This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Although Amazon DataZone automates subscription fulfillment for structured data assetssuch as data stored in Amazon Simple Storage Service (Amazon S3), cataloged with the AWS Glue Data Catalog , or stored in Amazon Redshift many organizations also rely heavily on unstructureddata. Enter a name for the asset.
In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines. The extensive pre-trained knowledge of the LLMs enables them to effectively process and interpret even unstructureddata. Robert bridges tech and business, advocating user-centric digitization.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). The company is expanding its partnership with Collibra to integrate Collibra’s AI Governance platform with SAP data assets to facilitate data governance for non-SAP data assets in customer environments. “We
We use leading-edge analytics, data, and science to help clients make intelligent decisions. We developed and host several applications for our customers on Amazon Web Services (AWS). These embeddings, along with metadata such as the document ID and page number, are stored in OpenSearch Service.
A data lake is a centralized repository that you can use to store all your structured and unstructureddata at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. On the navigation pane, select Crawlers.
Application Logic: Application logic refers to the type of data processing, and can be anything from analytical or operational systems to data pipelines that ingest data inputs, apply transformations based on some business logic and produce data outputs.
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. Less data gets decompressed, deserialized, loaded into memory, run through the processing, etc.
While Cloudera CDH was already a success story at HBL, in 2022, HBL identified the need to move its customer data centre environment from Cloudera’s CDH to Cloudera Data Platform (CDP) Private Cloud to accommodate growing volumes of data. Smooth, hassle-free deployment in just six weeks.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. . public, private, hybrid cloud)?
Additionally, it is vital to be able to execute computing operations on the 1000+ PB within a multi-parallel processing distributed system, considering that the data remains dynamic, constantly undergoing updates, deletions, movements, and growth.
Hundreds of built-in processors make it easy to connect to any application and transform data structures or data formats as needed. Since it supports both structured and unstructureddata for streaming and batch integrations, Apache NiFi is quickly becoming a core component of modern data pipelines. and later).
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. Each product contains metadata including the ID, current stock, name, category, style, description, price, image URL, and gender affinity of the product.
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. In addition to determining which dataset should be used, cleansing and processing the data to the fine-tuning’s specific need is required. It is continuously updated.
Content Enrichment and Metadata Management. The value of metadata for content providers is well-established. When that metadata is connected within a knowledge graph, a powerful mechanism for content enrichment is unlocked. Ontotext Platform can be employed for a number of applications within an enterprise.
Organizations are collecting and storing vast amounts of structured and unstructureddata like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
You can take all your data from various silos, aggregate that data in your data lake, and perform analytics and machine learning (ML) directly on top of that data. You can also store other data in purpose-built data stores to analyze and get fast insights from both structured and unstructureddata.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructureddata at any scale and in various formats.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structured data and files/unstructureddata to the CDP cloud of their choice easily. Understanding the data sets to be replicated from the CDH Cluster.
DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructureddata (i.e. data best served through Apache Solr). Coordinates distribution of data and metadata, also known as shards.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. The blend of our technologies provides the perfect environment for content and data management applications in many knowledge-intensive enterprises.
To overcome these issues, Orca decided to build a data lake. A data lake is a centralized data repository that enables organizations to store and manage large volumes of structured and unstructureddata, eliminating data silos and facilitating advanced analytics and ML on the entire data.
Perhaps one of the most significant contributions in data technology advancement has been the advent of “Big Data” platforms. Historically these highly specialized platforms were deployed on-prem in private data centers to ensure greater control , security, and compliance. OpEx savings and probable ROI once migrated.
They define DSPM technologies this way: “DSPM technologies can discover unknown data and categorize structured and unstructureddata across cloud service platforms. In it they provide recommendations for getting started with DSPM and important considerations for DSPM solutions.
It would be unlikely that the US would take any action on using the open-source R1 or V3 models as long as they were hosted on US-based servers. So far, Americas issues with Chinese technology have mainly been based around storing American-based data on overseas servers, Park explained. So, how to deploy DeepSeeks models?
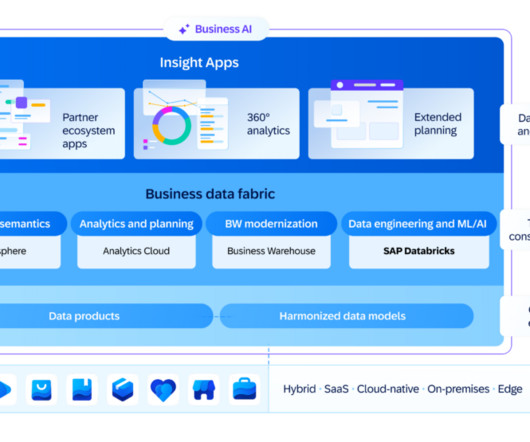
Business Data Cloud (BDC) consists of multiple existing and new services built by SAP and its partners: Object store which is an OEM from Databricks Databricks Data Engineering and AI/ML Tools SAP Datasphere SAP BW 7.5 Moreover, BARC research also shows that the importance of unstructureddata is also growing in importance.
This configuration allows you to augment your sensitive on-premises data with cloud data while making sure all data processing and compute runs on-premises in AWS Outposts Racks. Additionally, Oktank must comply with data residency requirements, making sure that confidential data is stored and processed strictly on premises.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content