This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
6) Data Quality Metrics Examples. Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports.
For example, you can use metadata about the Kinesis data stream name to index by data stream ( ${getMetadata("kinesis_stream_name") ), or you can use document fields to index data depending on the CloudWatch log group or other document data ( ${path/to/field/in/document} ).
Each Lucene index (and, therefore, each OpenSearch shard) represents a completely independent search and storage capability hosted on a single machine. How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. The following is an example for the structure of an Elasticsearch 7.10
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. You might have millions of short videos , with user ratings and limited metadata about the creators or content.
From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau. This process is shown in the following figure.
In Part 2 of this series, we discussed how to enable AWS Glue job observability metrics and integrate them with Grafana for real-time monitoring. In this post, we explore how to connect QuickSight to Amazon CloudWatch metrics and build graphs to uncover trends in AWS Glue job observability metrics.
The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products. A data portal for consumers to discover data products and access associated metadata. Subscription workflows that simplify access management to the data products.
In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. Solution overview The MSK clusters in Hydro are configured with a PER_TOPIC_PER_BROKER level of monitoring, which provides metrics at the broker and topic levels.
Load balancing challenges with operating custom stream processing applications Customers processing real-time data streams typically use multiple compute hosts such as Amazon Elastic Compute Cloud (Amazon EC2) to handle the high throughput in parallel. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints.
The solution for this post is hosted on GitHub. Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. This is the bucket where you host all of your DAGs for your environment. [1.b]
These motors are often housed in harsh environmental conditions with significant temperature fluctuations that make it difficult to measure motor sound and vibration accurately, which are crucial metrics for assessing functionality and identifying potential faults.
Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities. These metrics help agents improve their call handle time and also reallocate agents across organizations to handle pending calls in the queue.
Another notable item is that Streams Replication Manager (SRM) will now support multi-cluster monitoring patterns and aggregate replication metrics from multiple SRM deployments into a single viewable location in Streams Messaging Manager (SMM.) A single SRM deployment can now monitor all the replication metrics for multiple target clusters.
Instead, there should be a cloud service that allows NiFi users to easily deploy their existing data flows to a scalable runtime with a central monitoring dashboard providing the most relevant metrics for each data flow. Users access the CDF-PC service through the hosted CDP Control Plane. Use KPIs to track important data flow metrics.
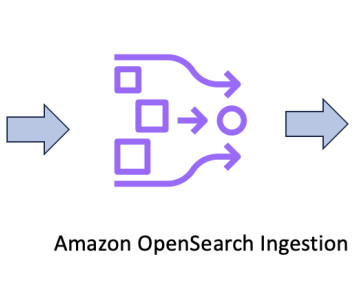
OSI is a fully managed, serverless data collector that delivers real-time log, metric, and trace data to OpenSearch Service domains and OpenSearch Serverless collections. Migration of metadata such as security roles and dashboard objects will be covered in another subsequent post.
it offers data connectors, visualization layers, and hosting all in one package, making it ideal for teams that are data-driven with limited resources. It comes with organizational features that support working in a large team, including metadata for tables. It also comes with data caching capabilities that enable fast querying.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. In an OpenSearch Service cluster, the active and standby zones can be checked at any time using Availability Zone rotation metrics, as shown in the following screenshot.
It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. Relevance of Operations per Second to Scale Ozone Manager hosts the metadata for the Objects stored within Ozone and consists of a cluster of Ozone Manager instances replicated via Ratis (a raft implementation ).
For on-demand ingestion for past time durations where you don’t expect new objects to be created, consider using supported pipeline metrics such as recordsOut.count to create Amazon CloudWatch alarms that can stop the pipeline. For a list of supported metrics, refer to Monitoring pipeline metrics.
Manually add objects and or links to represent metadata that wasn’t included in the extraction and document descriptions for user visualization. Microstrategy coverage enhancements: Reports Data sets Metrics Filters Facts Attributes Schemas Dossiers. Azure SSIS (PaaS) – Extraction of SSIS hosted by Azure Data Factory.
Finally we also recommend that you take a full backup of your cluster configurations, metadata, other supporting details, and backend databases. After Ambari has been upgraded, download the cluster blueprints with hosts. In some cases, applications may require changes if they depend on components that are removed and unsupported.
OpenTelemetry and Prometheus enable the collection and transformation of metrics, which allows DevOps and IT teams to generate and act on performance insights. These APIs play a key role in standardizing the collection of OpenTelemetry metrics. Metrics: Metrics define a high-level overview of system performance and health.
Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp. Create an SQS queue Amazon SQS offers a secure, durable, and available hosted queue that lets you integrate and decouple distributed software systems and components.
If you want to know why a report from Power BI delivered a particular number, data lineage traces that data point back through your data warehouse or lakehouse, back through your data integration tool, back to where the data basis for that report metric first entered your system. Choosing a data lineage solution for the modern data stack.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake. Cloudera Manager 6.2
This data is sent to Apache Kafka, which is hosted on Amazon Managed Streaming for Apache Kafka (Amazon MSK). In addition, using Apache Iceberg’s metadata tables proved to be very helpful in identifying issues related to the physical layout of Iceberg’s tables, which can directly impact query performance.
With the new REST API, you can now invoke DAG runs, manage datasets, or get the status of Airflow’s metadata database, trigger, and scheduler—all without relying on the Airflow web UI or CLI. Args: region (str): AWS region where the MWAA environment is hosted. Args: region (str): AWS region where the MWAA environment is hosted.
The workload breakdown measured in estimated vCPU-hours (based on on-premises capacity and utilization metrics) by region and data lifecycle stage is summarized in the Shankey chart below: . performance against network metrics such as latency, packet loss and jitter). Risk Mitigation.
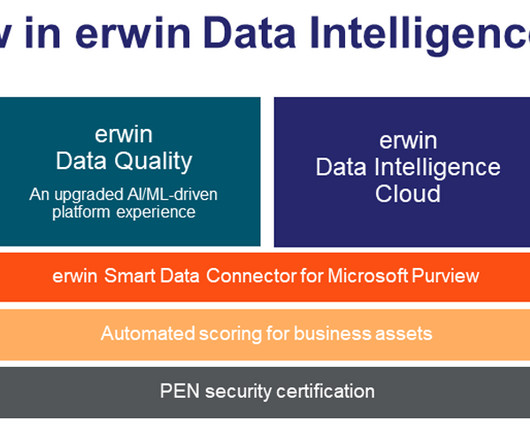
Leveraging the metadata within the erwin Data Intelligence data catalog, erwin Data Quality automates data profiling and quality assessment and then leverages the resulting quality scoring to provide intelligence-integrated data quality visibility throughout erwin Data Intelligence.
Machine learning plays a key role, as it can increase the speed and accuracy of metadata capture and categorization. Auto-tracked metrics guide governance efforts, based on insights around data quality and profiling. By analyzing metadata, the catalog streamlines data management and search. How often is it accessed?
Although this post uses an Aurora PostgreSQL database hosted on AWS as the data source, the solution can be extended to ingest data from any of the AWS DMS supported databases hosted on your data centers. Monitoring – EMR Serverless sends metrics to Amazon CloudWatch at the application and job level every 1 minute.
Then calculate the variance divided by the mean to construct a metric for noise in decision-making. Kahneman described how in many professional organizations, people would intuitively estimate that metric near 0.1 – however, in reality, that value often exceeds 0.5 Measure how these decisions vary across your population.
If your updates to a dataset triggers multiple subsequent DAGs, then you can use the Airflow metric max_active_tasks_per_dag to control the parallelism of the consumer DAG and reduce the chance of overloading the system. The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data.
Redshift provisioned clusters also support query monitoring rules to define metrics-based performance boundaries for workload management queues and the action that should be taken when a query goes beyond those boundaries. A predicate consists of a metric, a comparison condition (=, ), and a value.
The following figure shows some of the metrics derived from the study. Profile aggregation – When you’ve uniquely identified a customer, you can build applications in Managed Service for Apache Flink to consolidate all their metadata, from name to interaction history. Organizations using C360 achieved 43.9%
A dimension is a structure that captures reference data along with associated hierarchies, while a fact table captures different values and metrics that can be aggregated by dimensions. The star schema data model allows analytical users to query historical data tying metrics to corresponding dimensional attribute values over time.
This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders. He’ll share how “metadata normalization” played a key role in the journey to automation, the steps required to automate data governance processes, and why a data catalog was critical to the project’s success.
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. It similarly codes the query as a vector and then uses a distance metric to find nearby vectors in the multi-dimensional space to find matches.
They classified the metrics and indicators in the following categories: Data usage – A clear understanding of who is consuming what data source, materialized with a mapping of consumers and producers. The success of the implementation meant assessing various aspects of the data infrastructure, data management, and business outcomes.
CDP Public Cloud leverages the elastic nature of the cloud hosting model to align spend on Cloudera subscription (measured in Cloudera Consumption Units or CCUs) with actual usage of the platform. I would like to thank Mike Forrest who helped with the arduous task of collecting AWS and Azure pricing metrics. Acknowledgment.
After the data lands in Amazon S3, smava uses the AWS Glue Data Catalog and crawlers to automatically catalog the available data, capture the metadata, and provide an interface that allows querying all data assets. Evolution of the data platform requirements smava started with a single Redshift cluster to host all three data stages.
Leveraging an open-source solution like Apache Ozone, which is specifically designed to handle exabyte-scale data by distributing metadata throughout the entire system, not only facilitates scalability in data management but also ensures resilience and availability at scale.
We can compare open source licenses hosted on the Open Source Initiative site: In [11]: lic = {} ?lic["mit"] metadata=convention_df["speaker"]? ). You could cluster (k=2) on NPS scores (a customer evaluation metric) then replace the Democrat/Republican dimension with the top two components from the clustering.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content