This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. Cloud based solutions are the future of the data warehousing market.
With a MySQL dashboard builder , for example, you can connect all the data with a few clicks. A host of notable brands and retailers with colossal inventories and multiple site pages use SQL to enhance their site’s structure functionality and MySQL reporting processes. It is a must-read for understanding datawarehouse design.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a datawarehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Where to Use Data Science? Data Science is used in different areas of our life and can help companies to deal with the following situations: Using predictive analytics to prevent fraud Using machinelearning to streamline marketing practices Using data analytics to create more effective actuarial processes.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. He has over 19 years of experience architecting, building, leading, and maintaining big data platforms.
While data science and machinelearning are related, they are very different fields. In a nutshell, data science brings structure to big data while machinelearning focuses on learning from the data itself. What is data science? What is machinelearning?
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. The producer account will host the EMR cluster and S3 buckets.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. Modern analytics is much wider than SQL-based data warehousing. You can isolate workloads using data sharing, while using the same underlying datasets.
All data is held in a lake-centric hub, and protected by a strong, universal security model, with data loss prevention and protection for sensitive data, and features for auditing and forensic investigation already built-in.
So, we aggregated all this data, applied some machinelearning algorithms on top of it and then fed it into large language models (LLMs) and now use generative AI (genAI), which gives us an output of these care plans. We had a kind of small datawarehouse on-prem. But the biggest point is data governance.
Four-layered data lake and datawarehouse architecture – The architecture comprises four layers, including the analytical layer, which houses purpose-built facts and dimension datasets that are hosted in Amazon Redshift. This enables data-driven decision-making across the organization.
Providing a comprehensive set of diverse analytical frameworks for different use cases across the data lifecycle (data streaming, data engineering, data warehousing, operational database and machinelearning) while at the same time seamlessly integrating data content via the Shared Data Experience (SDX), a layer that separates compute and storage.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Because Gilead is expanding into biologics and large molecule therapies, and has an ambitious goal of launching 10 innovative therapies by 2030, there is heavy emphasis on using data with AI and machinelearning (ML) to accelerate the drug discovery pipeline. You pay only for the compute resources and storage that you use.
Improved employee satisfaction: Providing business users access to data without having to contact analysts or IT can reduce friction, increase productivity, and facilitate faster results. Whereas BI studies historical data to guide business decision-making, business analytics is about looking forward.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machinelearning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as datawarehouses to multi-format data stores like data lakes. Langchain) and LLM evaluations (e.g.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. Choose Store a new secret.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. By treating the data as a product, the outcome is a reusable asset that outlives a project and meets the needs of the enterprise consumer.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machinelearning models, and locked ROI. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment.
Network operating systems let computers communicate with each other; and data storage grew—a 5MB hard drive was considered limitless in 1983 (when compared to a magnetic drum with memory capacity of 10 kB from the 1960s). The amount of data being collected grew, and the first datawarehouses were developed.
On the flip side, if you enjoy diving deep into the technical side of things, with the right mix of skills for business intelligence you can work a host of incredibly interesting problems that will keep you in flow for hours on end. This could involve anything from learning SQL to buying some textbooks on datawarehouses.
Our pre-merger customer bases have very little overlap, giving us a considerable enterprise installed base whose demand for IoT, analytics, data warehousing, and machinelearning continues to grow. It’s clear today that the datawarehouse industry is undergoing a major transformation. We intend to win.
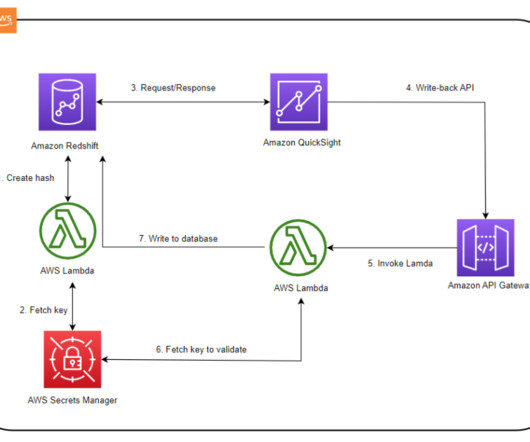
A write-back is the ability to update a data mart, datawarehouse, or any other database backend from within BI dashboards and analyze the updated data in near-real time within the dashboard itself. AnyCompany currently uses Amazon Redshift as their enterprise datawarehouse platform and QuickSight as their BI solution.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. The architecture illustrates how the solution works in a multi-account environment, which is a common scenario.
In legacy analytical systems such as enterprise datawarehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Introduction. public, private, hybrid cloud)?
However, as data processing at scale solutions grow, organizations need to build more and more features on top of their data lakes. Additionally, the task of maintaining and managing files in the data lake can be tedious and sometimes complex. Data can be organized into three different zones, as shown in the following figure.
In today’s data-driven landscape, the quality of data is the foundation upon which the success of organizations and innovations stands. High-quality data is not just about accuracy; it’s also about timeliness. You’ll learn the “why” behind the solution and see it come to life—complete with the inevitable errors.
In short, CDP Private Cloud is a game-changer for Cloudera partners as it provides opportunities to help their customers modernize their data platform by breaking up monolithic architectures without leaving their data centers! . Over a third of these Enterprises are actively executing on a strategy to move to hybrid IT.
We’ve also started experimenting with specific cloud services that focus on artificial intelligence (AI) and machinelearning – from traditional optimisation models published as bespoke intelligent services to proprietary intelligent services in the form of chatbots, text, voice and image processing. Who did you involve and why?
We took a pre-upgrade downtime in production to accomplish some of the prerequisite tasks like database upgrade and operating system upgrades on our master hosts. That downtime also allowed us to test the disaster recovery environment that our 24×7 users would interact with during the production upgrade.
An example would be asking about the price of CDW (Cloudera DataWarehouse), as the language model doesn’t have access to the enterprise price list and standard discount rates the answer will probably provide the typical rates for a collision damage waiver (also abbreviated as CDW), the answer will be factual but out of context.
Doesn’t this seem like a worthy goal for machinelearning—to make the machineslearn to work more effectively? pointed out in “ The Case for Learned Index Structures ” (see video ) the internal smarts (B-trees, etc.) of relational databases represent early forms of machinelearning. With me so far?
CDP Public Cloud leverages the elastic nature of the cloud hosting model to align spend on Cloudera subscription (measured in Cloudera Consumption Units or CCUs) with actual usage of the platform. MachineLearning Prototypes. Experience configuration / use case deployment: At the data lifecycle experience level (e.g.,
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content