This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key concepts To understand the value of RFS and how it works, let’s look at a few key concepts in OpenSearch (and the same in Elasticsearch): OpenSearch index : An OpenSearch index is a logical container that stores and manages a collection of related documents. to OpenSearch 2.x),
For agent-based solutions, see the agent-specific documentation for integration with OpenSearch Ingestion, such as Using an OpenSearch Ingestion pipeline with Fluent Bit. This includes adding common fields to associate metadata with the indexed documents, as well as parsing the log data to make data more searchable.
Today, such an ML model can be easily replaced by an LLM that uses its world knowledge in conjunction with a good prompt for document categorization. Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata.
Select the Consumption hosting plan and then choose Select. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. In the Single sign-on section , under SAML Certificates , choose Download for Federation Metadata XML. Log in with your Azure account credentials.
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. We developed and host several applications for our customers on Amazon Web Services (AWS). The document processing layer supports document ingestion and orchestration.
For this use case, create a data source and import the technical metadata of four data assets— customers , order_items , orders , products , reviews , and shipments —from AWS Glue Data Catalog. Get started with our technical documentation. Ensure the data assets are enriched with business descriptions and published to the catalog.
The following diagram illustrates an indexing flow involving a metadata update in OR1 During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. In the event of an infrastructure failure, an OpenSearch domain can end up losing one or more nodes.
Migration of metadata such as security roles and dashboard objects will be covered in another subsequent post. Update the following information for the source: Uncomment hosts and specify the endpoint of the existing OpenSearch Service endpoint. For now, you can leave the default minimum as 1 and maximum as 4.
A greater ability to respond to compliance audits: Take the pain out of preparing reports and respond more quickly to audits with better documentation of data lineage. These include data catalog , data literacy and a host of built-in automation capabilities that take the pain out of data preparation.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. These processes could include reports, campaigns, or financial documentation. Accuracy should be measured through source documentation (i.e., 2 – Data profiling.
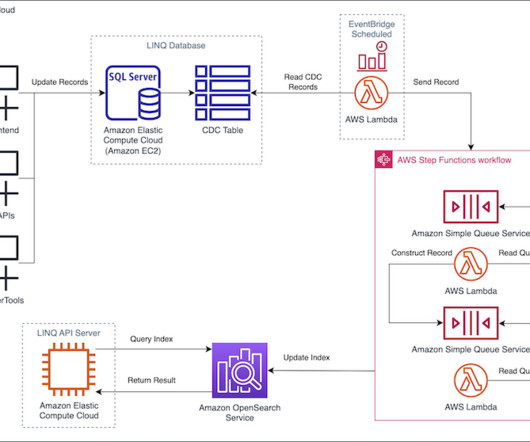
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
Create an Amazon Route 53 public hosted zone such as mydomain.com to be used for routing internet traffic to your domain. For instructions, refer to Creating a public hosted zone. Request an AWS Certificate Manager (ACM) public certificate for the hosted zone. hosted_zone_id – The Route 53 public hosted zone ID.
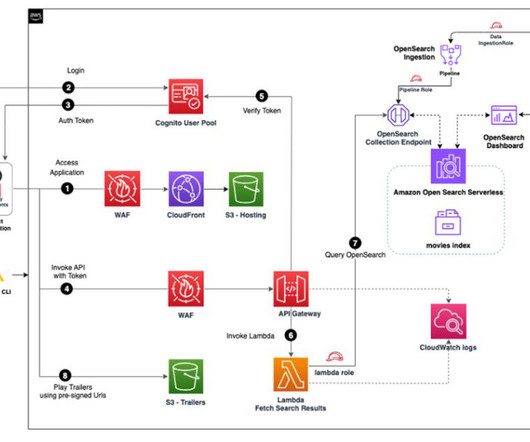
In this post, you use common methods for searching documents in OpenSearch Service that improve the search experience, such as request body searches using domain-specific language (DSL) for queries. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. The user signs in with their credentials.
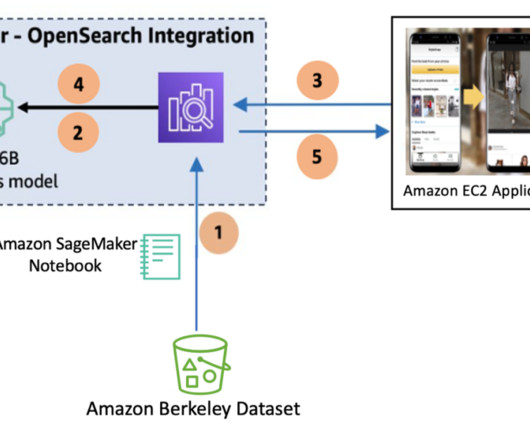
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. Text embeddings capture document semantics, while image embeddings capture visual attributes that help you build rich image search applications.
Before proceeding with the upgrade, review the CDP Private Cloud Base prerequisites as specified in the documentation. Finally we also recommend that you take a full backup of your cluster configurations, metadata, other supporting details, and backend databases. The end-to-end process is relatively straightforward and well documented.
Manually add objects and or links to represent metadata that wasn’t included in the extraction and document descriptions for user visualization. Download upper and column-to-column lineage to Excel/CSV in order to document, verify development and change requests. We call this feature: Expand. Column-to-column lineage.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. The query is run locally on each shard and matched documents are returned to the coordinator node.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. End-users often struggle to find relevant information buried within extensive documents housed in data lakes, leading to inefficiencies and missed opportunities.
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. Lexical search In lexical search, the search engine compares the words in the search query to the words in the documents, matching word for word.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). We have cataloging inside Datasphere: It allows you to catalog, manage metadata, all the SAP data assets we’re seeing,” said JG Chirapurath, chief marketing and solutions officer for SAP. “We
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
Further information and documentation [link] . All three will be quorums of Zookeepers and HDFS Journal nodes to track changes to HDFS Metadata stored on the Namenodes. CDP is particularly sensitive to host name resolution, therefore it’s vital that the DNS servers have been properly configured and hostnames are fully qualified.
Protecting what traditionally has been considered personally identifiable information (PII) — people’s names, addresses, government identification numbers and so forth — that a business collects, and hosts is just the beginning of GDPR mandates.
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
Additionally, Okera connects to a company’s existing technical and business metadata catalogs (such as Collibra), making it easy for data scientists to discover, access and utilize new, approved sources of information. For the compliance team, the combination of Okera and Domino Data Lab is extremely powerful.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI. For example, mw1.small
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. Common Crawl data The Common Crawl raw dataset includes three types of data files: raw webpage data (WARC), metadata (WAT), and text extraction (WET).
Next, let’s run a small “document” through the natural language parser: In [2]: text = "The rain in Spain falls mainly on the plain."? First we created a doc from the text, which is a container for a document and all of its annotations. Then we iterated through the document to see what spaCy had parsed.
To follow along with this post, you should have the following prerequisites: Three AWS accounts as follows: Source account: Hosts the source Amazon RDS for PostgreSQL database. Crawlers explore data stores and auto-generate metadata to populate the Data Catalog, registering discovered tables in the Data Catalog.
The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data. For detailed release documentation with sample code, visit the Apache Airflow v2.4.0 How dynamic task mapping works Let’s see an example using the reference code available in the Airflow documentation. Release Notes.
This feature lets users query AWS Glue databases and tables in one Region from another Region using resource links, without copying the metadata in the Data Catalog or the data in Amazon Simple Storage Service (Amazon S3). See the API documentation for GetTable() and GetDatabase( ) for additional details.
System metadata is reviewed and updated regularly. For the purposes of this document we are going to focus on the most secure level 3 security. Similarly, Cloudera Manager Auto TLS enables per host certificates to be generated and signed by established certificate authorities. Sensitive data is encrypted.
Download the Gartner® Market Guide for Active Metadata Management 1. Efficient cloud migrations McKinsey predicts that $8 out of every $10 for IT hosting will go toward the cloud by 2024. With data lineage, every object in the migrated system is mapped and dependencies are documented.
These traditional lexical search algorithms match user queries with exact words or phrases in your documents. After the scores are all on the same scale, they’re combined for every document. Reorder the documents based on the new combined score and render the documents as a response to the query.
Rajgopal adds that all customer data, metadata, and escalation data are kept on Indian soil at all times in an ironclad environment. For its part, Datacom has provided sovereign cloud solutions for over a decade in Australia and New Zealand to more than 50 government agencies.
Users access the CDF-PC service through the hosted CDP Control Plane. The CDP control plane hosts critical components of CDF-PC like the Catalog , the Dashboard and the ReadyFlow Gallery. This will create a JSON file containing the flow metadata. and later). Figure 3: Export a NiFi process group from an existing cluster.
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Encryption & Decryption Flow: The way HDFS encrypts data is explained very well in Cloudera documentation and many articles. Check entropy using the command : . $
The Replication Manager support matrix is documented in our public docs. While using CDH on-premises cluster or CDP Private Cloud Base cluster, make sure that the following ports are open and accessible on the source hosts to allow communication between the source on-premise cluster and CDP Data Lake cluster.
Instead of having a central team that manages all the data for a company, the thinking is that the responsibility of generating, curating, documenting, updating, and managing data should be distributed across the company based on whichever team is best suited to produce and own that data. Data mesh conceptual hierarchy. Miro: [link].
This can be done using the initiatePrint action: embeddedDashboard.initiatePrint(); The following code sample shows a loading animation, SDK code status, and dashboard interaction monitoring, along with initiating dashboard print from the application: Embedding demo $(document).ready(function()
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. 4 key components to ensure reliable data ingestion Data quality and governance: Data quality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
“Always the gatekeepers of much of the data necessary for ESG reporting, CIOs are finding that companies are even more dependent on them,” says Nancy Mentesana, ESG executive director at Labrador US, a global communications firm focused on corporate disclosure documents. The complexity is at a much higher level.”
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content