This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Digital transformation started creating a digital presence of everything we do in our lives, and artificial intelligence (AI) and machine learning (ML) advancements in the past decade dramatically altered the data landscape. The choice of vendors should align with the broader cloud or on-premises strategy.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Meta-Orchestration . Production Monitoring Only.
To extract the maximum value from your data, it needs to be accessible, well-sorted, and easy to manipulate and store. Amazon’s Redshift datawarehouse tools offer such a blend of features, but even so, it’s important to understand what it brings to the table before making a decision to integrate the system.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Data store – The data store used a custom datamodel that had been highly optimized to meet low-latency query response requirements.
Some of these ‘structures’ may include putting all the information; for instance, a structure could be about cars, placing them into tables that consist of makes, models, year of manufacture, and color. With a MySQL dashboard builder , for example, you can connect all the data with a few clicks. Viescas, Douglas J.
Analytics as a service (AaaS) is a business model that uses the cloud to deliver analytic capabilities on a subscription basis. This model provides organizations with a cost-effective, scalable, and flexible solution for building analytics. times better price-performance than other cloud datawarehouses.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a datawarehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
For more information, refer SQL models. Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your datawarehouse using the dbt seed command. In an optimal environment, we store the credentials in AWS Secrets Manager and retrieve them.
With more people becoming digital citizens, the ability for an application to explode in popularity has all but rendered obsolete the traditional IT hosting mindset of discrete servers performing discrete tasks. Let’s dig into three hostingmodels that help organizations achieve cloud flexibility.
In this regard, the enterprise data product catalog acts as a federated portal, facilitating cross-domain access and interoperability while maintaining alignment with governance principles. This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ.
It’s following in the footsteps of IBM and Microsoft, which like the German telco have an edge over regular companies contemplating a similar move to Rise in that they have their own clouds in which to host the applications and their own IT services divisions to make the move. Some of them are still running on ECC 6.0,
Recent research by McGuide Research Services for Avanade found 91% of organisations in the sector believe they need to shift to an AI-first operating model within the next 12 months, while 87% of employees feel generative AI tools will make them more efficient, and more innovative.
Improved employee satisfaction: Providing business users access to data without having to contact analysts or IT can reduce friction, increase productivity, and facilitate faster results. Whereas BI studies historical data to guide business decision-making, business analytics is about looking forward.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Every aspect of analytics is powered by a datamodel. A datamodel presents a “single source of truth” that all analytics queries are based on, from internal reports and insights embedded into applications to the data underlying AI algorithms and much more. Datamodeling organizes and transforms data.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Data Mining Techniques and Data Visualization. Data Mining is an important research process. It hosts a data analysis competition. Practical experience. It is not very interesting to be engaged exclusively in theory, it is important to try your hand at practice. Here are some good options for doing this.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You can get faster insights without spending valuable time managing your datawarehouse. Fault tolerance is built in.
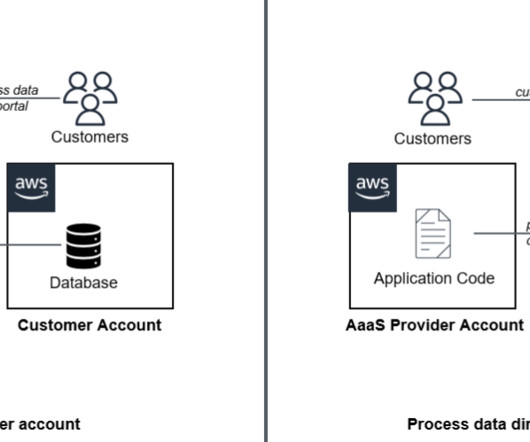
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. The producer account will host the EMR cluster and S3 buckets.
The formats are basically abstraction layers that give business analysts and data scientists the ability to mix and match whatever data stores they need, wherever they may lie, with whatever processing engine they choose. The data itself remains intact, uncopied and unaltered. And the table formats will keep track of all of it.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
All the logic is still in Java hosted on Amazon’s infrastructure.” Aside from the core cloud services, Choice also uses Amazon RedShift as a front end to its cloud datawarehouse, Amazon SageMaker to build machine leaning models, and Amazon Kinesis to collect, process, and analyze real-time data.
So, we aggregated all this data, applied some machine learning algorithms on top of it and then fed it into large language models (LLMs) and now use generative AI (genAI), which gives us an output of these care plans. We had a kind of small datawarehouse on-prem. But the biggest point is data governance.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as datawarehouses to multi-format data stores like data lakes. The image above demonstrates a KMS built using the llama3 model from Meta.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
That benefit comes from the breadth of CDP’s analytical capabilities that translates into a unique ability to migrate different big data workloads, either from previous versions of CDH / HDP or from other cloud datawarehouses and legacy on-premises datawarehouses that the acquired entity might be using.
In legacy analytical systems such as enterprise datawarehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. public, private, hybrid cloud)?
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
Moving to a cloud-only based model allows for flexible provisioning, but the costs accrued for that strategy rapidly negate the advantage of flexibility. . Cloud deployments for suitable workloads gives you the agility to keep pace with rapidly changing business and data needs. A solution. One cluster contains about 800 nodes.
On the flip side, if you enjoy diving deep into the technical side of things, with the right mix of skills for business intelligence you can work a host of incredibly interesting problems that will keep you in flow for hours on end. This could involve anything from learning SQL to buying some textbooks on datawarehouses.
In our previous blog post we introduced Cloudera Data Visualization in Cloudera DataWarehouse (CDW) available in tech preview, in CDP Public Cloud. This blog will help you get started with Cloudera Data Visualization, so you can start building interesting and powerful applications on all types of data.
They enable transactions on top of data lakes and can simplify data storage, management, ingestion, and processing. These transactional data lakes combine features from both the data lake and the datawarehouse. Data can be organized into three different zones, as shown in the following figure.
As the first of its reasons why to migrate to Redshift , Amazon says, “Amazon Redshift is fully managed and simple to use, enabling you to deploy a new datawarehouse in minutes and load virtually any type of data from a range of cloud or on-premises data sources.”. Setting up the datawarehouse can take minutes.
Modern approaches to insurance and changes in customer expectations mean that the insurance business model looks very different than it used to. This phase includes the migration of our datawarehouse and business intelligence capabilities, using Synapse and PowerBI respectively. Who did you involve and why?
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Network operating systems let computers communicate with each other; and data storage grew—a 5MB hard drive was considered limitless in 1983 (when compared to a magnetic drum with memory capacity of 10 kB from the 1960s). The amount of data being collected grew, and the first datawarehouses were developed.
As described in our recent blog post , an SQL AI Assistant has been integrated into Hue with the capability to leverage the power of large language models (LLMs) for a number of SQL tasks. This is a real game-changer for data analysts on all levels and will make SQL development faster, easier, and less error-prone.
But more importantly, from a business and strategic viewpoint, it means that casinos are capturing consumer data into datawarehouses, at different points inside the casino – the same data that is crucial for a host of purposes. These systems are amassing information into independent datawarehouses.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content