This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata. Intelligent data and content analysis Sentiment analysis Lets look at a practical example: an internal system allows employees to post short status messages about their work.
Amazon DataZone , a data management service, helps you catalog, discover, share, and govern data stored across AWS, on-premises systems, and third-party sources. After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. Delete the S3 bucket that hosted the unstructured asset.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
We use leading-edge analytics, data, and science to help clients make intelligent decisions. We developed and host several applications for our customers on Amazon Web Services (AWS). These embeddings, along with metadata such as the document ID and page number, are stored in OpenSearch Service.
The Data Fabric paradigm combines design principles and methodologies for building efficient, flexible and reliable data management ecosystems. Knowledge Graphs are the Warp and Weft of a Data Fabric. To implement any Data Fabric approach, it is essential to be able to understand the context of data.
LLMs] call into question a fundamental tenet of Data Management: that in order to address non-trivial information needs, the first step is to explicitly structuredata in order to lift them from the ambiguous swamp of our human language. Thankfully, lt-innovate.org already did a concise wrap-up.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. Understanding the data sets to be replicated from the CDH Cluster.
Spark SQL is an Apache Spark module for structureddata processing. FINRA centralizes all its data in Amazon Simple Storage Service (Amazon S3) with a remote Hive metastore on Amazon Relational Database Service (Amazon RDS) to manage their metadata information. or later installed. OutputKey=='HiveSecretName'].OutputValue"
Data lakes are designed for storing vast amounts of raw, unstructured, or semi-structureddata at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
Behind the scenes of linking histopathology data and building a knowledge graph out of it. Together with the other partners, Ontotext will be leveraging text analysis in order to extract structureddata from medical records and from annotated images related to histopathology information. The first type is metadata from images.
They classified the metrics and indicators in the following categories: Data usage – A clear understanding of who is consuming what data source, materialized with a mapping of consumers and producers. In this approach, teams responsible for generating data are referred to as producers.
To ingest the data, smava uses a set of popular third-party customer data platforms complemented by custom scripts. After the data lands in Amazon S3, smava uses the AWS Glue Data Catalog and crawlers to automatically catalog the available data, capture the metadata, and provide an interface that allows querying all data assets.
AWS Glue crawls both S3 bucket paths, populates the AWS Glue database tables based on the inferred schemas, and makes the data available to other analytics applications through the AWS Glue Data Catalog. Athena is used to run geospatial queries on the location data stored in the S3 buckets. Choose Run.
Additionally, it is vital to be able to execute computing operations on the 1000+ PB within a multi-parallel processing distributed system, considering that the data remains dynamic, constantly undergoing updates, deletions, movements, and growth. Consider data types.
Profile aggregation – When you’ve uniquely identified a customer, you can build applications in Managed Service for Apache Flink to consolidate all their metadata, from name to interaction history. Then, you transform this data into a concise format. The following screenshot shows an example C360 dashboard built on QuickSight.
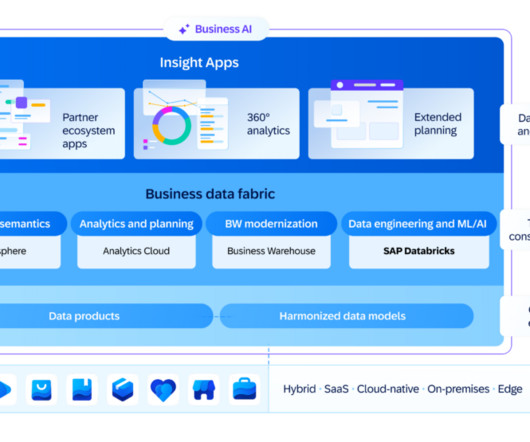
Business Data Cloud (BDC) consists of multiple existing and new services built by SAP and its partners: Object store which is an OEM from Databricks Databricks Data Engineering and AI/ML Tools SAP Datasphere SAP BW 7.5
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content