This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We want to publish this data to Amazon DataZone as discoverable S3 data. Custom subscription workflow architecture diagram To implement the solution, we complete the following steps: As a data producer, publish an unstructured S3 based data asset as S3ObjectCollectionType to Amazon DataZone.
To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
Next, we focus on building the enterprise data platform where the accumulated data will be hosted. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. The enterprise data platform is used to host and analyze the sales data and identify the customer demand.
For instance, Domain A will have the flexibility to create data products that can be published to the divisional catalog, while also maintaining the autonomy to develop data products that are exclusively accessible to teams within the domain. A data portal for consumers to discover data products and access associated metadata.
Solution overview AWS AppSync creates serverless GraphQL and pub/sub APIs that simplify application development through a single endpoint to securely query, update, or publish data. For simplicity, we use the Hosting with Amplify Console and Manual Deployment options. All the resources are now deployed on AWS and ready for use.
Kinesis Data Streams not only offers the flexibility to use many out-of-box integrations to process the data published to the streams, but also provides the capability to build custom stream processing applications that can be deployed on your compute fleet. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight.
The retail team, acting as the data producer, publishes the necessary data assets to Amazon DataZone, allowing you, as a consumer, to discover and subscribe to these assets. Publish data assets – As the data producer from the retail team, you must ingest individual data assets into Amazon DataZone.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. For Host , enter your host name of your Aurora PostgreSQL database cluster. On your project, in the navigation pane, choose Data.
The sample solution relies on access to a public S3 bucket hosted for this blog so egress rules and permissions modifications may be required if you use S3 endpoints. In a series of follow-up posts, we will review the source code and walkthrough published examples of the Lambda ingestion framework in the AWS Samples GitHub repo.
This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
The following diagram illustrates an indexing flow involving a metadata update in OR1 During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. The replica copies subsequently download newer segments and make them searchable.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. You might establish a baseline by replicating collaborative filtering models published by teams that built recommenders for MovieLens, Netflix, and Amazon.
In this blog, we discuss the technical challenges faced by Cargotec in replicating their AWS Glue metadata across AWS accounts, and how they navigated these challenges successfully to enable cross-account data sharing. Solution overview Cargotec required a single catalog per account that contained metadata from their other AWS accounts.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
Datasets used for generating insights are curated using materialized views inside the database and published for business intelligence (BI) reporting. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets. Key Design Principles of a Data Mesh.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. Centralized catalog for published data – Multiple producers release data currently governed by their respective entities. For consumer access, a centralized catalog is necessary where producers can publish their data assets.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. Solution overview Each day, the UK Met Office produces up to 300 TB of weather and climate data, a portion of which is published to ASDI. These datasets are distributed across the world and hosted for public use.
Migration of metadata such as security roles and dashboard objects will be covered in another subsequent post. Update the following information for the source: Uncomment hosts and specify the endpoint of the existing OpenSearch Service endpoint. For now, you can leave the default minimum as 1 and maximum as 4.
An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. Publish the QuickSight dashboard When the analysis is ready, complete the following steps to publish the dashboard: Choose PUBLISH. Select Publish new dashboard as , and enter GlueObservabilityDashboard.
Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Its platform supports both publishers and advertisers so both can understand which creative work delivers the best results. Pega builds a low-code platform for designing and executing digital marketing campaigns.
This enabled producers to publish data products that were curated and authoritative assets for their domain. The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog.
Hydro is powered by Amazon MSK and other tools with which teams can move, transform, and publish data at low latency using event-driven architectures. In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. According to recent information published by Gartner, poor data quality costs businesses an average of $12.9 Metadata management: Good data quality control starts with metadata management.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. OpenSearch Service utilizes an internal node-to-node communication protocol for replicating write traffic and coordinating metadata updates through an elected leader.
Processors – The intermediate processing units that can filter, transform, and enrich records into a desired format before publishing them to the sink. It defines one or more destinations to which a pipeline publishes records. The processor is an optional component of a pipeline. Sink – The output component of a pipeline.
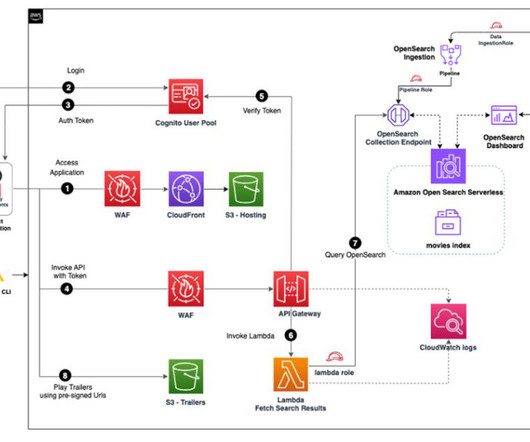
Amazon API Gateway is a fully managed service that makes it straightforward for developers to create, publish, maintain, monitor, and secure APIs at any scale. The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI.
Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Its platform supports both publishers and advertisers so both can understand which creative work delivers the best results.
SnapLogic published Eight Data Management Requirements for the Enterprise Data Lake. Metadata and Governance. The company also recently hosted a webinar on Democratizing the Data Lake with Constellation Research and published 2 whitepapers from Mark Madsen. They are: Storage and Data Formats. Ingest and Delivery.
erwin also provides data governance, metadata management and data lineage software called erwin Data Intelligence by Quest. It requires discipline, and information in the form of metadata about those being governed so that remedial action can be taken to hold people to account and ensure policies are being followed.
He invited everyone to contribute to Transactions on Graph Data and Knowledge (TGDK) – an open-access journal publishing research about graph data and knowledge. Both speakers talked about common metadata standards and adequate language resources as key enablers of efficient interoperable, multilingual projects.
Non-governmental bodies are also publishing guidance useful to public sector agencies. This year the World Economic Forum’s AI Governance Alliance this year published the Presidio AI Framework ( PDF ). For example, New York City published its own AI Action plan in October 2023, and formalized its AI principles in March 2024.
Content Enrichment and Metadata Management. The value of metadata for content providers is well-established. When that metadata is connected within a knowledge graph, a powerful mechanism for content enrichment is unlocked. Ontotext Platform can be employed for a number of applications within an enterprise.
The data product is not just the data itself, but a bunch of metadata that surrounds it — the simple stuff like schema is a given. It is also agnostic to where the different domains are hosted. The teams would then “publish” specific tables within their namespaces as publicly referenceable. Data fabric defined.
Iceberg employs internal metadata management that keeps track of data and empowers a set of rich features at scale. The transformed zone is an enterprise-wide zone to host cleaned and transformed data in order to serve multiple teams and use cases. Data can be organized into three different zones, as shown in the following figure.
This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. PoolParty also ensures that developing, publishing, or connecting content goes smoothly by making it easy to create tags with more precision.
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. To foster an open ecosystem, we created a framework to empower partners to easily build and publish AI connectors.
Leveraging an open-source solution like Apache Ozone, which is specifically designed to handle exabyte-scale data by distributing metadata throughout the entire system, not only facilitates scalability in data management but also ensures resilience and availability at scale.
Developers can use the support in Amazon Location Service for publishing device position updates to Amazon EventBridge to build a near-real-time data pipeline that stores locations of tracked assets in Amazon Simple Storage Service (Amazon S3). This solution uses distance-based filtering to reduce costs and jitter. Choose Run.
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Agile Manifesto get published. Allows metadata repositories to share and exchange. Disconnects, in a nutshell. Validates products for conformance. Upcoming Events.
Priority 2 logs, such as operating system security logs, firewall, identity provider (IdP), email metadata, and AWS CloudTrail , are ingested into Amazon OpenSearch Service to enable the following capabilities. Previously, P2 logs were ingested into the SIEM. He helps financial services customers improve their security posture in the cloud.
Today a modern catalog hosts a wide range of users (like business leaders, data scientists and engineers) and supports an even wider set of use cases (like data governance , self-service , and cloud migration ). (See Yet lately, a few analysts have started publishing evaluations of data catalogs for specific use cases. Conclusion.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content