This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Add Amplify hosting Amplify can host applications using either the Amplify console or Amazon CloudFront and Amazon Simple Storage Service (Amazon S3) with the option to have manual or continuous deployment. For simplicity, we use the Hosting with Amplify Console and Manual Deployment options.
System metadata is reviewed and updated regularly. Services in each zone use a combination of kerberos and transport layer security (TLS) to authenticate connections and APIs calls between the respective host roles, this allows authorization policies to be enforced and audit events to be captured. Sensitive data is encrypted.
All three will be quorums of Zookeepers and HDFS Journal nodes to track changes to HDFS Metadata stored on the Namenodes. CDP is particularly sensitive to host name resolution, therefore it’s vital that the DNS servers have been properly configured and hostnames are fully qualified. Networking . Clocks must also be synchronized.
Load balancing challenges with operating custom stream processing applications Customers processing real-time data streams typically use multiple compute hosts such as Amazon Elastic Compute Cloud (Amazon EC2) to handle the high throughput in parallel. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints.
To learn more about working with events using EventBridge, refer to Events via Amazon EventBridge default bus. After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. We refer to this role as the instance-role throughout the post. Enter a name for the asset.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. For Host , enter your host name of your Aurora PostgreSQL database cluster. To learn more, refer to Amazon SageMaker Unified Studio.
The solution for this post is hosted on GitHub. Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. Refer to the detailed deployment steps in the README file to deploy it in your own accounts.
The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. For the template and setup information, refer to Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator. We use two datasets in this post.
For the client to resolve DNS queries for the custom domain, an Amazon Route 53 private hosted zone is used to host the DNS records, and is associated with the client’s VPC to enable DNS resolution from the Route 53 VPC resolver. The Kafka client uses the custom domain bootstrap address to send a get metadata request to the NLB.
Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows. In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering. A VPC gateway endpointto Amazon S3.
This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
To learn more about this process, refer to Enabling SAML 2.0 Select the Consumption hosting plan and then choose Select. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. From there, the user can access the Redshift Query Editor V2. Save this file locally.
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data. 2 – Data profiling.
Refer to How can I access OpenSearch Dashboards from outside of a VPC using Amazon Cognito authentication for a detailed evaluation of the available options and the corresponding pros and cons. For more information, refer to the AWS CDK v2 Developer Guide. For instructions, refer to Creating a public hosted zone.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. It is recommended to use test accounts.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. For more information, refer to Guidance for Distributed Computing with Cross Regional Dask on AWS and the GitHub repo for open-source code. These datasets are distributed across the world and hosted for public use.
In this blog, we discuss the technical challenges faced by Cargotec in replicating their AWS Glue metadata across AWS accounts, and how they navigated these challenges successfully to enable cross-account data sharing. Solution overview Cargotec required a single catalog per account that contained metadata from their other AWS accounts.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. You might have millions of short videos , with user ratings and limited metadata about the creators or content.
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. For instructions, refer to Create your first S3 bucket. For instructions, refer to Get started. For explanations of each field, refer to Common Crawl Index Athena.
A private cloud can be hosted either in an organization’s own?data An organization may host some services in one cloud and others with a different provider. The term is sometimes also used to refer to a mix of public cloud and on-premises private data centers. Public clouds offer large scale at low cost.
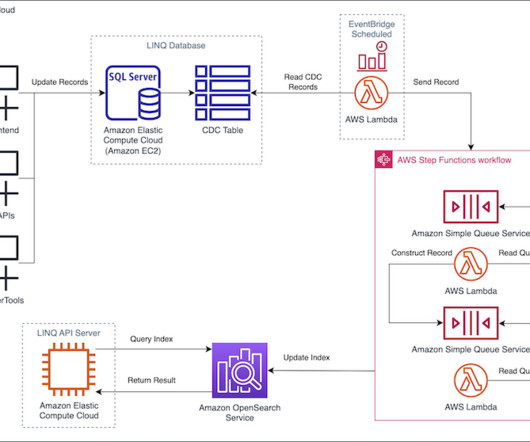
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
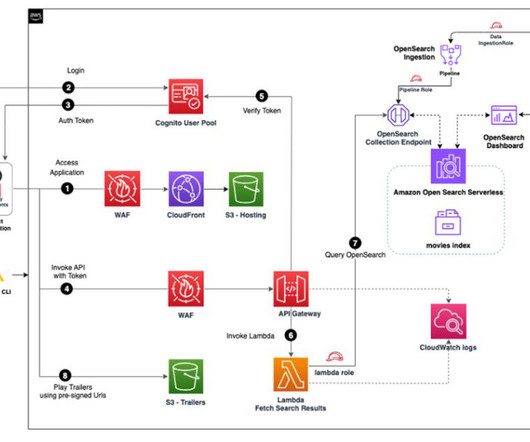
The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp. For instructions, refer to Creating and managing Amazon OpenSearch Service domains. You must have created an OpenSearch Service domain.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. OpenSearch Service utilizes an internal node-to-node communication protocol for replicating write traffic and coordinating metadata updates through an elected leader.
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. Note that you need to refer to the Jupyter Notebook in the GitHub repository to run the following steps using Python code in your client environment. OpenSearch version is 2.13
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
Iceberg captures metadata information on the state of datasets as they evolve and change over time. AWS Glue crawlers will extract schema information and update the location of Iceberg metadata and schema updates in the Data Catalog. For more details, refer to Creating Apache Iceberg tables. Choose Create.
We refer to this concept as outside-in data movement. For more details on data tiers within OpenSearch Service, refer to Choose the right storage tier for your needs in Amazon OpenSearch Service. For a list of supported metrics, refer to Monitoring pipeline metrics. Let’s look at an example use case. Example Corp.
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
To develop your disaster recovery plan, you should complete the following tasks: Define your recovery objectives for downtime and data loss (RTO and RPO) for data and metadata. For additional details, refer to Automated snapshots. For additional details, refer to Manual snapshots.
This feature lets users query AWS Glue databases and tables in one Region from another Region using resource links, without copying the metadata in the Data Catalog or the data in Amazon Simple Storage Service (Amazon S3). For more details, refer documentation. See registering your S3 location for instructions.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Apache Hive, Apache Spark, Presto, and Trino can all use a Hive Metastore to retrieve metadata to run queries.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI.
The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data. How dynamic task mapping works Let’s see an example using the reference code available in the Airflow documentation. release highlights, refer to What’s New In Python 3.10. For a full list of Python v3.10 environment.
To follow along with this post, you should have the following prerequisites: Three AWS accounts as follows: Source account: Hosts the source Amazon RDS for PostgreSQL database. For future reference, record the associated virtual private cloud (VPC) ID, security group, and private subnets associated to the Amazon RDS database.
Manually add objects and or links to represent metadata that wasn’t included in the extraction and document descriptions for user visualization. Azure SSIS (PaaS) – Extraction of SSIS hosted by Azure Data Factory. Collapse irrelevant results allowing users to focus on the task at hand. Column-to-column lineage. OK, so now what?
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. To learn more, refer to Byte-quantized vectors in OpenSearch. The following screenshot shows an example of using the Compare Search Results tool.
It is a replicated, highly-available service that is responsible for managing the metadata for all objects stored in Ozone. Cisco has multiple reference architectures for running Ozone. The tool reads only the metadata for objects in a cluster with around 100 million keys. The Ozone Manager is a critical component of Ozone.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake.
Public cloud support: Many CSPs use hyperscalers like AWS to host their 5G network functions, which requires automated deployment and lifecycle management. Hybrid cloud support: Some network functions must be hosted on a private data center, but that also the requires ability to automatically place network functions dynamically.
Solution overview The AWS Serverless Data Analytics Pipeline reference architecture provides a comprehensive, serverless solution for ingesting, processing, and analyzing data. At its core, this architecture features a centralized data lake hosted on Amazon Simple Storage Service (Amazon S3), organized into raw, cleaned, and curated zones.
A dimension is a structure that captures reference data along with associated hierarchies, while a fact table captures different values and metrics that can be aggregated by dimensions. Therefore, dimensions in a star schema that keeps track of changes over time are referred to as slowly changing dimensions (SCDs).
A private cloud can be hosted either in an organisation’s own data centre, at a third-party facility, or via a private cloud provider. An organisation may host some services in one cloud and others with a different provider. The term is sometimes also used to refer to a mix of public cloud and on-premises private data centres.
Amazon Elastic Kubernetes Service (Amazon EKS) is becoming a popular choice among AWS customers to host long-running analytics and AI or machine learning (ML) workloads. services.k8s.aws/v1alpha1 kind: Bucket metadata: name: sparkjob-demo-bucket spec: name: sparkjob-demo-bucket kubectl apply -f ack-yamls/s3.yaml We use the s3.yaml
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content