This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative artificial intelligence ( genAI ) and in particular large language models ( LLMs ) are changing the way companies develop and deliver software. The future will be characterized by more in-depth AI capabilities that are seamlessly woven into software products without being apparent to end users. An overview.
Each Lucene index (and, therefore, each OpenSearch shard) represents a completely independent search and storage capability hosted on a single machine. How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. The following is an example for the structure of an Elasticsearch 7.10
Next, we focus on building the enterprise data platform where the accumulated data will be hosted. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. The enterprise data platform is used to host and analyze the sales data and identify the customer demand.
For example, you can use metadata about the Kinesis data stream name to index by data stream ( ${getMetadata("kinesis_stream_name") ), or you can use document fields to index data depending on the CloudWatch log group or other document data ( ${path/to/field/in/document} ).
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machine learning (ML). But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. For Host , enter your host name of your Aurora PostgreSQL database cluster. On your project, in the navigation pane, choose Data.
The following diagram illustrates an indexing flow involving a metadata update in OR1 During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. In the event of an infrastructure failure, an OpenSearch domain can end up losing one or more nodes.
The solution for this post is hosted on GitHub. Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. This is the bucket where you host all of your DAGs for your environment. [1.b]
This leads to faster, more reliable software releases. Launch an EC2 instance Note : Make sure to deploy the EC2 instance for hosting Jenkins in the same VPC as the OpenSearch domain. es.amazonaws.com, this will be different for VPC hosted domain region = 'us-east-1' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials()
“The data catalog is critical because it’s where business manages its metadata,” said Venkat Rajaji, Senior Vice President of Product Management at Cloudera. But the metadata turf war is just getting started.” That put them in a better position to keep data under management – and possibly to host processing as well.
The power of a developer portal The power of Backstage lies in the organization that it can bring to your software development lifecycle. Improved c ollaboration with a shared environment for accessing, sharing and managing software components. A developer portal like Backstage can help.
As quality issues are often highlighted with the use of dashboard software , the change manager plays an important role in the visualization of data quality. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. 2 – Data profiling.
For this use case, create a data source and import the technical metadata of four data assets— customers , order_items , orders , products , reviews , and shipments —from AWS Glue Data Catalog. Eric Fleishman is a software engineer at AWS in Seattle. DataZoneEnvironmentId : The ID of your DefaultDataLake environment.
In this blog, we discuss the technical challenges faced by Cargotec in replicating their AWS Glue metadata across AWS accounts, and how they navigated these challenges successfully to enable cross-account data sharing. Solution overview Cargotec required a single catalog per account that contained metadata from their other AWS accounts.
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. Software writes Software?
The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog. The global catalog is also periodically fully refreshed to resolve issues during metadata sync processes to maintain resiliency.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). We have cataloging inside Datasphere: It allows you to catalog, manage metadata, all the SAP data assets we’re seeing,” said JG Chirapurath, chief marketing and solutions officer for SAP. “We
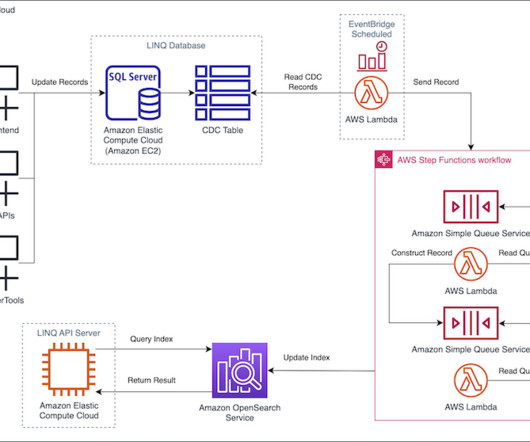
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
Any company relying on Adobe and its various advertising platforms, such as the Experience Cloud, can also use its Audience management software to gain up-to-the-minute insights into how various ads or promotions are performing. Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity.
The open source software ecosystem is dynamic and fast changing with regular feature improvements, security and performance fixes that Cloudera supports by rolling up into regular product releases, deployable by Cloudera Manager as parcels. Recommended deployment patterns. A minimum ensemble of 3 is required to achieve a majority consensus.
Business intelligence is simply a tool, computer software, and practice used to collect, integrate, analyze, and present raw business data that can be used to create actionable and informative business data. It comes with organizational features that support working in a large team, including metadata for tables.
HEMA built its first ecommerce system on AWS in 2018 and 5 years later, its developers have the freedom to innovate and build software fast with their choice of tools in the AWS Cloud. These services are individual software functionalities that fulfill a specific purpose within the company.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. OpenSearch Service utilizes an internal node-to-node communication protocol for replicating write traffic and coordinating metadata updates through an elected leader.
An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. He is responsible for building software artifacts to help customers. Chuhan Liu is a Software Development Engineer on the AWS Glue team. XiaoRun Yu is a Software Development Engineer on the AWS Glue team.
In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. In the future, we plan to profile workloads based on metadata, cross-check them with capacity metrics, and place them in the appropriate MSK cluster. About the Authors Eunice Aguilar is a Staff Data Engineer at REA.
Create an Amazon Route 53 public hosted zone such as mydomain.com to be used for routing internet traffic to your domain. For instructions, refer to Creating a public hosted zone. Request an AWS Certificate Manager (ACM) public certificate for the hosted zone. hosted_zone_id – The Route 53 public hosted zone ID.
However, Data Fabric is not an application or software package but a set of design principles and strategies to deal with the very real and concrete truth that centralized data storage and control is gone. This means having the ability to define and relate all types of metadata. Data Fabric hit the Gartner top ten in 2019.
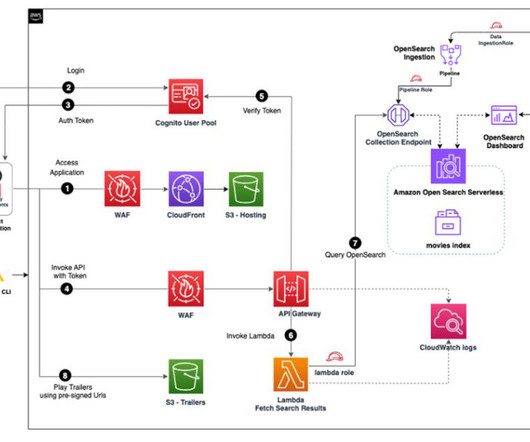
The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp. Create an SQS queue Amazon SQS offers a secure, durable, and available hosted queue that lets you integrate and decouple distributed software systems and components.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Apache Hive, Apache Spark, Presto, and Trino can all use a Hive Metastore to retrieve metadata to run queries.
Introduction Ozone is an Apache Software Foundation project to build a distributed storage platform that caters to the demanding performance needs of analytical workloads, content distribution, and object storage use cases. The tool reads only the metadata for objects in a cluster with around 100 million keys.
These sources include ad marketplaces that dump statistics about audience engagement and click-through rates, sales software systems that report on customer purchases, and websites — and even storeroom floors — that track engagement. Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake.
The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. With unified metadata, both data processing and data consuming applications can access the tables using the same metadata. For metadata read/write, Flink has the catalog interface.
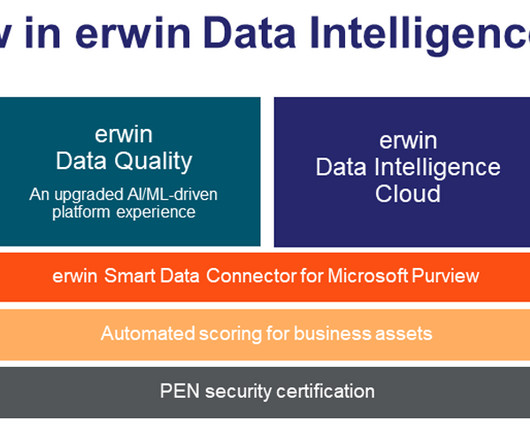
erwin also provides data governance, metadata management and data lineage software called erwin Data Intelligence by Quest. It requires discipline, and information in the form of metadata about those being governed so that remedial action can be taken to hold people to account and ensure policies are being followed.
While NiFi nodes can be added to an existing cluster, it is a multi-step process that requires organizations to set up constant monitoring of resource usage, detect when there is enough demand to scale, automate the provisioning of a new node with the required software and set up the security configuration. and later).
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. Select hosts for Active and Passive KTS servers. Data in the file is encrypted with DEK.
By using infrastructure as code (IaC) tools, ODP enables self-service data access with unified data management, metadata management (data catalog), and standard interfaces for analytics tools with a high degree of automation by providing the infrastructure, integrations, and compliance measures out of the box.
Priority 2 logs, such as operating system security logs, firewall, identity provider (IdP), email metadata, and AWS CloudTrail , are ingested into Amazon OpenSearch Service to enable the following capabilities. Previously, P2 logs were ingested into the SIEM. He helps financial services customers improve their security posture in the cloud.
Leveraging the metadata within the erwin Data Intelligence data catalog, erwin Data Quality automates data profiling and quality assessment and then leverages the resulting quality scoring to provide intelligence-integrated data quality visibility throughout erwin Data Intelligence. Register Now!
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Software startups gained much more attention. Allows metadata repositories to share and exchange. Taken together, those points warranted a much deeper review of the field.
FINRA centralizes all its data in Amazon Simple Storage Service (Amazon S3) with a remote Hive metastore on Amazon Relational Database Service (Amazon RDS) to manage their metadata information. host') export PASSWORD=$(aws secretsmanager get-secret-value --secret-id $secret_name --query SecretString --output text | jq -r '.password')
Monitoring and optimizing application performance is important for software developers and enterprises at large. SDKs: Software development kits are tools for building software. They include the framework, code libraries and debuggers that are the building blocks of software development.
OpenSearch Ingestion is serverless, so you don’t need to worry about scaling your infrastructure, operating your ingestion fleet, and patching or updating the software. After the table is cataloged in your AWS Glue metadata catalog, you can run queries directly on your data in your S3 data lake through OpenSearch Dashboards.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content