This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Improve accuracy and resiliency of analytics and machinelearning by fostering data standards and high-quality data products. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machinelearning applications. This process is shown in the following figure.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machinelearning services to streamline the user journey from data to insight.
For example, you can use metadata about the Kinesis data stream name to index by data stream ( ${getMetadata("kinesis_stream_name") ), or you can use document fields to index data depending on the CloudWatch log group or other document data ( ${path/to/field/in/document} ).
To achieve this, they plan to use machinelearning (ML) models to extract insights from data. Next, we focus on building the enterprise data platform where the accumulated data will be hosted. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products.
The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products. A data portal for consumers to discover data products and access associated metadata. Subscription workflows that simplify access management to the data products.
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines.
This fragmented, repetitive, and error-prone experience for data connectivity is a significant obstacle to data integration, analysis, and machinelearning (ML) initiatives. For Host , enter your host name of your Aurora PostgreSQL database cluster. On your project, in the navigation pane, choose Data. Choose Next.
This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
This data needs to be ingested into a data lake, transformed, and made available for analytics, machinelearning (ML), and visualization. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machinelearning and streaming workloads. awsAccessKey=s3-spark-user/HOST@REALM.COM. Ozone Namespace Overview.
This type of structure is foundational at REA for building microservices and timely data processing for real-time and batch use cases like time-sensitive outbound messaging, personalization, and machinelearning (ML). In this post, we share our approach to MSK cluster capacity planning.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. The onboarding of producers is facilitated by sharing metadata, whereas the onboarding of consumers is based on granting permission to access this metadata. The producer account will host the EMR cluster and S3 buckets.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. These datasets are distributed across the world and hosted for public use. Data scientists have access to the Jupyter notebook hosted on SageMaker. The OpenSearch Service domain stores metadata on the datasets connected at the Regions.
Create an Amazon Route 53 public hosted zone such as mydomain.com to be used for routing internet traffic to your domain. For instructions, refer to Creating a public hosted zone. Request an AWS Certificate Manager (ACM) public certificate for the hosted zone. hosted_zone_id – The Route 53 public hosted zone ID.
We developed and host several applications for our customers on Amazon Web Services (AWS). AWS services such as Amazon Neptune and Amazon OpenSearch Service form part of their data and analytics pipelines, and AWS Batch is used for long-running data and machinelearning (ML) processing tasks.
BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). EDLS job steps and metadata Every EDLS job comprises one or more job steps chained together and run in a predefined order orchestrated by the custom ETL framework. It retrieves the specified files and available metadata to show on the UI.
In this post, we discuss how the Amazon Finance Automation team used AWS Lake Formation and the AWS Glue Data Catalog to build a data mesh architecture that simplified data governance at scale and provided seamless data access for analytics, AI, and machinelearning (ML) use cases.
There were also a host of other non-certified technical skills attracting pay premiums of 17% or more, way above those offered for certifications, and many of them centered on management, methodologies and processes or broad technology categories rather than on particular tools.
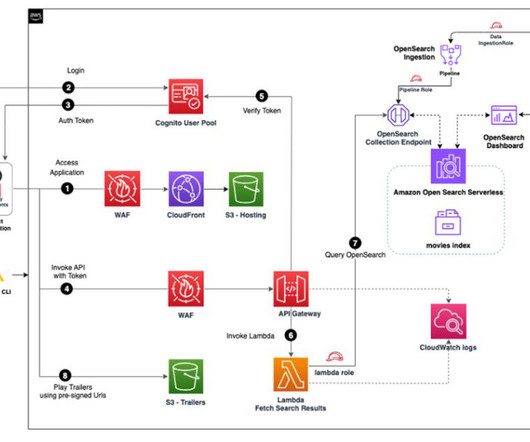
The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Plus, the more mature machinelearning (ML) practices place greater emphasis on these kinds of solutions than the less experienced organizations. We keep feeding the monster data.
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. In addition, OpenSearch Service supports neural search , which provides out-of-the-box machinelearning (ML) connectors.
Secondly, I talked backstage with Michelle, who got into the field by working on machinelearning projects, though recently she led data infrastructure supporting data science teams. Just doing machinelearning is not enough, and sometimes not even necessary.”. First off, her slides are fantastic! Nick Elprin.
Virtual Machine-based autoscaling) instead of using advanced deployment types such as containers that reduce time to scale up / down compute resources. Limited flexibility to use more complex hosting models (e.g., public, private, hybrid cloud)?
The platform’s capabilities in security, metadata, and governance will provide robust support to HBL’s focus on compliance and keeping data clean and safe in an increasingly complex regulatory and threat environment. CDP Private Cloud’s new approach to data management and analytics would allow HBL to access powerful self-service analytics.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. Data Champions: OVO (PT Visionet Internasional) — Using advanced, intelligent data analytics and machinelearning to increase customer conversion rates. DATA FOR ENTERPRISE AI.
FINRA centralizes all its data in Amazon Simple Storage Service (Amazon S3) with a remote Hive metastore on Amazon Relational Database Service (Amazon RDS) to manage their metadata information. host') export PASSWORD=$(aws secretsmanager get-secret-value --secret-id $secret_name --query SecretString --output text | jq -r '.password')
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. He leads the product initiatives for AI and machinelearning (ML) on OpenSearch including OpenSearch’s vector database capabilities.
Data science teams in industry must work with lots of text, one of the top four categories of data used in machinelearning. We can compare open source licenses hosted on the Open Source Initiative site: In [11]: lic = {} ?lic["mit"] metadata=convention_df["speaker"]? ). return "n" join(buf)?.
One key component that plays a central role in modern data architectures is the data lake, which allows organizations to store and analyze large amounts of data in a cost-effective manner and run advanced analytics and machinelearning (ML) at scale. About the Authors Eliad Gat is a Big Data & AI/ML Architect at Orca Security.
CDP Public Cloud leverages the elastic nature of the cloud hosting model to align spend on Cloudera subscription (measured in Cloudera Consumption Units or CCUs) with actual usage of the platform. MachineLearning Prototypes. that optimizes autoscaling for compute resources compared to the efficiency of VM-based scaling. .
Content Enrichment and Metadata Management. The value of metadata for content providers is well-established. When that metadata is connected within a knowledge graph, a powerful mechanism for content enrichment is unlocked. Ontotext Platform can be employed for a number of applications within an enterprise.
You can take all your data from various silos, aggregate that data in your data lake, and perform analytics and machinelearning (ML) directly on top of that data. After the table is cataloged in your AWS Glue metadata catalog, you can run queries directly on your data in your S3 data lake through OpenSearch Dashboards.
The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data. This feature is particularly useful if you want to externally process various files, evaluate multiple machinelearning models, or extraneously process a varied amount of data based on a SQL request. environment.
One important feature is to run different workloads such as business intelligence (BI), MachineLearning (ML), Data Science and data exploration, and Change Data Capture (CDC) of transactional data, without having to maintain multiple copies of data. Data can be organized into three different zones, as shown in the following figure.
By separating the compute, the metadata, and data storage, CDW dynamically adapts to changing workloads and resource requirements, speeding up deployment while effectively managing costs – while preserving a shared access and governance model. If the data is already there, you can move on to launching data warehouse services.
This can be achieved using AWS Entity Resolution , which enables using rules and machinelearning (ML) techniques to match records and resolve identities. Business metadata is stored and managed by Amazon DataZone, which is underpinned by technical metadata and schema information, which is registered in the AWS Glue Data Catalog.
The new approach would need to offer the flexibility to integrate new technologies such as machinelearning (ML), scalability to handle long-term retention at forecasted growth levels, and provide options for cost optimization. Zurich wanted to identify a log management solution to work in conjunction with their existing SIEM solution.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machinelearning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machinelearning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content