This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Install and configure the AWS CLI The AWS Command Line Interface (AWS CLI) is an open source tool that enables you to interact with AWS services using commands in your command line shell. For simplicity, we use the Hosting with Amplify Console and Manual Deployment options. All the resources are now deployed on AWS and ready for use.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight. The architecture is shown in the following figure.
GenAI as ubiquitous technology In the coming years, AI will evolve from an explicit, opaque tool with direct user interaction to a seamlessly integrated component in the feature set. Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata.
It allows organizations to secure data, perform searches, analyze logs, monitor applications in real time, and explore interactive log analytics. Launch an EC2 instance Note : Make sure to deploy the EC2 instance for hosting Jenkins in the same VPC as the OpenSearch domain. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com,
Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics. In such an event, the new instance family guarantees recovery of both the cluster metadata and the index data up to the latest acknowledged operation.
In this post, we show you how you can convert existing data in an Amazon S3 data lake in Apache Parquet format to Apache Iceberg format to support transactions on the data using Jupyter Notebook based interactive sessions over AWS Glue 4.0. AWS Command Line Interface (AWS CLI) configured to interact with AWS Services. Choose ETL Jobs.
To interact with and analyze data stored in Amazon Redshift, AWS provides the Amazon Redshift Query Editor V2 , a web-based tool that allows you to explore, analyze, and share data using SQL. Select the Consumption hosting plan and then choose Select. Log in with your Azure account credentials. Choose Create a resource.
We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
Every new sale, every new inquiry, every website interaction, every swipe on social media generates data. These include data catalog , data literacy and a host of built-in automation capabilities that take the pain out of data preparation. What Is Good Data Governance? Therefore good data governance is proactive not reactive.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. After deployment, the user will have access to a Jupyter notebook, where they can interact with two datasets from ASDI on AWS: Coupled Model Intercomparison Project 6 (CMIP6) and ECMWF ERA5 Reanalysis.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). We have cataloging inside Datasphere: It allows you to catalog, manage metadata, all the SAP data assets we’re seeing,” said JG Chirapurath, chief marketing and solutions officer for SAP. “We
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. from the business interactions), but if not available, then through confirmation techniques of an independent nature. 2 – Data profiling. This is definitely not in line with reality.
In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering. VPC endpoints are created for Amazon S3 and Secrets Manager to interact with other resources. Otherwise, it will check the metadata database for the value and return that instead.
If it isn’t hosted on your infrastructure, you can’t be as certain about its security posture. With Amazon Q in QuickSight, every user can generate interactive data stories, without waiting for BI experts or data scientists to update the data and produce new dashboards.
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. All of the resources are defined in a sample AWS Cloud Development Kit (AWS CDK) template.
In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. In the future, we plan to profile workloads based on metadata, cross-check them with capacity metrics, and place them in the appropriate MSK cluster.
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog. The global catalog is also periodically fully refreshed to resolve issues during metadata sync processes to maintain resiliency.
System metadata is reviewed and updated regularly. The cluster architecture can be split across a number of zones as illustrated in the following diagram: Outside the perimeter are source data and applications, the gateway zones are where administrators and applications will interact with the core cluster zones where the work is performed.
Amazon QuickSight is a fully managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards and reports, and share these with tens of thousands of users, either within QuickSight or embedded in your application or website. SDK Feature overview The QuickSight SDK v2.0
FINRA centralizes all its data in Amazon Simple Storage Service (Amazon S3) with a remote Hive metastore on Amazon Relational Database Service (Amazon RDS) to manage their metadata information. host') export PASSWORD=$(aws secretsmanager get-secret-value --secret-id $secret_name --query SecretString --output text | jq -r '.password')
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. When a mix of batch, interactive, and data serving workloads are added to the mix, the problem becomes nearly intractable. Noisy Neighbors in Large, Multi-Tenant Clusters.
Public cloud support: Many CSPs use hyperscalers like AWS to host their 5G network functions, which requires automated deployment and lifecycle management. Hybrid cloud support: Some network functions must be hosted on a private data center, but that also the requires ability to automatically place network functions dynamically.
Iceberg captures metadata information on the state of datasets as they evolve and change over time. AWS Glue crawlers will extract schema information and update the location of Iceberg metadata and schema updates in the Data Catalog. Choose Create.
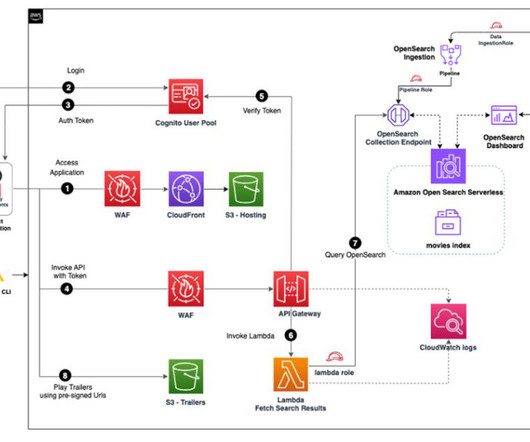
The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
Download the Gartner® Market Guide for Active Metadata Management 1. Efficient cloud migrations McKinsey predicts that $8 out of every $10 for IT hosting will go toward the cloud by 2024. We’ve compiled six key reasons why financial organizations are turning to lineage platforms like MANTA to get control of their data.
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. When you use the neural plugin’s connectors, you don’t need to build additional pipelines external to OpenSearch Service to interact with these models during indexing and searching.
In this episode of the AI to Impact Podcast, host Pavan Kumar speaks to Prinkan Pal about the evolution of data engineering and ML-operations from a closed team into a tech consulting unit. I’m your host – Pawan Kumar. Thanks for making the time for this interaction today. Listening time: 12 minutes.
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. Set up Athena to run interactive SQL. In this section, we cover common ways to interact, filter, and process the Common Crawl dataset. Create an EMR Serverless environment.
First, the Airflow REST API support enables programmatic interaction with Airflow resources like connections, Directed Acyclic Graphs (DAGs), DAGRuns, and Task instances. Furthermore, the user’s permissions for interacting with the REST API are determined by the Airflow role assigned to them within Amazon MWAA.
OpenSearch Dashboards is a visualization and exploration tool that allows you to create, manage, and interact with visuals, dashboards, and reports based on the data indexed in your OpenSearch cluster. Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp.
The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. With unified metadata, both data processing and data consuming applications can access the tables using the same metadata. For metadata read/write, Flink has the catalog interface.
Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. Profile aggregation – When you’ve uniquely identified a customer, you can build applications in Managed Service for Apache Flink to consolidate all their metadata, from name to interaction history.
Iceberg employs internal metadata management that keeps track of data and empowers a set of rich features at scale. The transformed zone is an enterprise-wide zone to host cleaned and transformed data in order to serve multiple teams and use cases. Data can be organized into three different zones, as shown in the following figure.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
What the mapping is of technical metadata to business descriptions. Alation Connect synchronizes metadata, sample data, and query logs into the Alation Data Catalog. All connections allow for Alation Data Catalog to automatically inventory & catalog queries and these engines may be hosted and operated on-premise or in the cloud.
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Allows metadata repositories to share and exchange. Adds governance, discovery, and access frameworks for automating the collection, management, and use of metadata.
Priority 2 logs, such as operating system security logs, firewall, identity provider (IdP), email metadata, and AWS CloudTrail , are ingested into Amazon OpenSearch Service to enable the following capabilities. Develop log and trace analytics solutions with interactive queries and visualize results with high adaptability and speed.
For instance, it is increasingly advisable to provide transparency to end users about the presence and use of any AI they are interacting with. Responsibility for risk: These forms can imply that model owners will be absolved of risk because they used a certain technology or cloud host or procured a model from a third party.
Performance It is not uncommon for sub-second SLAs to be associated with data vault queries, particularly when interacting with the business vault and the data marts sitting atop the business vault. Chargeback metadata Amazon Redshift provides different pricing models to cater to different customer needs.
Download the SAML metadata file. In the navigation pane under Clients , import the SAML metadata file. Insert your specific host domain name where the Keycloak application resides in the following URL: [link] /realms/aws-realm/protocol/saml/descriptor. Download the Keycloak IdP SAML metadata file from that URL location.
The Data Catalog provides metadata that allows analytics applications using Athena to find, read, and process the location data stored in Amazon S3. The crawlers will automatically classify the data into JSON format, group the records into tables and partitions, and commit associated metadata to the AWS Glue Data Catalog. Choose Run.
After the data lands in Amazon S3, smava uses the AWS Glue Data Catalog and crawlers to automatically catalog the available data, capture the metadata, and provide an interface that allows querying all data assets. Evolution of the data platform requirements smava started with a single Redshift cluster to host all three data stages.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content