This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Monte Carlo Data — Data reliability delivered. Data breaks. Observe, optimize, and scale enterprise data pipelines. . Validio — Automated real-time data validation and quality monitoring. . GitHub – A provider of Internet hosting for software development and version control using Git.
Without the existence of dashboards and dashboard reporting practices, businesses would need to sift through colossal stacks of unstructureddata, which is both inefficient and time-consuming. With such dashboards, users can also customize settings, functionality, and KPIs to optimize their dashboards to suit their specific needs.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. An example is Dell Technologies Enterprise Data Management.
Like many organizations, Indeed has been using AI — and more specifically, conventional machine learning models — for more than a decade to bring improvements to a host of processes. Asgharnia and his team built the tool and host it in-house to ensure a high level of data privacy and security. His own company is one example.
Not only does it support the successful planning and delivery of each edition of the Games, but it also helps each successive OCOG to develop its own vision, to understand how a host city and its citizens can benefit from the long-lasting impact and legacy of the Games, and to manage the opportunities and risks created.
Define a game-changing LLM strategy At a recent Coffee with Digital Trailblazers I hosted, we discussed how generative AI and LLMs will impact every industry. This opportunity is greater today because of generative AI, especially when CIOs centralize unstructureddata in an LLM and enable service agents to ask and answer customers’ questions.
As a result, utilities can improve uptime for their customers while optimizing operations to keep costs low. Read about unstructureddata storage solutions and find out how they can enable AI technology. In addition, companies use AI for proactive grid management and predictive maintenance that helps prevent outages.
We use leading-edge analytics, data, and science to help clients make intelligent decisions. We developed and host several applications for our customers on Amazon Web Services (AWS). Neptune ingests both structured and unstructureddata, simplifying the process to retrieve content across different sources and formats.
With the rise of highly personalized online shopping, direct-to-consumer models, and delivery services, generative AI can help retailers further unlock a host of benefits that can improve customer care, talent transformation and the performance of their applications.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. . public, private, hybrid cloud)?
There are a large number of tools used in AI, including versions of search and mathematical optimization, logic, methods based on probability and economics, and many others. This feature hierarchy and the filters that model significance in the data, make it possible for the layers to learn from experience.
And, as industrial, business, domestic, and personal Internet of Things devices become increasingly intelligent, they communicate with each other and share data to help calibrate performance and maximize efficiency. The result, as Sisense CEO Amir Orad wrote , is that every company is now a data company.
To accomplish this, we will need additional data center space, more storage disks and nodes, the ability for the software to scale to 1000+PB of data, and increased support through additional compute nodes and networking bandwidth. Focus on scalability.
Organizations are collecting and storing vast amounts of structured and unstructureddata like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
Hundreds of built-in processors make it easy to connect to any application and transform data structures or data formats as needed. Since it supports both structured and unstructureddata for streaming and batch integrations, Apache NiFi is quickly becoming a core component of modern data pipelines.
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. To build a SQL query, one must describe the data sources involved and the high-level operations (SELECT, JOIN, WHERE, etc.)
This blog post will present a simple “hello world” kind of example on how to get data that is stored in S3 indexed and served by an Apache Solr service hosted in a Data Discovery and Exploration cluster in CDP. This is automatically set on hosts with a Solr Server or Gateway role in Cloudera Manager.
In the article, he pointed to a pretty fascinating trend: “Experian has predicted that the CDO position will become a standard senior board-level role by 2020, bringing the conversation around data gathering, management, optimization, and security to the C-level.” We love that data is moving permanently into the C-Suite.
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. Cold storage is optimized to store infrequently accessed or historical data.
To overcome these issues, Orca decided to build a data lake. A data lake is a centralized data repository that enables organizations to store and manage large volumes of structured and unstructureddata, eliminating data silos and facilitating advanced analytics and ML on the entire data.
DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructureddata (i.e. data best served through Apache Solr). What does DDE entail? Get your DDE instance up and running.
It helps identify energy or carbon hotspots to develop an optimization roadmap. This varies based on workload characteristics; for instance, in the media or streaming industry, data transmission over the network and storing large unstructureddata sets consume considerable energy.
Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets. When it comes to data movement outside the boundaries of Data Products (i.e.,
Perhaps one of the most significant contributions in data technology advancement has been the advent of “Big Data” platforms. Historically these highly specialized platforms were deployed on-prem in private data centers to ensure greater control , security, and compliance. Streaming data analytics. . There it is.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructureddata at any scale and in various formats.
Misconception 3: All data warehouse migrations are the same, irrespective of vendors While migrating to the cloud, CTOs often feel the need to revamp and “modernize” their entire technology stack – including moving to a new cloud data warehouse vendor.
Businesses wanted a way to make pie and not an in-depth understanding of forward-chaining, inferential explosion or SPARQL optimizations. Machine learning coupled with knowledge graphs is already collecting, categorizing, tagging and adding the needed structure to the endless (and useless) swathes of unstructureddata.
Specifically, the busy hour simulation clearly identified that 95% of the legacy data warehouse queries could run on Hive LLAP with minor tweaks. By sustaining 30 Queries per Second (QPS) right off the bat, SMG was confident Hive LLAP could support the required concurrency with just a few optimizations. .
It was hosted by Ashleigh Faith, Founder at IsA DataThing, and featured James Buonocore, Business Consultant at EPAM, Lance Paine, and Gregory De Backer CEO at Cognizone. Krasimira touched upon the ways knowledge graphs can harness unstructureddata and enhance it with semantic metadata.
Improved data visibility and understanding : erwin Data Modeler offers intuitive visualization tools that make complex data relationships easy to interpret, fostering better decision-making across the organization. Improved Data Visibility and Understanding User Interface Enhancements – erwin Data Modeler 14.0
This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. The blend of our technologies provides the perfect environment for content and data management applications in many knowledge-intensive enterprises.
IBM® watsonx ™ AI and data platform, along with its suite of AI assistants, is designed to help scale and accelerate the impact of AI using trusted data throughout the business. The most common insurance use cases include optimizing processes that require processing large documents and large blocks of text or images.
This is partly because integrating and moving data is not the only problem. The data itself is stored in a way that is not optimal for extracting insight. Unlocking additional value from data requires context, relationships, and structure, none of which are present in the way most organizations store their data today.
An online hospitality company uses data science to ensure diversity in its hiring practices, improve search capabilities and determine host preferences, among other meaningful insights. The company made its data open-source, and trains and empowers employees to take advantage of data-driven insights.
They define DSPM technologies this way: “DSPM technologies can discover unknown data and categorize structured and unstructureddata across cloud service platforms. This accessibility of data is vital to business growth, but has also resulted in a significant increase in risk.
How much will the bank’s bottom line be impacted depends on a host of unknowns. Better Forecasting and Optimization. They also have to assess loss forecasting and reserving based on new data sources. Improving bottom lines with AI-powered upsell and cross-sell suggestions also becomes possible. Learn MORE.
Maximizing the potential of data According to Deloitte’s Q3 state of generative AI report, 75% of organizations have increased spending on data lifecycle management due to gen AI. When I came into the company last November, we went through a data modernization with AWS,” Bostrom says. “We You’ve heard of network as code?”
Assuming the data platform roadmap aligns with required technical capabilities, this may help address downstream issues related to organic competencies versus bigger investments in acquiring competencies. The same would be true for a host of other similar cloud data platforms (Databricks, Azure Data Factory, AWS Redshift).
This configuration allows you to augment your sensitive on-premises data with cloud data while making sure all data processing and compute runs on-premises in AWS Outposts Racks. Additionally, Oktank must comply with data residency requirements, making sure that confidential data is stored and processed strictly on premises.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


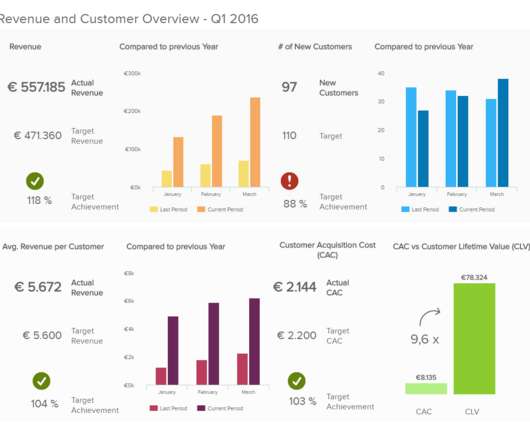











































Let's personalize your content