This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
This post focuses on introducing an active-passive approach using a snapshot and restore strategy. Snapshot and restore in OpenSearch Service The snapshot and restore strategy in OpenSearch Service involves creating point-in-time backups, known as snapshots , of your OpenSearch domain.
in Amazon OpenSearch Service , we introduced Snapshot Management , which automates the process of taking snapshots of your domain. Snapshot Management helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards).
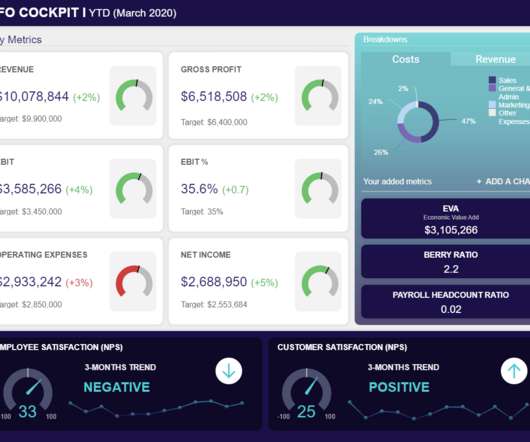
Serving as a central, interactive hub for a host of essential fiscal information, CFO dashboards host dynamic financial KPIs and intuitive analytical tools, as well as consolidate data in a way that is digestible and improves the decision-making process. We offer a 14-day free trial. Benefit from great CFO dashboards & reports!
For more information, refer SQL models. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. Tests – These are assertions you make about your models and other resources in your dbt project (such as sources, seeds, and snapshots). For more information, refer to Redshift set up.
With built-in features such as automated snapshots and cross-Region replication, you can enhance your disaster resilience with Amazon Redshift. Amazon Redshift supports two kinds of snapshots: automatic and manual, which can be used to recover data. Snapshots are point-in-time backups of the Redshift data warehouse.
If you apply that same logic to the financial sector or a finance department, it’s clear that financial reporting tools could serve to benefit your business by giving you a more informed snapshot of your activities. Exclusive Bonus Content: Your cheat sheet on reporting in finance! Let’s start by exploring a financial reporting definition.
For instructions to create an OpenSearch Service domain, refer to Getting started with Amazon OpenSearch Service. Under Generate the link as , select Snapshot and choose Copy iFrame code. There are different options available to host the web server, such as Amazon EC2 or Amazon S3. The domain creation takes around 15–20 minutes.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. For instructions, refer to create key-pair here.
Example: Recrawl Logic within Google search Google search works because our software has previously crawled many billions of web pages, that is, scraped and snapshotted each one. These snapshots comprise what we refer to as our search index. This results in a poor user experience.
Redshift Test Drive is a tool hosted on the GitHub repository that let customers evaluate which data warehouse configurations options are best suited for their workload. Refer to the Workload Replicator README and the Configuration Comparison README for more detailed instructions to execute a replay using the respective tool.
For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). You can install OpenSearch Benchmark directly on a host running Linux or macOS , or you can run OpenSearch Benchmark in a Docker container on any compatible host.
Sometimes referred to as nested charts, they are especially useful in tables, where you can access additional drilldown options such as aggregated data for categories/breakdowns (e.g. They all host invaluable data for your business. Each dashboard created should be a live snapshot of your business. 10) Dashboard Widget Linking.
Refer to the Amazon RDS for Db2 pricing page for instances supported. Are there any constraints on the number of databases that can be hosted on an instance? If you require hosting multiple databases per instance, connect with an IBM or AWS representative to discuss your needs and request a proof of concept. 13.
The term business intelligence often also refers to a range of tools that provide quick, easy-to-digest access to insights about an organization’s current state, based on available data. BI aims to deliver straightforward snapshots of the current state of affairs to business managers.
Redshift Test Drive also provides additional features such as a self-hosted analysis UI and the ability to replicate external objects that a Redshift workload may interact with. Compare replay performance Redshift Test Drive also provides the ability to compare the replay runs visually using a self-hosted UI tool.
A procurement report allows an organization to demonstrate how its procurement activities deliver value for money, contribute to the realization of its broader goals and objectives, and provide a panoramic snapshot of the effectiveness of its procurement strategy. There are a host of benefits to procurement reporting.
Data intelligence refers to every analytical tool and activity based on forming a better understanding of the information and data a company (or business) collects, analyzing and utilizing it with the goal of enhancing and evolving business processes. Download right here our guide, and find out everything you need to know! click to enlarge**.
Apache HBase is a scalable, distributed, column-oriented data store that provides real-time read/write random access to very large datasets hosted on Hadoop Distributed File System (HDFS). In this method, you prepare the data for migration, and then set up the replication plugin to use a snapshot to migrate your data. using CM 6.3.0
Frequent materialized view refreshes on top of constantly changing base tables due to streamed data can lead to snapshot isolation errors. For the template and setup information, refer to Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator. We use two datasets in this post.
Data Vault overview For a brief review of the core Data Vault premise and concepts, refer to the first post in this series. For more information, refer to Amazon Redshift database encryption. Automated snapshots retain all of the data required to restore a data warehouse from a snapshot. model in Amazon Redshift.
To learn more about how to implement your AWS Glue job scripts locally, refer to Develop and test AWS Glue version 3.0 To learn more about how to achieve unit testing locally, refer to Develop and test AWS Glue version 3.0 jobs locally using a Docker container. Test In the testing phase, you check the implementation for bugs.
This solution uses Amazon Aurora MySQL hosting the example database salesdb. Valid values for OP field are: c = create u = update d = delete r = read (applies to only snapshots) The following diagram illustrates the solution architecture: The solution workflow consists of the following steps: Amazon Aurora MySQL has a binary log (i.e.,
Here, we’ll explore customer data management, offering a host of practical tips to help you embrace the power of customer data management software the right way. Centered on leveraging consumer insights to improve your strategies and communications by using a highly data-driven process can also be referred to as Customer Intelligence (CI).
Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. Solution overview For our example use case, streaming data is coming through Amazon Kinesis Data Streams , and reference data is managed in MySQL.
During the upgrade process, Amazon MWAA captures a snapshot of your environment metadata; upgrades the workers, schedulers, and web server to the new Airflow version; and finally restores the metadata database using the snapshot, backing it with an automated rollback mechanism.
This metric is also referred to as “EBIT”, for “earnings before interest and tax”. This particular monthly financial report template provides you with an overview of how efficiently you are spending your capital while providing a snapshot of the main metrics on your balance sheet. The higher the Net Profit Margin, the better.
It’s clear that there are a host of tangible benefits as stated in our 8 points above, and many of them will have a positive impact on other areas of the business. To ensure that you get optimum value from certain KPIs and metrics, you should set measurement time parameters that will give you a comprehensive snapshot of averages and trends.
To create it, refer to Tutorial: Get started with Amazon EC2 Windows instances. To download and install AWS SCT on the EC2 instance that you created, refer to Installing, verifying, and updating AWS SCT. For more information about bucket names, refer to Bucket naming rules. to indicate local host. Choose Create bucket.
Although this post uses an Aurora PostgreSQL database hosted on AWS as the data source, the solution can be extended to ingest data from any of the AWS DMS supported databases hosted on your data centers. Let’s refer to this S3 bucket as the raw layer. Refer to Submitting EMR Serverless jobs from Airflow for additional details.
Crawlers support schema merging across all snapshots and update the latest metadata file location in the Data Catalog that AWS analytical engines can directly use. For more details, refer to Creating Apache Iceberg tables. The customer wants to make product data accessible to analyst personas for interactive analysis using Athena.
In DevOps , the concept of observability has evolved to refer to the end-to-end visibility of a system state as dictated by telemetry data. Kubernetes tends to capture data “snapshots,” or information captured at a specific point in the lifecycle. Rollouts A rollout is a Kubernetes deployment modification.
Top line revenue refers to the total value of sales of an organization’s services or products. Druid hosted on Amazon Elastic Compute Cloud (Amazon EC2) integrates with the Kinesis data stream for streaming ingestion and allows users to run slice-and-dice OLAP queries. Operational dashboards are hosted on Grafana integrated with Druid.
This post presents a reference architecture for real-time queries and decision-making on AWS using Amazon Kinesis Data Analytics for Apache Flink. For more information, refer to Flink Serialization Tuning Vol. The team then will host business logic provided by other departments in Klarna such as Fraud Prevention.
For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform. The following figure shows a daily query volume snapshot (queries per day and queued queries per day, which waited a minimum of 5 seconds). The following figure shows a daily usage KPI.
You can refer to Table & SQL Connectors for more information. Refer to Catalogs for more information. For more information, refer to Creating catalogs and using catalogs and Catalogs. For more information, refer to Create Catalog. Refer to Configuring MySQL binary logging for more information.
HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3) , and can host very large tables with billions of rows and millions of columns. And during HBase migration, you can export the snapshot files to S3 and use them for recovery. Using BucketCache to improve read performance after migration.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content