This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises. The downside here is over-provisioning.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and data lake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
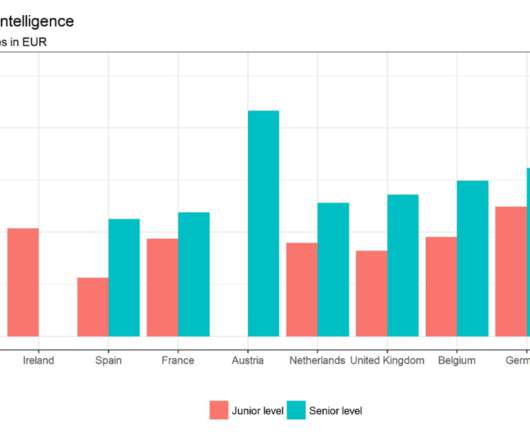
Business intelligence concepts refer to the usage of digital computing technologies in the form of datawarehouses, analytics and visualization with the aim of identifying and analyzing essential business-based data to generate new, actionable corporate insights. The datawarehouse. 1) The raw data.
With a MySQL dashboard builder , for example, you can connect all the data with a few clicks. A host of notable brands and retailers with colossal inventories and multiple site pages use SQL to enhance their site’s structure functionality and MySQL reporting processes. Would highly recommend for SQL experts.”.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
For more information, refer SQL models. Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your datawarehouse using the dbt seed command. During the run, dbt creates a Directed Acyclic Graph (DAG) based on the internal reference between the dbt components.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. For additional details, refer to Automated snapshots.
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud datawarehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift RA3 with managed storage is the newest instance type for Provisioned clusters.
This will be used temporarily to hold the data from Amazon DocumentDB for data synchronization. OpenSearch hosts – Provide the OpenSearch Service domain endpoint for the host and provide the preferred index name to store the data. He has worked with building databases and datawarehouse solutions for over 15 years.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. Refer to IAM Identity Center identity source tutorials for the IdP setup. IAM Identity Center enabled.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. For instructions, refer to create key-pair here.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. The producer account will host the EMR cluster and S3 buckets.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You can get faster insights without spending valuable time managing your datawarehouse. Fault tolerance is built in.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Airflow that you can use to set up and operate data pipelines in the cloud at scale. Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
The currently available choices include: The Amazon Redshift COPY command can load data from Amazon Simple Storage Service (Amazon S3), Amazon EMR , Amazon DynamoDB , or remote hosts over SSH. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal datawarehouse configuration to support their Amazon Redshift workloads. For guidance, refer to the Authoring and running notebooks.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management?
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. If you’d like to learn more about other workflows in this solution, please refer to the implementation guide.
BI tools access and analyze data sets and present analytical findings in reports, summaries, dashboards, graphs, charts, and maps to provide users with detailed intelligence about the state of the business. Benefits of BI BI helps business decision-makers get the information they need to make informed decisions.
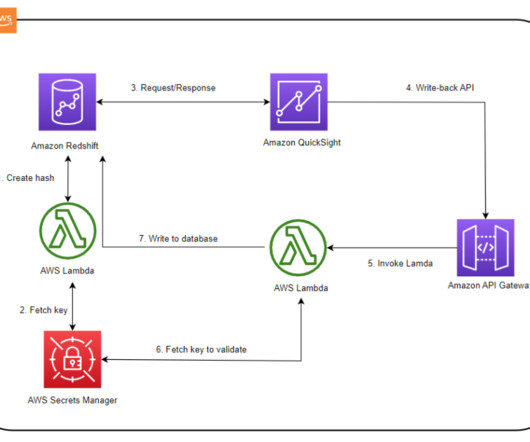
A write-back is the ability to update a data mart, datawarehouse, or any other database backend from within BI dashboards and analyze the updated data in near-real time within the dashboard itself. AnyCompany currently uses Amazon Redshift as their enterprise datawarehouse platform and QuickSight as their BI solution.
The ingested data gets transformed and analyzed in near real time using Amazon Managed Service for Apache Flink. Stream data can further be enriched using lookup datahosted in a datawarehouse such as Amazon Redshift. We will continue to add new architectural patterns in the future posts of this series.
Refer to How do I set up a NAT gateway for a private subnet in Amazon VPC? For more information, refer to Prerequisites. For more information, refer to Storing database credentials in AWS Secrets Manager. For instructions to set up AWS Cloud9, refer to Getting started: basic tutorials for AWS Cloud9. manylinux2014_x86_64.whl
Data lakes are not transactional by default; however, there are multiple open-source frameworks that enhance data lakes with ACID properties, providing a best of both worlds solution between transactional and non-transactional storage mechanisms. The referencedata is continuously replicated from MySQL to DynamoDB through AWS DMS.
Thousands of customers rely on Amazon Redshift to build datawarehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Data loading is one of the key aspects of maintaining a datawarehouse.
Can Amazon RDS for Db2 be used for running data warehousing workloads? Answer : Yes, Amazon RDS for Db2 can support analytics workloads, but it is not a datawarehouse. Amazon RDS Refer to the Amazon RDS for Db2 pricing page for instances supported. Scalability 5.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
On the flip side, if you enjoy diving deep into the technical side of things, with the right mix of skills for business intelligence you can work a host of incredibly interesting problems that will keep you in flow for hours on end. This could involve anything from learning SQL to buying some textbooks on datawarehouses.
The integration of Talend Cloud and Talend Stitch with Amazon Redshift Serverless can help you achieve successful business outcomes without datawarehouse infrastructure management. In this post, we demonstrate how Talend easily integrates with Redshift Serverless to help you accelerate and scale data analytics with trusted data.
Refer to the following cloudera blog to understand the full potential of Cloudera Data Engineering. . For further details on the API, please refer to the following doc link here. . New jobs are defined with references to the resource which automatically downloads the custom runtime image to run the spark drivers and executors.
Please refer to the product documentation for more information about specific releases. Supported AI models and services The SQL AI Assistant is not bundled with a specific LLM; instead it supports various LLMs and hosting services. Log in to the Cloudera DataWarehouse service as DWAdmin. or higher on the public cloud.
Amazon Redshift is a fast, scalable cloud datawarehouse built to serve workloads at any scale. This integration positions Amazon Redshift as an IAM Identity Center-managed application, enabling you to use database role-based access control on your datawarehouse for enhanced security. Tableau Server 2023.3.4
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. Thousands of customers use Amazon Redshift read data sharing to enable instant, granular, and fast data access across Redshift provisioned clusters and serverless workgroups.
It supports both data quality at rest and data quality in AWS Glue extract, transform, and load (ETL) pipelines. Data quality at rest focuses on validating the data stored in data lakes, databases, or datawarehouses. It ensures that the data meets specific quality standards before it is consumed.
It is prudent to consolidate this data into a single customer view, serving as a primary reference for downstream applications, ranging from ecommerce platforms to CRM systems. This consolidated view acts as a liaison between the data platform and customer-centric applications.
Apache Hive is a SQL-based datawarehouse system for processing highly distributed datasets on the Apache Hadoop platform. The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table.
Amazon Redshift and Tableau empower data analysis. Amazon Redshift is a cloud datawarehouse that processes complex queries at scale and with speed. Tableau’s extensive capabilities and enterprise connectivity help analysts efficiently prepare, explore, and share data insights company-wide. Open Tableau Desktop.
The Delta tables created by the EMR Serverless application are exposed through the AWS Glue Data Catalog and can be queried through Amazon Athena. Incremental data is generated in the PostgreSQL table by running custom SQL scripts. Let’s refer to this S3 bucket as the raw layer. with Apache Spark version 3.3.0)
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content