This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. Because a CDC file can contain data for multiple tables, the job loops over the tables in a file and loads the table metadata from the source table ( RDS column names).
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.
Each Lucene index (and, therefore, each OpenSearch shard) represents a completely independent search and storage capability hosted on a single machine. How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. The following is an example for the structure of an Elasticsearch 7.10
Load balancing challenges with operating custom stream processing applications Customers processing real-time data streams typically use multiple compute hosts such as Amazon Elastic Compute Cloud (Amazon EC2) to handle the high throughput in parallel. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This post is co-written by Dr. Leonard Heilig and Meliena Zlotos from EUROGATE.
Next, we focus on building the enterprise data platform where the accumulated data will be hosted. In this context, Amazon DataZone is the optimal choice for managing the enterprise data platform. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products.
Within the ANZ enterprise data mesh strategy, aligning data mesh nodes with the ANZ Group’s divisional structure provides optimal alignment between data mesh principles and organizational structure, as shown in the following diagram. A data portal for consumers to discover data products and access associated metadata.
This can help you optimize long-term cost for high-throughput use cases. This includes adding common fields to associate metadata with the indexed documents, as well as parsing the log data to make data more searchable. In general, we recommend using one Kinesis data stream for your log aggregation workload.
Add Amplify hosting Amplify can host applications using either the Amplify console or Amazon CloudFront and Amazon Simple Storage Service (Amazon S3) with the option to have manual or continuous deployment. For simplicity, we use the Hosting with Amplify Console and Manual Deployment options.
With its scalability, reliability, and ease of use, Amazon OpenSearch Service helps businesses optimize data-driven decisions and improve operational efficiency. Launch an EC2 instance Note : Make sure to deploy the EC2 instance for hosting Jenkins in the same VPC as the OpenSearch domain. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com,
Optimizing device performance within the typical edge constraints of power, energy, latency, space, weight, and cost is essential. Specifically, what the DCF does is capture metadata related to the application and compute stack. Addressing this complex issue requires a multi-pronged approach.
As the use of Hydro grows within REA, it’s crucial to perform capacity planning to meet user demands while maintaining optimal performance and cost-efficiency. In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. Khizer Naeem is a Technical Account Manager at AWS.
For the client to resolve DNS queries for the custom domain, an Amazon Route 53 private hosted zone is used to host the DNS records, and is associated with the client’s VPC to enable DNS resolution from the Route 53 VPC resolver. The Kafka client uses the custom domain bootstrap address to send a get metadata request to the NLB.
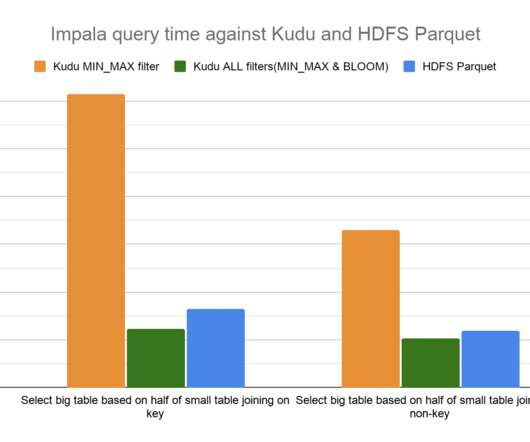
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. One of the ways Apache Kudu achieves this is by supporting column predicates with scanners. Before 7.1.5,
Through their unique position in ports, at sea, and on roads, they optimize global cargo flows and create sustainable customer value. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views. An AWS Glue job (metadata exporter) runs daily on the source account.
In other words, using metadata about data science work to generate code. SQL optimization provides helpful analogies, given how SQL queries get translated into query graphs internally , then the real smarts of a SQL engine work over that graph. On deck this time ’round the Moon: program synthesis. SQL and Spark.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. You might have millions of short videos , with user ratings and limited metadata about the creators or content.
Tableau is the right tool for creating rich, in-depth analytics or dashboards that can be optimized for tablets, phones, and desktops. it offers data connectors, visualization layers, and hosting all in one package, making it ideal for teams that are data-driven with limited resources.
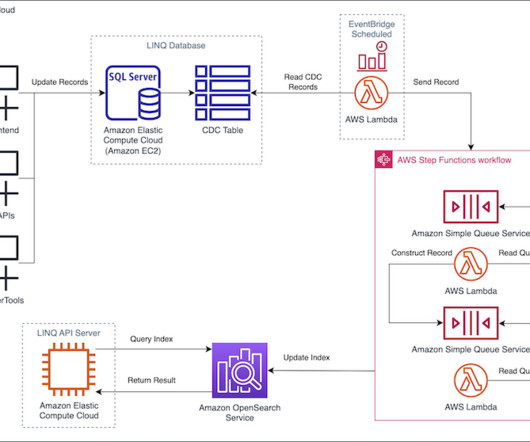
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog. The global catalog is also periodically fully refreshed to resolve issues during metadata sync processes to maintain resiliency.
Additionally, it enables cost optimization by aligning resources with specific use cases, making sure that expenses are well controlled. In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering. secretsmanager ). redshift-serverless.amazonaws.com:5439?
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. This is essential to measure and optimize this time, as it has many repercussions on the success of a business. Metadata management: Good data quality control starts with metadata management.
The new approach would need to offer the flexibility to integrate new technologies such as machine learning (ML), scalability to handle long-term retention at forecasted growth levels, and provide options for cost optimization. Previously, P2 logs were ingested into the SIEM. We discuss these key benefits in the following sections.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake.
It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. The hardware certification includes high density nodes with close to 500 TB per node optimized for performance and TCO. Optimize the Ozone Client to Ozone Manager protocols for reduced network round trips.
We developed and host several applications for our customers on Amazon Web Services (AWS). These embeddings, along with metadata such as the document ID and page number, are stored in OpenSearch Service. Each search method complemented the other, leading to optimal results. We’re using different models for different use cases.
Analyzing historical patterns allows you to optimize performance, identify issues proactively, and improve planning. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. All of the resources are defined in a sample AWS Cloud Development Kit (AWS CDK) template.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI.
This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability. Based on metadata, content is returned from Amazon S3 to the user.
By separating the compute, the metadata, and data storage, CDW dynamically adapts to changing workloads and resource requirements, speeding up deployment while effectively managing costs – while preserving a shared access and governance model. CDW implements a true win-win architecture, for all stakeholders’ and all data involved.
Infrastructure Cost Optimization. Infrastructure Optimization . Infrastructure Optimization. Replication Manager: A mechanism that helps migrating workloads between clouds and form factors (CDP Private and Public Cloud) and metadata with minimal effort. Germany (Primary Market) . North America (US East Region).
Limited flexibility to use more complex hosting models (e.g., Increased integration costs using different loose or tight coupling approaches between disparate analytical technologies and hosting environments. public, private, hybrid cloud)?
It integrates data across a wide arrange of sources to help optimize the value of ad dollar spending. Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity.
These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum , resulting in improved query performance and potential cost savings. The data lake performance optimization is especially important for queries with multiple joins and that is where cost-based optimizers helps the most.
In this post, we show how smava optimized their data platform by using Amazon Redshift Serverless and Amazon Redshift data sharing to overcome right-sizing challenges for unpredictable workloads and further improve price-performance. The following diagram shows the high-level data platform architecture before the optimizations.
Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp. Create an SQS queue Amazon SQS offers a secure, durable, and available hosted queue that lets you integrate and decouple distributed software systems and components.
This data is sent to Apache Kafka, which is hosted on Amazon Managed Streaming for Apache Kafka (Amazon MSK). Determining optimal table partitioning Determining optimal partitioning for each table is very important in order to optimize query performance and minimize the impact on teams querying the tables when partitioning changes.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. Cold storage is optimized to store infrequently accessed or historical data. Organizations often need to manage a high volume of data that is growing at an extraordinary rate.
Burst to Cloud not only relieves pressure on your data center, but it also protects your VIP applications and users by giving them optimal performance without breaking your bank. Today, it is nearly impossible for IT departments to know if a particular workload is optimal to move from on-premises to the cloud.
Users access the CDF-PC service through the hosted CDP Control Plane. The CDP control plane hosts critical components of CDF-PC like the Catalog , the Dashboard and the ReadyFlow Gallery. This will create a JSON file containing the flow metadata. and later). Figure 3: Export a NiFi process group from an existing cluster.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. Use cases could include but are not limited to: predictive maintenance, log data pipeline optimization, connected vehicles, industrial IoT, fraud detection, patient monitoring, network monitoring, and more.
It can help you to create, edit, optimize, fix, and succinctly summarize queries using natural language. This will expand the SQL AI toolbar with buttons to generate, edit, explain, optimize and fix SQL statements. After using edit, optimize, or fix, a preview shows the original query and the modified query differences.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content