This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers. Counter claims?
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. For machine learning systems used in consumer internet companies, models are often continuously retrained many times a day using billions of entirely new input-output pairs.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. GitHub – A provider of Internet hosting for software development and version control using Git. Azure Repos – Unlimited, cloud-hosted private Git repos. .
EUROGATEs data science team aims to create machine learning models that integrate key data sources from various AWS accounts, allowing for training and deployment across different container terminals. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau.
Many companies whose AI model training infrastructure is not proximal to their data lake incur steeper costs as the data sets grow larger and AI models become more complex. The cloud is great for experimentation when data sets are smaller and model complexity is light. Potential headaches of DIY on-prem infrastructure.
The early bills for generative AI experimentation are coming in, and many CIOs are finding them more hefty than they’d like — some with only themselves to blame. According to IDC’s “ Generative AI Pricing Models: A Strategic Buying Guide ,” the pricing landscape for generative AI is complicated by “interdependencies across the tech stack.”
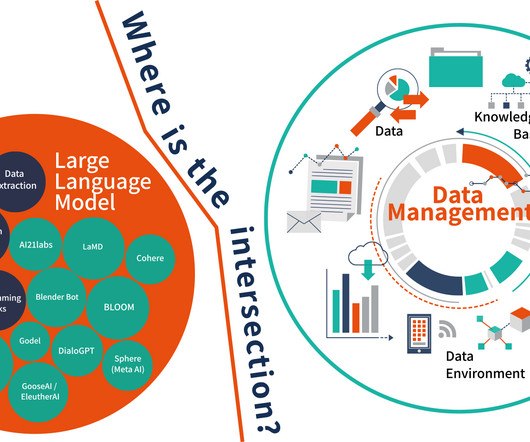
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and data management. But there are also a host of other issues (and cautions) to take into consideration. LLM is by its very design a language model. The technology is very new and not well understood.
Most, if not all, machine learning (ML) models in production today were born in notebooks before they were put into production. Data science teams of all sizes need a productive, collaborative method for rapid AI experimentation. A host of open-source libraries. Capabilities Beyond Classic Jupyter for End-to-end Experimentation.
Proof that even the most rigid of organizations are willing to explore generative AI arrived this week when the US Department of the Air Force (DAF) launched an experimental initiative aimed at Guardians, Airmen, civilian employees, and contractors. For now, AFRL is experimenting with self-hosted open-source LLMs in a controlled environment.
The AI data center pod will also be used to power MITRE’s federal AI sandbox and testbed experimentation with AI-enabled applications and large language models (LLMs). MITRE hosts monthly AI workshops with its employees to instruct on effective chat prompting and to help its employees understand the nuances of prompt engineering.
For example, consider a smaller website that is considering adding a video hosting feature to increase engagement on the site. Instead, we focus on the case where an experimenter has decided to run a full traffic ramp-up experiment and wants to use the data from all of the epochs in the analysis.
These same decision-makers identify a host of challenges in implementing generative AI, so chances are that a significant portion of use is “unsanctioned.” Generative AI models can perpetuate and amplify biases in training data when constructing output. Models can produce material that may infringe on copyrights.
It’s embedded in the applications we use every day and the security model overall is pretty airtight. Microsoft has also made investments beyond OpenAI, for example in Mistral and Meta’s LLAMA models, in its own small language models like Phi, and by partnering with providers like Cohere, Hugging Face, and Nvidia. That’s risky.”
Still, there is a steep divide between rogue and shadow IT, which came under discussion at a recent Coffee with Digital Trailblazers event I hosted. Without a strong delivery model and communication plan, frustrated business stakeholders are likelier to buy and try implementing a technology solution without IT’s involvement.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. We recently announced DataRobot’s new Hosted Notebooks capability. Learn more about DataRobot hosted notebooks.
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. We’re planning to have that fully hosted with us.
We’re introducing groundbreaking new features – including On-demand Spark clusters, enhanced project management, and the ability to export models – that give enterprises unprecedented power to scale their data science capabilities by addressing common struggles. I’m also proud to announce an exciting new product: Domino Model Monitor (DMM).
For the demo, we’re using the Amazon Titan foundation modelhosted on Amazon Bedrock for embeddings, with no fine tuning. If you are interested in exploring the multi-modal model, please reach out to your AWS specialist. With OpenSearch’s Search Comparison Tool , you can compare the different approaches.
It depends on what business model you’re in. A self-hosted infrastructure is time-intensive, demands specialized expertise, and comes with significant expenses.” Opting for a managed cloud offering allows organizations to focus on delivering business value and driving adoption,” he says. “A
IT’s mission has transformed — perhaps so should its brand Another approach I recommend is to rebrand IT and recast its mission to modernize its objectives, organizational structure, core competencies, and operating model. What comes first: A new brand or operating model?
In fact, it’s likely your organization has a large number of employees currently experimenting with generative AI, and as this activity moves from experimentation to real-life deployment, it’s important to be proactive before unintended consequences happen. This may include developing training videos and hosting live sessions.
release, we’ve made it easy for you to rapidly prepare data, engineer new features and subsequently automate model deployment and monitoring into your Snowflake data landscape, all with limited data movement. We’ve tightened the loop between ML data prep , experimentation and testing all the way through to putting models into production.
Riding the wave of the generative AI revolution, third party large language model (LLM) services like ChatGPT and Bard have swiftly emerged as the talk of the town, converting AI skeptics to evangelists and transforming the way we interact with technology. How can enterprises address these challenges?
The attack targeted a host of public and private sector organizations (18,000 customers) including NASA, the Justice Department, and Homeland Security, and it is believed the attackers persisted on SolarWinds systems for 14 months prior to discovery. Operationalize ML with the Cloudera Data Platform.
The impact of generative AIs, including ChatGPT and other large language models (LLMs), will be a significant transformation driver heading into 2024. Define a game-changing LLM strategy At a recent Coffee with Digital Trailblazers I hosted, we discussed how generative AI and LLMs will impact every industry.
And for those that do make it past the experimental stage, it typically takes over 18 months for the value to be realized. Accurate models today become inaccurate tomorrow. Models often degrade fast in production as they encounter unexpected conditions in the real world. Challenge to keep production models fair and ethical.
And the market for doing so remains robust for corporations looking to make the most of the model. For example, startups are likelier to have advanced devops practices that enable continuous deployments and feature experimentation. Large enterprises have a wealth of experience and industry knowledge that can be invaluable to startups.
Traditional lexical search, based on term frequency models like BM25, is widely used and effective for many search applications. Semantic search In semantic search, the search engine uses an ML model to encode text or other media (such as images and videos) from the source documents as a dense vector in a high-dimensional vector space.
Whether you are powering AI models or traditional information systems, you need foundational resources to implement and maintain. Software development and a host of other jobs will become vulnerable due to the latest tectonic shift: the growth of generative AI.” We still need the fundamentals.
With the rise of highly personalized online shopping, direct-to-consumer models, and delivery services, generative AI can help retailers further unlock a host of benefits that can improve customer care, talent transformation and the performance of their applications. trillion on retail businesses through 2029.
This service supports a range of optimized AI models, enabling seamless and scalable AI inference. By 2023, the focus shifted towards experimentation. Enterprise developers began exploring proof of concepts (POCs) for generative AI applications, leveraging API services and open models such as Llama 2 and Mistral.
This approach gives freedom to move its AI artifacts around, regardless of whether they are hosted on a major cloud platform or its own on-premise infrastructure. Machine learning operations (MLOps) solutions allow all models to be monitored from a central location, regardless of where they are hosted or deployed.
A packed keynote session showed how repeatable workflows and flexible technology get more models into production. Our in-booth theater attracted a crowd in Singapore with practical workshops, including Using AI & Time Series Models to Improve Demand Forecasting and a technical demonstration of the DataRobot AI Cloud platform.
Organizations that want to prove the value of AI by developing, deploying, and managing machine learning models at scale can now do so quickly using the DataRobot AI Platform on Microsoft Azure. Models trained in DataRobot can also be easily deployed to Azure Machine Learning, allowing users to hostmodels easier in a secure way.
COVID-19 required a worldwide coordinated response of medical professionals, data teams, logistics organizations, and a whole host of other experts to try to flatten the curve, improve treatments, and ultimately develop lasting remedies. The better option was to perform the model’s calculations only once the parameters were set.
The AWS pay-as-you-go model and the constant pace of innovation in data processing technologies enable CFM to maintain agility and facilitate a steady cadence of trials and experimentation. CFM data scientists then look up the data and build features that can be used in our trading models.
The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data. Removal of experimental Smart Sensors. The latter is only needed if it’s a different bucket than the Amazon MWAA bucket. The following diagram illustrates the solution architecture. Apache Airflow v2.4.3 Airflow v2.4.0
Who owns the power to make changes to the site (not who owns updating pages or hosting the site)? Which physical organizational model will work best for you? My organization redesign plans have recommended either one of the three models. If you are executing on a centralized model be aware of the pros and cons.
Artificial intelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deep learning models in a more scalable way. AI platforms assist with a multitude of tasks ranging from enforcing data governance to better workload distribution to the accelerated construction of machine learning models.
Paco Nathan ‘s latest article covers program synthesis, AutoPandas, model-driven data queries, and more. Using ML models to search more effectively brought the search space down to 102—which can run on modest hardware. Model-Driven Data Queries. Introduction. BTW, videos for Rev2 are up: [link]. That’s impressive.
This module is experimental and under active development and may have changes that aren’t backward compatible. This module provides higher-level constructs (specifically, Layer 2 constructs ), including convenience and helper methods, as well as sensible default values. cluster = aws_redshift_alpha.Cluster( scope, cluster_identifier, #.
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. Most experts categorize it as a powerful, but narrow AI model. A key trend is the adoption of multiple models in production.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. This duplication can become such a management nightmare that they may prefer to return to the original model and simply live with noisy neighbors. Cloudera Manager (CM) 6.2
As host of the DataRobot More Intelligent Tomorrow podcast , I’m constantly impressed and delighted by the fascinating people that I have a chance to talk to. There is a whole section of the Army that is focused on research and development and experimentation.”. The raw ingredients are rarely model-ready,” she says.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content