This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. The post Use a Load Balancer on Google Cloud to Host Web Applications appeared first on Analytics Vidhya. Introduction What is a Load Balancer, and why do we need it? Load Balancer is a must component when we want to scale our systems horizontally.
This article was published as a part of the DataScience Blogathon. The post End-to-End Guide for Hosting a NodeJS App appeared first on Analytics Vidhya. Introduction on NodeJS App Importance of Software Deployment Software Deployment is the process of running the application on the server.
I am sure, by now, some of you must be interested to make a transition into the DataScience industry as it’s one of the most host-selling jobs (if we can put it that way :D). The post The DataHour: How to Transition into DataScience? So, this DataHour session is dedicated […].
This article was published as a part of the DataScience Blogathon. Introduction on EC2 In this article, we will learn how to host a dynamic website using an EC2 instance. Many will create a dynamic website and will confuse about where to host it and how to host it. In this article, I will help […].
By gaining the ability to understand, quantify, and leverage the power of online data analysis to your advantage, you will gain a wealth of invaluable insights that will help your business flourish. The ever-evolving, ever-expanding discipline of datascience is relevant to almost every sector or industry imaginable – on a global scale.
This article was published as a part of the DataScience Blogathon. It was sponsored by Google Developers and hosted on Kaggle. The data was collected from people that filled out an app form. The post How I Won My First Public DataScience Competition? Research has proven that early detection of […].
Over the years new alternative providers have risen to provided a solitary datascience environment hosted on the cloud for data scientist to analyze, host and share their work.
This article was published as a part of the DataScience Blogathon. Introduction on Machine Learning Last month, I participated in a Machine learning approach Hackathon hosted on Analytics Vidhya’s Datahack platform. In this article, I will […].
This article was published as a part of the DataScience Blogathon. Introduction on Compute Engine Compute Engine is computing and hosting service that lets you create and run virtual machines on Google infrastructure.
Introduction Statistics is a cornerstone of datascience, machine learning, and many analytical domains. Mastering it can significantly enhance your ability to interpret data and make informed decisions. GitHub hosts numerous repositories that are excellent resources for anyone looking to deepen their statistical knowledge.
Introduction With regard to educating its community about datascience, Analytics Vidhya has long been at the forefront. We periodically hold “DataHour” events to increase community interest in studying datascience. Here is the knowledge session by Shanthababu Pandian […].
Introduction With the world of datascience constantly evolving, it is important to stay up-to-date with the latest trends and techniques for aspiring and established professionals alike.
Introduction In a continually disruptive space of datascience, life sciences, and analytics, staying abreast with the newest trends and happenings in the industry is vital. In an endeavour to keep the audiences engaged and updated, Fractal hosts a series of podcasts frequently with the mavericks of the datascience industry.
This article was published as a part of the DataScience Blogathon. Introduction Textual data from social media posts, customer feedback, and reviews are valuable resources for any business. There is a host of useful information in such unstructured data that we can discover.
How can you showcase your data scientist skills and abilities? The answer to this question is online platforms where you can publish your portfolio and seize opportunities.
This article was published as a part of the DataScience Blogathon. DynamoDB is a scalable hosted NoSQL database service that offers low latency and key-value pair databases. Source: Link Introduction In this article, we are going to talk about a dynamo DB a No-SQL, and a very highly scalable database provided by Amazon AWS.
If you are a Data Scientist or Big Data Engineer, you probably find the DataScience environment configuration painful. If this is your case, you should consider using Docker for your day-to-day Data tasks. In this post, we will see how Docker can create a meaningful impact in your DataScience project.
This article was published as a part of the DataScience Blogathon Recently I participated in an NLP hackathon — “Topic Modeling for Research Articles 2.0”. This hackathon was hosted by the Analytics Vidhya platform as a part of their HackLive initiative.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Colaboratory, or “Colab” for short, are Jupyter Notebooks hosted by. The post 10 Colab Tips and Hacks for Efficient use of it appeared first on Analytics Vidhya.
Piperr.io — Pre-built data pipelines across enterprise stakeholders, from IT to analytics, tech, datascience and LoBs. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs data workflows. Genie — Distributed big data orchestration service by Netflix.
The proposed model illustrates the data management practice through five functional pillars: Data platform; data engineering; analytics and reporting; datascience and AI; and data governance. The higher the criticality and sensitivity to data downtime, the more engineering and automation are needed.
You should learn what a big data career looks like , which involves knowing the differences between different data processes. Online courses and universities are offering a growing number of programs of study that center around the datascience specialty. What is DataScience? Where to Use DataScience?
An education in datascience can help you land a job as a data analyst , data engineer , data architect , or data scientist. Here are the top 15 datascience boot camps to help you launch a career in datascience, according to reviews and data collected from Switchup.
What is datascience? Datascience is analyzing and predicting data, It is an emerging field. Some of the applications of datascience are driverless cars, gaming AI, movie recommendations, and shopping recommendations. These data models predict outcomes of new data. Where to start?
In this Banana Data Podcast episode " Methodology & Functionality in Differing DataScience Roles," our hosts share the rundown on datascience roles, so you will no longer be in the dark for behind the scenes datascience happenings.
Here is the latest datascience news for May 2019. From DataScience 101. REAL TALK WITH A DATA SCIENTIST: THE FUTURE OF DATA WRANGLING WHAT IS ON THE MICROSOFT DATASCIENCE CERTIFICATION EXAM? General DataScience. Not all are datascience/AI related, but many are.
I recently had the opportunity to sit down with Tom Raftery , host of the SAP Industry Insights Podcast (among others!) Let me ask you another question: what did you enjoy most about hosting these episodes? to discuss some of the highlights and common themes in last year’s episodes. Episode 42: The Future of Sustainable Shopping.
Anaconda is incredibly excited to announce the release of a brand-new suite of products on the Anaconda Nucleus platform: Anaconda Notebooks and Anaconda Learning.
These earnings offset the costs of hosting this website. Being Human in the Age of Artificial Intelligence” “An Introduction to Statistical Learning: with Applications in R” (7th printing; 2017 edition).
Welcome to the Banana Data Podcast ! We're a datascience podcast hosted by Dataiku with a goal to demystify and democratize all things within the datascience and AI ecosystem.
In this episode of the Banana Data Podcast, our hosts are joined by Nathan Mannheimer (Director of DataScience and ML at Tableau) as they unriddle the value of data visualization, explore what can go right and what can go wrong, and search for an answer to inquiries surrounding the future of data visualization.
Here are this week’s news and announcements related to Cloud DataScience. Google is launching Explainable AI which quantifies the impact of the various factors of the data as well as the existing limitations. Plus, there are some links for Videos and Tutorials. Announcements. Black box solutions are not always ok.
Data debt that undermines decision-making In Digital Trailblazer , I share a story of a private company that reported a profitable year to the board, only to return after the holiday to find that data quality issues and calculation mistakes turned it into an unprofitable one.
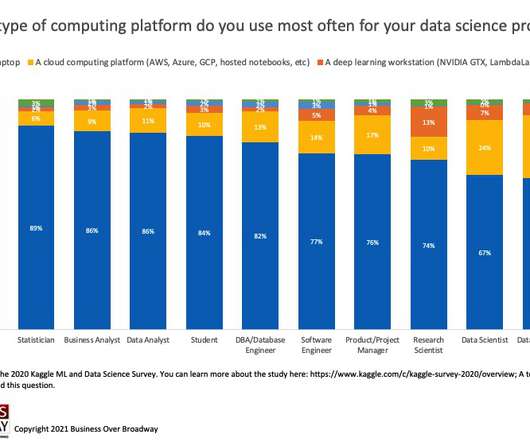
Results of a worldwide survey reveal that data professionals overwhelmingly use a personal computer or laptop as their computing platform most often for their datascience projects. The practice of datascience requires a variety of different tools and technologies to extract value from data.
This week Amazon hosted the large AWS re:Invent Conference. Netflix and AWS open source Metaflow Making it easy to build and manage real-life datascience projects. If you would like to get the Cloud DataScience News as an email, you can sign up for the Cloud DataScience Newsletter. Announcements.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
Given the end-to-end nature of many data products and applications, sustaining ML and AI requires a host of tools and processes, ranging from collecting, cleaning, and harmonizing data, understanding what data is available and who has access to it, being able to trace changes made to data as it travels across a pipeline, and many other components.
Data Drift Monitoring for Azure ML Datasets Azure ML now provides monitoring for when your data changes (called data drift). Upcoming Online ML/AI Conference, AWS Innovate A free, online conference hosted by Amazon Web Services. It focuses on using AWS products to solve datascience problems.
The DataScience for Social Good Summer Fellowship , now hosted at Carnegie Mellon University, is accepting applications. This is a 12-week program to train data scientists about working on projects which positively impact society. There are a number of roles available. Fellows Mentors Project Managers.
They recognize the instrumental role data plays in creating value and see information as the lifeblood of the organization. The business intelligence (BI) and datascience industries have spent the last couple decades making data access easier, analytic capability more comprehensive, and platforms more scalable.
awsAccessKey=s3-spark-user/HOST@REALM.COM. The post Apache Ozone Powers DataScience in CDP Private Cloud appeared first on Cloudera Blog. In a secure cluster, the following command is run to generate user specific credentials as any authenticated user. root@ ~]# ozone s3 getsecret --om-service-id=ozone1. import boto3.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content