This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
EUROGATEs data science team aims to create machine learning models that integrate key data sources from various AWS accounts, allowing for training and deployment across different container terminals. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
As a producer, you can also monetize your data through the subscription model using AWS Data Exchange. To achieve this, they plan to use machine learning (ML) models to extract insights from data. Next, we focus on building the enterprise data platform where the accumulated data will be hosted.
This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ. The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products.
Generative artificial intelligence ( genAI ) and in particular large language models ( LLMs ) are changing the way companies develop and deliver software. The commodity effect of LLMs over specialized ML models One of the most notable transformations generative AI has brought to IT is the democratization of AI capabilities.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. For machine learning systems used in consumer internet companies, models are often continuously retrained many times a day using billions of entirely new input-output pairs.
Hosted weekly by Paul Muller, The AI Forecast speaks to experts in the space to understand the ins and outs of AI in the enterprise, the kinds of data architectures and infrastructures that support it, the guardrails that should be put in place, and the success stories to emulateor cautionary tales to learn from.
The following diagram illustrates an indexing flow involving a metadata update in OR1 During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. The replica copies subsequently download newer segments and make them searchable.
The solution for this post is hosted on GitHub. Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. This is the bucket where you host all of your DAGs for your environment. [1.b]
“The data catalog is critical because it’s where business manages its metadata,” said Venkat Rajaji, Senior Vice President of Product Management at Cloudera. But the metadata turf war is just getting started.” That put them in a better position to keep data under management – and possibly to host processing as well.
Without a way to define and measure data confidence, AI model training environments, data analytics systems, automation engines, and so on must simply trust that the data has not been simulated, corrupted, poisoned, or otherwise maliciously generated—increasing the risks of downtime and other disasters.
Select the Consumption hosting plan and then choose Select. In the Create function pane, provide the following information: For Select a template , choose v2 Programming Model. For Programming Model , choose the HTTP trigger template. Log in with your Azure account credentials. Choose Create a resource. choose Next.
erwin recently hosted the third in its six-part webinar series on the practice of data governance and how to proactively deal with its complexities. This model has been dubbed the Medici maturity model – named after Romina Medici , head of data management and governance for global energy provider E.ON. erwin Data Intelligence.
Data has always been important to erwin; we’ve been a trusted data modeling brand for more than 30 years. These include data catalog , data literacy and a host of built-in automation capabilities that take the pain out of data preparation. The Best Data Governance Solution.
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines.
Did you know that, if you add “take a deep breath” to a prompt, chances are you will get more accurate results from Large Language Models (LLMs)? Do Knowledge Graphs Dream of Large Language Models? I didn’t either. He shared the need for more research at the intersection of LLMs and knowledge graphs.
Before we jump into the data ingestion step, here is a quick overview of how Ozone manages its metadata namespace through volumes, buckets and keys. . If created using the Filesystem interface, the intermediate prefixes ( application-1 & application-1/instance-1 ) are created as directories in the Ozone metadata store. s3 = boto3.resource('s3',
Paco Nathan ‘s latest article covers program synthesis, AutoPandas, model-driven data queries, and more. In other words, using metadata about data science work to generate code. Using ML models to search more effectively brought the search space down to 102—which can run on modest hardware. Model-Driven Data Queries.
To better understand why a business may choose one cloud model over another, let’s look at the common types of cloud architectures: Public – on-demand computing services and infrastructure managed by a third-party provider and shared with multiple organizations using the public Internet. Public clouds offer large scale at low cost.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). We have cataloging inside Datasphere: It allows you to catalog, manage metadata, all the SAP data assets we’re seeing,” said JG Chirapurath, chief marketing and solutions officer for SAP. “We
Also, a data model that allows table truncations at a regular frequency (for example, every 15 seconds) to store only relevant data in tables can cause locking and performance issues. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
These needs are then quantified into data models for acquisition and delivery. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. The captured data points should be modeled and defined based on specific characteristics (e.g.,
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. The onboarding of producers is facilitated by sharing metadata, whereas the onboarding of consumers is based on granting permission to access this metadata. The producer account will host the EMR cluster and S3 buckets.
Defining and capturing a business capability model If an enterprise doesn’t have a system to capture the business capability model, consider defining and finding a way to capture the model for better insight and visibility, and then map it with digital assets like APIs. It keeps evolving with business requirements and usage.
We developed and host several applications for our customers on Amazon Web Services (AWS). ZS unlocked new value from unstructured data for evidence generation leads by applying large language models (LLMs) and generative artificial intelligence (AI) to power advanced semantic search on evidence protocols.
However, it’s also a precious resource that must be safeguarded, and large language models (LLMs) have been known to compromise that safety. If it isn’t hosted on your infrastructure, you can’t be as certain about its security posture. If data is the new oil, it’s only useful once it’s been refined.
difficulty to achieve cross-organizational governance model). Data and Metadata: Data inputs and data outputs produced based on the application logic. Infrastructure Environment: The infrastructure (including private cloud, public cloud or a combination of both) that hosts application logic and data.
In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. In the future, we plan to profile workloads based on metadata, cross-check them with capacity metrics, and place them in the appropriate MSK cluster.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. After deployment, the user will have access to a Jupyter notebook, where they can interact with two datasets from ASDI on AWS: Coupled Model Intercomparison Project 6 (CMIP6) and ECMWF ERA5 Reanalysis.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. One notable drawback of this replication model is its susceptibility to slowdowns in the event of any impairment in the write path.
With this tool, analysts are able to visualize complex data models in Python, SQL, and R. it offers data connectors, visualization layers, and hosting all in one package, making it ideal for teams that are data-driven with limited resources. It also comes with data caching capabilities that enable fast querying.
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. Amazon Titan Multimodal Embeddings G1 is a multimodal embedding model that generates embeddings to facilitate multimodal search. Add model access in Amazon Bedrock.
Combining the power of Domino Data Labs with Okera, your data scientists only get access to the columns, rows, and cells allowed, easily removing or redacting sensitive data such as PII and PHI not relevant to training models. So what does this look like? client('s3') obj = s3.get_object(Bucket='clinical-trials',
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
Large language models (LLMs) are becoming increasing popular, with new use cases constantly being explored. This is where model fine-tuning can help. Before you can fine-tune a model, you need to find a task-specific dataset. Next, we use Amazon SageMaker JumpStart to fine-tune the Llama 2 model with the preprocessed dataset.
The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog. The global catalog is also periodically fully refreshed to resolve issues during metadata sync processes to maintain resiliency.
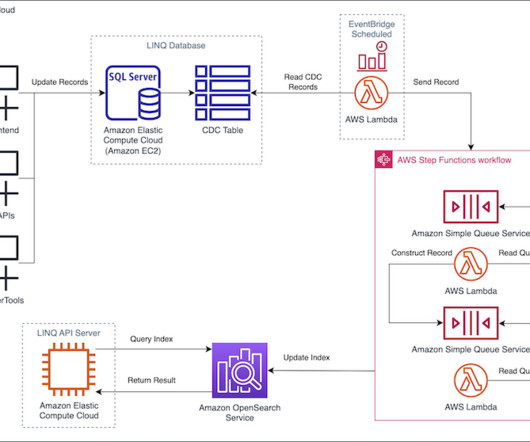
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
This means the creation of reusable data services, machine-readable semantic metadata and APIs that ensure the integration and orchestration of data across the organization and with third-party external data. This means having the ability to define and relate all types of metadata. Create a human AND machine-meaningful data model.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructured data by means of parallel execution on a large number of commodity computing nodes. . Limited flexibility to use more complex hostingmodels (e.g.,
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI.
You will learn how to prepare a multi-account environment to access the databases from AWS Glue, and how to model an ETL data flow that automatically masks PII as part of the transfer process, so that no sensitive information will be copied to the target database in its original form. See JDBC connections for further details.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content