within each episode, there are actionable insights that data teams can apply in their everyday tasks or projects. The host is Tobias Macey, an engineer with many years of experience. Agile Data. Agile Data. Another podcast we think is worth a listen is Agile Data. TDWI – Philip Russom.
The Data Fabric paradigm combines design principles and methodologies for building efficient, flexible and reliable data management ecosystems. Knowledge Graphs are the Warp and Weft of a Data Fabric. To implement any Data Fabric approach, it is essential to be able to understand the context of data.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data. Then, you transform this data into a concise format.
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. The groundwork of training data in an AI model is comparable to piloting an airplane. The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions.
“Always the gatekeepers of much of the data necessary for ESG reporting, CIOs are finding that companies are even more dependent on them,” says Nancy Mentesana, ESG executive director at Labrador US, a global communications firm focused on corporate disclosure documents. There are several things you need to report attached to that number.”
In this blog, we’ll delve into the critical role of governance and data modeling tools in supporting a seamless data mesh implementation and explore how erwin tools can be used in that role. erwin also provides data governance, metadata management and data lineage software called erwin Data Intelligence by Quest.
Combining the power of Domino Data Labs with Okera, your data scientists only get access to the columns, rows, and cells allowed, easily removing or redacting sensitive data such as PII and PHI not relevant to training models. For the compliance team, the combination of Okera and Domino Data Lab is extremely powerful.
Prior to the creation of the data lake, Orca’s data was distributed among various data silos, each owned by a different team with its own data pipelines and technology stack. Moreover, running advanced analytics and ML on disparate data sources proved challenging.
Establish what data you have. Active metadata gives you crucial context around what data you have and how to use it wisely. Active metadata provides the who, what, where, and when of a given asset, showing you where it flows through your pipeline, how that data is used, and who uses it most often.
Modern data governance relies on automation, which reduces costs. Automated tools make data governance processes very cost-effective. Machine learning plays a key role, as it can increase the speed and accuracy of metadata capture and categorization. This empowers leaders to see and refine human processes around data.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
This past week, I had the pleasure of hostingData Governance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , Data Governance lead at Alation. In the final consumption layer, the data fields could be tagged for governance, PII specifics, and advanced classification and categorization.
If you’re not familiar with DGIQ, it’s the world’s most comprehensive event dedicated to, you guessed it, data governance and information quality. This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders.
This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. The blend of our technologies provides the perfect environment for content and data management applications in many knowledge-intensive enterprises.
Chargeback metadata Amazon Redshift provides different pricing models to cater to different customer needs. The data between these data warehouses is shared via Amazon Redshifts data sharing and allows you to consume data from a consumer data warehouse even if the provider data warehouse is inactive.
It is also hard to know whether one can trust the data within a spreadsheet. And they rarely, if ever, host the most current data available. Sathish Raju, cofounder & CTO, Kloudio and senior director of engineering, Alation: This presents challenges for both business users and data teams.
I had the pleasure of chatting with John Furrier of theCUBE about how our recent round of funding will fuel innovation within the Alation Data Catalog. I’m John Furrier, co-host of theCUBE. What’s going on with the whole data at the center? This is certified data. Check out our conversation below.
On January 4th I had the pleasure of hosting a webinar. It was titled, The Gartner 2021 Leadership Vision for Data & Analytics Leaders. This was for the Chief Data Officer, or head of data and analytics. where performance and dataquality is imperative? Tools there are a plenty.
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. Much as the analytics world shifted to augmented analytics, the same is happening in data management. Where these efforts break down is in the data that goes into the connection at one end and comes out the other.
There are multiple tables related to customers and order data in the RDS database. Amazon S3 hosts the metadata of all the tables as a.csv file. This is especially true when you are processing millions of items and you expect dataquality issues in the dataset.
The quick and dirty definition of data mapping is the process of connecting different types of data from various data sources. Data mapping is a crucial step in data modeling and can help organizations achieve their business goals by enabling data integration, migration, transformation, and quality.
In this post, we discuss how Volkswagen Autoeuropa used Amazon DataZone to build a data marketplace based on data mesh architecture to accelerate their digital transformation. Dataquality issues – Because the data was processed redundantly and shared multiple times, there was no guarantee of or control over the quality of the data.
Specializing in data, their teams are dedicated to ensuring the seamless integration, management, and accessibility of data across multiple facets of the organization. Performance Optimization: A significant portion of the DAGs are dynamically generated based on database metadata.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content