This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can now test the newly created application by running the following command: npm run dev By default, the application is available on port 5173 on your local machine. For simplicity, we use the Hosting with Amplify Console and Manual Deployment options. The base application is shown in the workspace browser.
It is advised to discourage contributors from making changes directly to the production OpenSearch Service domain and instead implement a gatekeeper process to validate and test the changes before moving them to OpenSearch Service. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com, Leave the settings as default.
Collaborating closely with our partners, we have tested and validated Amazon DataZone authentication via the Athena JDBC connection, providing an intuitive and secure connection experience for users. Choose Test connection. Choose Test Connection. DataZoneEnvironmentId : The ID of your DefaultDataLake environment.
Select the Consumption hosting plan and then choose Select. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. In the Single sign-on section , under SAML Certificates , choose Download for Federation Metadata XML. Choose Test this application.
In each environment, Hydro manages a single MSK cluster that hosts multiple tenants with differing workload requirements. To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits. The following figure shows an example of a test cluster’s performance metrics.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and test data sources. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. On your project, in the navigation pane, choose Data. Choose Next.
The solution for this post is hosted on GitHub. Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. This is the bucket where you host all of your DAGs for your environment. [1.b]
This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
For the client to resolve DNS queries for the custom domain, an Amazon Route 53 private hosted zone is used to host the DNS records, and is associated with the client’s VPC to enable DNS resolution from the Route 53 VPC resolver. The Kafka client uses the custom domain bootstrap address to send a get metadata request to the NLB.
This means the data files in the data lake aren’t modified during the migration and all Apache Iceberg metadata files (manifests, manifest files, and table metadata files) are generated outside the purview of the data. In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. This has serious implications for software testing, versioning, deployment, and other core development processes.
In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering. The policies attached to the Amazon MWAA role have full access and must only be used for testing purposes in a secure test environment. secretsmanager ).
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. Your Chance: Want to test a professional analytics software?
After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. Subscribe to the unstructured data asset Now that you have the custom subscription workflow in place, you can test the workflow by subscribing to the unstructured data asset. Enter a name for the asset. Delete the Lambda function.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. The onboarding of producers is facilitated by sharing metadata, whereas the onboarding of consumers is based on granting permission to access this metadata. Test access using Athena queries in the consumer account.
There were also a host of other non-certified technical skills attracting pay premiums of 17% or more, way above those offered for certifications, and many of them centered on management, methodologies and processes or broad technology categories rather than on particular tools.
For customers to gain the maximum benefits from these features, Cloudera best practice reflects the success of thousands of -customer deployments, combined with release testing to ensure customers can successfully deploy their environments and minimize risk. Traditional data clusters for workloads not ready for cloud. Networking .
The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. For the template and setup information, refer to Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator. We use two datasets in this post.
BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). Manually upgrading, testing, and deploying over 5,000 jobs every few quarters was time consuming, error prone, costly, and not sustainable. It retrieves the specified files and available metadata to show on the UI.
The framework is generic and extensible enough to allow injecting new classes of failures over time and writing a suite of automated test cases to validate system behavior against the newly defined failure class. Such a targeted test case should also have a well-defined outcome that the test can validate without manual analysis.
Finally we also recommend that you take a full backup of your cluster configurations, metadata, other supporting details, and backend databases. After Ambari has been upgraded, download the cluster blueprints with hosts. Post-upgrade steps include application upgrade testing, validations, configuration and tuning.
Create an Amazon Route 53 public hosted zone such as mydomain.com to be used for routing internet traffic to your domain. For instructions, refer to Creating a public hosted zone. Request an AWS Certificate Manager (ACM) public certificate for the hosted zone. hosted_zone_id – The Route 53 public hosted zone ID.
Public cloud support: Many CSPs use hyperscalers like AWS to host their 5G network functions, which requires automated deployment and lifecycle management. Hybrid cloud support: Some network functions must be hosted on a private data center, but that also the requires ability to automatically place network functions dynamically.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. These datasets are distributed across the world and hosted for public use. Data scientists have access to the Jupyter notebook hosted on SageMaker. The OpenSearch Service domain stores metadata on the datasets connected at the Regions.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. This separation means changes can be tested thoroughly before being deployed to live operations. The overall structure can be represented in the following figure.
Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. These tables are the metadata representation of the customer tables.
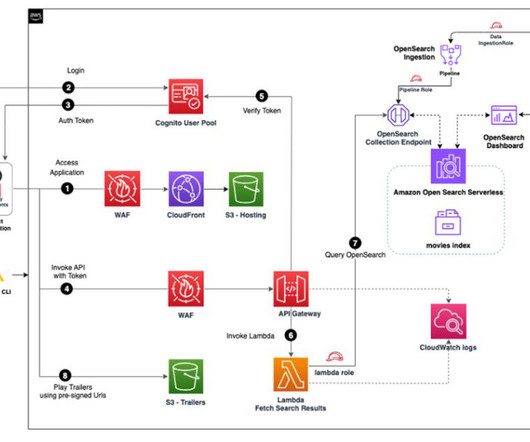
The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
Two private subnets are used to set up the Amazon MWAA environment, and the third private subnet is used to host the AWS Lambda authorizer function. Review the metadata about your certificate and choose Import. Note the values for App Federation Metadata Url and Login URL. Choose Next. Choose Review and import. Choose Save.
Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Along the way, metadata is collected, organized, and maintained to help debug and ensure data integrity. One common way to test market sentiment is to gather information directly from customers. Survey CTO.
With the new REST API, you can now invoke DAG runs, manage datasets, or get the status of Airflow’s metadata database, trigger, and scheduler—all without relying on the Airflow web UI or CLI. Args: region (str): AWS region where the MWAA environment is hosted. Args: region (str): AWS region where the MWAA environment is hosted.
The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data. Test the feature To test this feature, run the producer DAG. Test the feature Upload the four sample text files from the local data folder to an S3 bucket data folder. Run the dynamic_task_mapping DAG.
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. Select hosts for Active and Passive KTS servers. Data in the file is encrypted with DEK.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake.
This means the creation of reusable data services, machine-readable semantic metadata and APIs that ensure the integration and orchestration of data across the organization and with third-party external data. This means having the ability to define and relate all types of metadata.
FINRA centralizes all its data in Amazon Simple Storage Service (Amazon S3) with a remote Hive metastore on Amazon Relational Database Service (Amazon RDS) to manage their metadata information. Navigate to the side menu Virtual clusters , then select the HiveDemo cluster , You can see an entry for the SparkSQL test job.
Download the Gartner® Market Guide for Active Metadata Management 1. With this expanded observability, incidents can be prevented in the design phase or identified in the implementation and testing phase to reduce maintenance costs and achieve higher productivity.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Apache Hive, Apache Spark, Presto, and Trino can all use a Hive Metastore to retrieve metadata to run queries.
To develop your disaster recovery plan, you should complete the following tasks: Define your recovery objectives for downtime and data loss (RTO and RPO) for data and metadata. Test out the disaster recovery plan by simulating a failover event in a non-production environment. Choose your hosted zone. Choose your hosted zone.
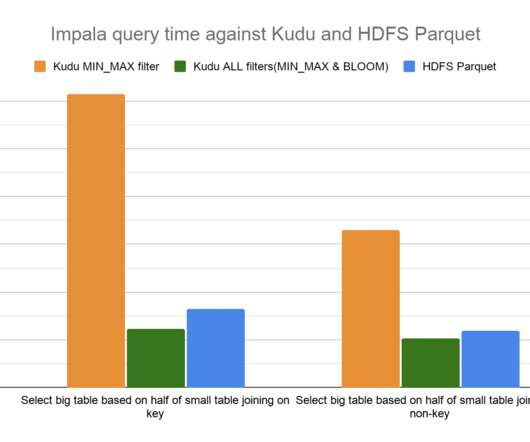
A Bloom filter is a space-efficient probabilistic data structure used to test set membership with a possibility of false-positive matches. Step 3 is the heaviest since it involves reading the entire big table and could involve heavy network IO if the worker and the nodes hosting the big table are not on the same server. Bloom filter.
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. Common Crawl data The Common Crawl raw dataset includes three types of data files: raw webpage data (WARC), metadata (WAT), and text extraction (WET).
After the data lands in Amazon S3, smava uses the AWS Glue Data Catalog and crawlers to automatically catalog the available data, capture the metadata, and provide an interface that allows querying all data assets. Evolution of the data platform requirements smava started with a single Redshift cluster to host all three data stages.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content