This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Digital transformation started creating a digital presence of everything we do in our lives, and artificial intelligence (AI) and machine learning (ML) advancements in the past decade dramatically altered the data landscape. Implementing ML capabilities can help find the right thresholds.
Data debt that undermines decision-making In Digital Trailblazer , I share a story of a private company that reported a profitable year to the board, only to return after the holiday to find that dataquality issues and calculation mistakes turned it into an unprofitable one.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
Many enterprises encounter bottlenecks related to dataquality, model deployment, and infrastructure requirements that hinder scaling efforts. Effortless Model Deployment with Cloudera AI Inference Cloudera AI Inference service offers a powerful, production-grade environment for deploying AI models at scale.
They struggle with ensuring consistency, accuracy, and relevance in their product information, which is critical for delivering exceptional shopping experiences, training reliable AI models, and building trust with their customers. The platform offers tailored solutions for different market segments.
Fortunately, Teradata offers integrations to many modular tools that facilitate routine processes allowing data engineers to focus on high-value tasks such as governance, dataquality, and efficiency. The data pipeline is composed of multiple stages, beginning with the ingestion of raw data through Airbyte.
They are often unable to handle large, diverse data sets from multiple sources. Another issue is ensuring dataquality through cleansing processes to remove errors and standardize formats. Staffing teams with skilled data scientists and AI specialists is difficult, given the severe global shortage of talent.
That means creating custom models, fine-tuning existing models, or using retrieval augmented generation (RAG) embedding to give gen AI systems access to up-to-date and accurate corporate information. We didn’t want our data going into a public model,” says Matt Bostrom, Spirent’s VP of enterprise technology and strategy.
The Solution: Data Strategy as well as AI It is tempting to think that the answer to succesful AI is to implement more AI! Instead, organizations must prioritize: Cohesive data governance Rigorous dataquality controls Effective integration frameworks A strong data strategy is the foundation of sustainable AI success.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure.
This approach showed limitations as the data complexity increased, data volumes grew, and demand for quick, business-driven insights rose. These challenges are encountered by financial institutions worldwide, leading to a reassessment of traditional data management practices.
SageMaker brings together AWS artificial intelligence and machine learning (AI/ML) and analytics capabilities and delivers an integrated experience for analytics and AI with unified access to data. The SageMaker compatibility with OpenLineage can help simplify governance of your data assets and increase trust in your data.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
Data domains In the data mesh architecture, data domains represent distinct business areas or use cases within an organization. Each data domain is owned and managed by a dedicated team responsible for its dataquality, governance, and accessibility.
Though vector embedding and high dimensional mapping to the Vector Space Model (VSM) has recently gained prominence, headspace, and usage with the advent of GenAI, it has been used as a key information retrieval technique for over two decades. Popular full-text search engines have been leveraging VSM for years. GraphDBs v 10.8
My journey started by looking at the AI opportunity landscape in terms of business and technology maturity models, patterns, risk, reward and the path to business value. Start with data as an AI foundation Dataquality is the first and most critical investment priority for any viable enterprise AI strategy.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. OwlDQ — Predictive dataquality.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. For machine learning systems used in consumer internet companies, models are often continuously retrained many times a day using billions of entirely new input-output pairs.
Some of these ‘structures’ may include putting all the information; for instance, a structure could be about cars, placing them into tables that consist of makes, models, year of manufacture, and color. With a MySQL dashboard builder , for example, you can connect all the data with a few clicks. Viescas, Douglas J.
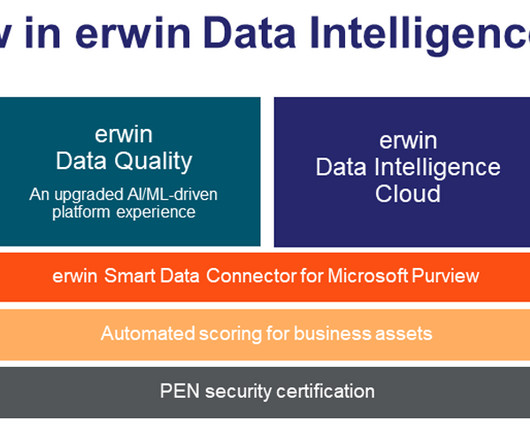
Added dataquality capability ready for an AI era Dataquality has never been more important than as we head into this next AI-focused era. erwin DataQuality is the dataquality heart of erwin Data Intelligence. erwin DataQuality is the dataquality heart of erwin Data Intelligence.
Over the past decade, deep learning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. Data must be laboriously collected, curated, and labeled with task-specific annotations to train AI models. We stand on the frontier of an AI revolution.
Business intelligence is moving away from the traditional engineering model: analysis, design, construction, testing, and implementation. In the traditional model communication between developers and business users is not a priority. You need to determine if you are going with an on-premise or cloud-hosted strategy.
Instead of installing software on your own servers, SaaS companies enable you to rent software that’s hosted, this is typically the case for a monthly or yearly subscription fee. More and more CRM, marketing, and finance-related tools use SaaS business intelligence and technology, and even Adobe’s Creative Suite has adopted the model.
Data governance is best defined as the strategic, ongoing and collaborative processes involved in managing data’s access, availability, usability, quality and security in line with established internal policies and relevant data regulations. Click here to read our success story on how E.ON
I recently participated in a web seminar on the Art and Science of FP&A Storytelling, hosted by the founder and CEO of FP&A Research Larysa Melnychuk along with other guests Pasquale della Puca , part of the global finance team at Beckman Coulter and Angelica Ancira , Global Digital Planning Lead at PepsiCo. The key takeaways.
Four-layered data lake and data warehouse architecture – The architecture comprises four layers, including the analytical layer, which houses purpose-built facts and dimension datasets that are hosted in Amazon Redshift. This enables data-driven decision-making across the organization.
So, we aggregated all this data, applied some machine learning algorithms on top of it and then fed it into large language models (LLMs) and now use generative AI (genAI), which gives us an output of these care plans. We created our datamodel in a way that satisfied the requirements of what we had a vision of.
Adam Wood, director of data governance and dataquality at a financial services institution (FSI). Sam Charrington, founder and host of the TWIML AI Podcast. Sam Charrington, founder and host of the TWIML AI Podcast. Common data governance challenges for global enterprises: Setting up a multidisciplinary data team.
Oracle Cloud Infrastructure is now capable of hosting a full range of traditional and modern IT workloads, and for many enterprise customers, Oracle is a proven vendor,” says David Wright, vice president of research for cloud infrastructure strategies at research firm Gartner. The inherent risk is trust.
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines.
Companies still often accept the risk of using internal data when exploring large language models (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AI development cycle, data ingestion serves as the entry point.
Last time , we discussed the steps that a modeler must pay attention to when building out ML models to be utilized within the financial institution. In summary, to ensure that they have built a robust model, modelers must make certain that they have designed the model in a way that is backed by research and industry-adopted practices.
We recently hosted a roundtable focused on o ptimizing risk and exposure management with data insights. Across the industry, the pandemic caused a huge breakdown in model performance due to the change in macroeconomic conditions and government stimulus packages. Mental health of employees is a critical area to monitor .
The mission also sets forward a target of 50% of high-priority dataquality issues to be resolved within a period defined by a cross-government framework. These systems will also be hosted – or are planned to be hosted – in appropriate environments aligned to the cross-government cloud and technology infrastructure strategy.
However, getting into the more difficult types of implementations — the fine-tuned models, vector databases to provide context and up-to-date information to the AI systems, and APIs to integrate gen AI into workflows — is where problems might crop up. That’s fine, but language models are great for language. They need stability.
It’s embedded in the applications we use every day and the security model overall is pretty airtight. Microsoft has also made investments beyond OpenAI, for example in Mistral and Meta’s LLAMA models, in its own small language models like Phi, and by partnering with providers like Cohere, Hugging Face, and Nvidia. That’s risky.”
If you’re part of a growing SaaS company and are looking to accelerate your success, leveraging the power of data is the way to gain a real competitive edge. A SaaS dashboard is a powerful business intelligence tool that offers a host of benefits for ambitious tech businesses. That’s where SaaS dashboards enter the fold.
National Grid is a big Microsoft Azure cloud customer due to its secure, proprietary nature, says Karaboutis, and is using a bevy of leading-edge tools, from Snowflake, Azure, and Matallion ETL for data tooling, Informatica for dataquality, Reltio for master data management, and Blue Prism for RPA, to name a few.
HPC5’s performance level enables sophisticated in-house algorithms to process subsoil data, as well as geophysical and seismic information from around the world. For optimizing existing resources, Eni uses HPC5 to model, study, and ultimately improve refinement operations. .
It culminates with a capstone project that requires creating a machine learning model. Data Science Dojo. Due to the short nature of the course, it’s tailored to those already in the industry who want to learn more about data science or brush up on the latest skills. Switchup rating: 5.0 (out Cost: $1,099.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content