This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Manish Limaye Pillar #1: Data platform The data platform pillar comprises tools, frameworks and processing and hosting technologies that enable an organization to process large volumes of data, both in batch and streaming modes. The choice of vendors should align with the broader cloud or on-premises strategy.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises. The downside here is over-provisioning.
The world’s an eventful place, isn’t it? When we say ‘eventful’, we mean, there are some many things happening around the world, every day, every minute, and they are all happening as glamorous, lavish and big events – be it a phone launch, a mega concert, fairs and so on. Who’s coming?
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Document the entire disaster recovery process.
You will load the eventdata from the SFTP site, join it to the venue data stored on Amazon S3, apply transformations, and store the data in Amazon S3. The event and venue files are from the TICKIT dataset. Access to an SFTP server with permissions to upload and download data. Choose Store a new secret.
The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. AWS DMS tasks are orchestrated using AWS Step Functions.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
Zero-ETL will perform an initial full load of your collection by doing a collection scan on the primary instance of your Amazon DocumentDB cluster, which may take several minutes to complete depending on the size of the data, and you may notice elevated resource consumption on your cluster. For example, inventory.product.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. By treating the data as a product, the outcome is a reusable asset that outlives a project and meets the needs of the enterprise consumer.
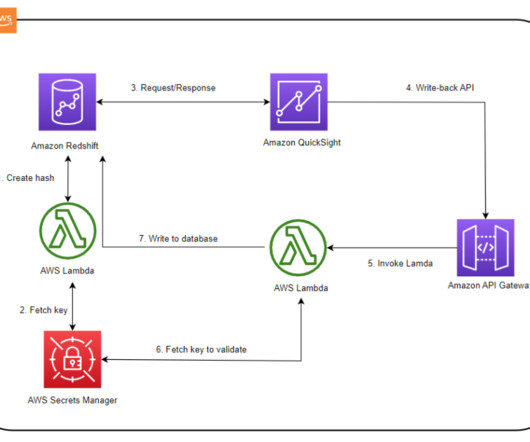
A write-back is the ability to update a data mart, datawarehouse, or any other database backend from within BI dashboards and analyze the updated data in near-real time within the dashboard itself. AnyCompany currently uses Amazon Redshift as their enterprise datawarehouse platform and QuickSight as their BI solution.
Complex mathematical algorithms are used to segment data and estimate the likelihood of subsequent events. Every Data Scientist needs to know Data Mining as well, but about this moment we will talk a bit later. Where to Use Data Science? It hosts a data analysis competition. Practical experience.
All the logic is still in Java hosted on Amazon’s infrastructure.” Aside from the core cloud services, Choice also uses Amazon RedShift as a front end to its cloud datawarehouse, Amazon SageMaker to build machine leaning models, and Amazon Kinesis to collect, process, and analyze real-time data.
Another hypothesis: Databricks execs were billion-dollar stoked to stick it to Snowflake by drowning out its event with a buyout its rival reportedly sought. There’s a record of everything – including metadata changes – which paves the way for a host of management and governance capabilities.
We like to call Dave one of our “angels” because he truly does work really hard to connect us with potential customers, is a great ally of ours, and always shows up for events that we host in our office. What has impressed you the most about Juice or its team? Tough question, because there is much to admire, enjoy and soak up.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You can get faster insights without spending valuable time managing your datawarehouse. Fault tolerance is built in.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Amazon EventBridge Used as a mechanism to capture Amazon DataZone events and trigger solution’s corresponding workflow.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
This includes: Supporting Snowflake External OAuth configuration Leveraging Snowpark for exploratory data analysis with DataRobot-hosted Notebooks and model scoring. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment. We recently announced DataRobot’s new Hosted Notebooks capability.
Scaling serverless data processing with Amazon Kinesis and Apache Kafka: Explore how to build scalable data processing applications using AWS Lambda. Learn practical insights into integrating Lambda with Amazon Kinesis and Apache Kafka using their event-driven models for real-time data streaming and processing.
Before we dive in, we recommend reviewing Architectural patterns for real-time analytics using Amazon Kinesis Data Streams, part 1 for the basic functionalities of Kinesis Data Streams. Part 1 also contains architectural examples for building real-time applications for time series data and event-sourcing microservices.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
You can subscribe to data products that help enrich customer profiles, for example demographics data, advertising data, and financial markets data. Amazon Kinesis ingests streaming events in real time from point-of-sales systems, clickstream data from mobile apps and websites, and social media data.
In short, CDP Private Cloud is a game-changer for Cloudera partners as it provides opportunities to help their customers modernize their data platform by breaking up monolithic architectures without leaving their data centers! . Be on the lookout for events around CDP Private Cloud enablement sessions.
insightsoftware’s Excelapalooza, one of the largest Microsoft Excel learning events in the country, is no exception. Who: insightsoftware, now including Jet Global reporting and analytics, is hosting the event for any and all business professionals who use Excel, Jet, Microsoft Dynamics, Epicor, Sage, or any other ERP system.
Given the prohibitive cost of scaling it, in addition to the new business focus on data science and the need to leverage public cloud services to support future growth and capability roadmap, SMG decided to migrate from the legacy datawarehouse to Cloudera’s solution using Hive LLAP. The case for a new DataWarehouse?
Third-party applications may store and process sensitive company information, which could be exposed in the event of a data breach or unauthorized access. Enterprise hosted LLMs Ensure Data Privacy One option to ensure data privacy is to use enterprise developed and hosted LLMs in the applications.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
It’s clear today that the datawarehouse industry is undergoing a major transformation. We’ll be hosting a live event on January 10, at 10AM Pacific, 1PM Eastern, to share more details on how the new Cloudera will accelerate innovation and deliver the industry’s first Enterprise Data Cloud. We intend to win.
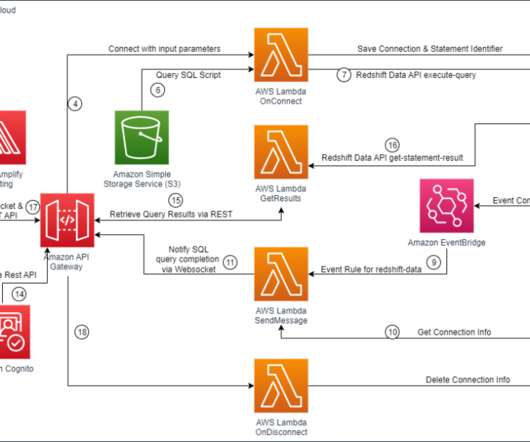
In this post, you will learn how to build a serverless analytics application using Amazon Redshift Data API and Amazon API Gateway WebSocket and REST APIs. The Data API simplifies access to Amazon Redshift because you don’t need to configure drivers and manage database connections. What are WebSockets and why do we need them?
Cloud data lakehouses provide significant scaling, agility, and cost advantages compared to cloud data lakes and cloud datawarehouses. They combine the best of both worlds: flexibility, cost effectiveness of data lakes and performance, and reliability of datawarehouses.”. Host-based security.
The list of challenges is long: cloud attack surface sprawl, complex application environments, information overload from disparate tools, noise from false positives and low-risk events, just to name a few. You get near real-time visibility and insights from your ingested data.
I want to thank you all for joining and attending these events! I received hundreds of questions during these events, and my colleagues and I tried to answer as many as we could. NiFi should be seen as the gateway to move data back and forth between heterogeneous environments or in a hybrid cloud architecture.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. This is due to the technical nature of a data system itself.
Recently, Confluent hosted Current 2023 (formerly Kafka summit) in San Jose on Sept 26th and 27th. With few conferences curating content specific to streaming developers, Current has historically been an important event for anyone trying to keep a pulse on what’s happening in the streaming space.
Along with a host of new features and capabilities, we are improving the upgrade process to be as painless as possible. release and the new in-place upgrade from HDP that completely does away with replacing infrastructure and data migrations. Hive Warehouse Connector (HWC) makes data engineering simpler and faster.
Thousands of customers rely on Amazon Redshift to build datawarehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Data loading is one of the key aspects of maintaining a datawarehouse.
Datawarehouses have become intensely important in the modern business world. For many organizations, it’s not uncommon for all their data to be extracted, loaded unchanged into datawarehouses, and then transformed via cleaning, merging, aggregation, etc. OLTP does not hold historical data, only current data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content