This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Kevin Grayling, CIO, Florida Crystals Florida Crystals It’s ASR that had the more modern SAP installation, S/4HANA 1709, running in a virtual private cloud hosted by Virtustream, while its parent languished on SAP Business Suite. One of those requirements was to move out of its hosting provider data center and into a hyperscaler’s cloud.
This allows developers to test their application with a Kafka cluster that has the same configuration as production and provides an identical infrastructure to the actual environment without needing to run Kafka locally. A bastion host instance with network access to the MSK Serverless cluster and SSH public key authentication.
For customers to gain the maximum benefits from these features, Cloudera best practice reflects the success of thousands of -customer deployments, combined with release testing to ensure customers can successfully deploy their environments and minimize risk. Traditional data clusters for workloads not ready for cloud.
You can now test the newly created application by running the following command: npm run dev By default, the application is available on port 5173 on your local machine. For simplicity, we use the Hosting with Amplify Console and Manual Deployment options. The base application is shown in the workspace browser.
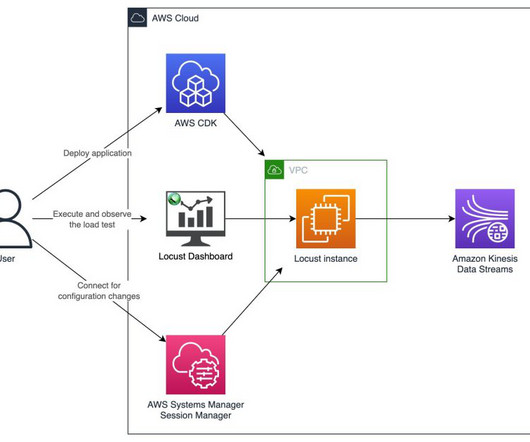
Building a streaming data solution requires thorough testing at the scale it will operate in a production environment. However, generating a continuous stream of test data requires a custom process or script to run continuously. In our testing with the largest recommended instance (c7g.16xlarge),
Most AI models decay overtime: This phenomenon, known more widely as model decay , refers to the declining quality of AI system results over time, as patterns in new data drift away from patterns learned in training data. Second is AI’s tremendous complexity. And last is the probabilistic nature of statistics and machine learning (ML).
dbt Cloud is a hosted service that helps data teams productionize dbt deployments. You’re now ready to sign in to both Aurora MySQL cluster and Amazon Redshift Serverless data warehouse and run some basic commands to test them. Choose Test Connection. Choose Next if the test succeeded. Choose Create.
Data preparation The two datasets are hosted as two Data Catalog tables, venue and event , in a project in Amazon SageMaker Unified Studio (preview), as shown in the following screenshots. To learn more, refer to Amazon Q data integration in AWS Glue. Next, the merged data is filtered to include only a specific geographic region.
Meanwhile, in December, OpenAIs new O3 model, an agentic model not yet available to the public, scored 72% on the same test. Mitre has also tested dozens of commercial AI models in a secure Mitre-managed cloud environment with AWS Bedrock. The data is kept in a private cloud for security, and the LLM is internally hosted as well.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and test data sources. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. To learn more, refer to Amazon SageMaker Unified Studio.
Refer to this developer guide to understand more about index snapshots Understanding manual snapshots Manual snapshots are point-in-time backups of your OpenSearch Service domain that are initiated by the user. Testing and development – You can use snapshots to create copies of your data for testing or development purposes.
Redshift Test Drive is a tool hosted on the GitHub repository that let customers evaluate which data warehouse configurations options are best suited for their workload. Generating and accessing Test Drive metrics The results of Amazon Redshift Test Drive can be accessed using an external schema for analysis of a replay.
In this post, we answer that question by using Redshift Test Drive , an open-source tool that lets you evaluate which different data warehouse configurations options are best suited for your workload. Redshift Test Drive uses this process of workload replication for two main functionalities: comparing configurations and comparing replays.
It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries. For more information, refer SQL models. When you run dbt test , dbt will tell you if each test in your project passes or fails.
In conversation with reporter Cade Metz, who broke the story, on the New York Times podcast The Daily , host Michael Barbaro called copyright violation “ AI’s Original Sin.” When readers see an AI Answer that references sources they trust, they take it as a trusted answer and may well take it at face value and move on.
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. If you’re a professional data scientist, you already have the knowledge and skills to test these models. Is autoML the bait for long-term model hosting? Get your results in a few hours.
Google, Facebook, Amazon, or a host of more recent Silicon Valley startupsemploy tens of thousands of workers. They can scaffold entire features in minutes, complete with tests and documentation. There are now hundreds of thousands of programmers doing this kind of supervisory work. People even took pride in their calligraphy.
You can use the flexible connector framework and search flow pipelines in OpenSearch to connect to models hosted by DeepSeek, Cohere, and OpenAI, as well as models hosted on Amazon Bedrock and SageMaker. Python The code has been tested with Python version 3.13. Execute that command before running the next script.
Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows. In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering. A VPC gateway endpointto Amazon S3.
To learn more about this process, refer to Enabling SAML 2.0 Select the Consumption hosting plan and then choose Select. On the Code + Test page, replace the sample code with the following code, which retrieves the users group membership, and choose Save. Test the SSO setup You can now test the SSO setup.
Refer to Getting started with Amazon OpenSearch Service to create a provisioned OpenSearch Service domain. arn: " arn:aws:kafka:us-west-2:XXXXXXXXXXXX:cluster/msk-prov-1/id " sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint # hosts: [ " [link] " ] aws: # Provide a Role ARN with access to the domain.
Business intelligence concepts refer to the usage of digital computing technologies in the form of data warehouses, analytics and visualization with the aim of identifying and analyzing essential business-based data to generate new, actionable corporate insights. Introduction To Business Intelligence Concepts. 2) The data warehouse.
Refer to How can I access OpenSearch Dashboards from outside of a VPC using Amazon Cognito authentication for a detailed evaluation of the available options and the corresponding pros and cons. For more information, refer to the AWS CDK v2 Developer Guide. For instructions, refer to Creating a public hosted zone.
This includes the creation of landing zones, defining the VPN, gateway connections, network policies, storage policies, hosting key services within a private subnet and setting up the right IAM policies (resource policies, setting up the organization, deletion policies). The choice of strategy depends on the state of the workload.
Let’s look at a few tests we performed in a stream with two shards to illustrate various scenarios. In the first test, we ran a producer to write batches of 30 records, each being 100 KB, using the PutRecords API. For our test scenario, we can only see each key being used one time because we used a new UUID for each record.
For instructions to create an OpenSearch Service domain, refer to Getting started with Amazon OpenSearch Service. f%2Cvalue%3A900000)%2Ctime%3A(from%3Anow-24h%2Cto%3Anow))" height="800" width="100%"> Host the HTML code The next step is to host the index.html file. The domain creation takes around 15–20 minutes.
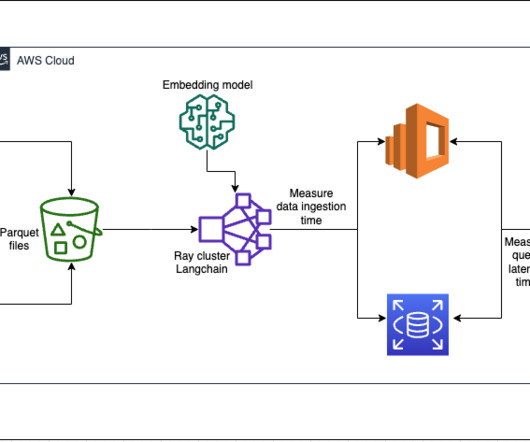
For more information on the choice of index algorithm, refer to Choose the k-NN algorithm for your billion-scale use case with OpenSearch. Ray cluster for ingestion and creating vector embeddings In our testing, we found that the GPUs make the biggest impact to performance when creating the embeddings. zst`; do zstd -d $F; done rm *.zst
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data.
For more details, refer to Tutorial: Configure a cross-realm trust with an Active Directory domain. In this post, we dive deep into the Amazon EMR LDAP authentication, showing how the authentication flow works, how to retrieve and test the needed LDAP configurations, and how to confirm an EMR cluster is properly LDAP integrated.
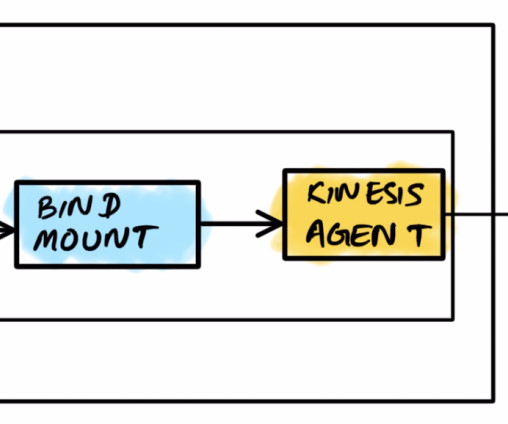
We also avoid the implementation details and packaging process of our test data generation application, referred to as the producer. After the image is built, it should be pushed to a container registry like Amazon ECR so that you can reference it in the next section. southeast-2.amazonaws.com/producer:latest", southeast-2.amazonaws.com/kinesis-agent:latest",
To learn more about working with events using EventBridge, refer to Events via Amazon EventBridge default bus. We refer to this role as the instance-role throughout the post. We refer to this role as the environment-role throughout the post. Delete the S3 bucket that hosted the unstructured asset. Delete the IAM roles.
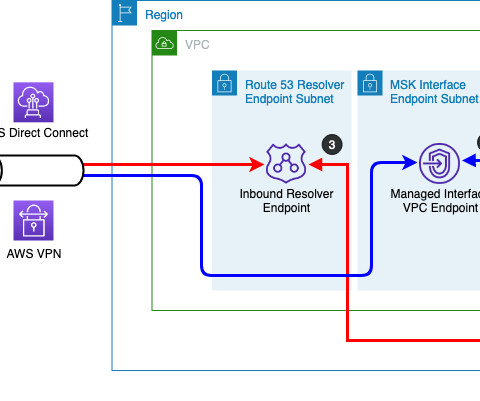
The inbound resolver endpoint performs DNS resolution by forwarding the query to the private hosted zone that was created along with the MSK Serverless cluster. Refer to Network-to-Amazon VPC connectivity options for more information. Test the DNS resolution DNS (Domain Name System) uses TCP/UDP port 53. southeast-2.amazonaws.com.
The workflow steps are as follows: The producer DAG makes an API call to a publicly hosted API to retrieve data. Test the feature To test this feature, run the producer DAG. How dynamic task mapping works Let’s see an example using the reference code available in the Airflow documentation. using the vectorcall protocol.
For the client to resolve DNS queries for the custom domain, an Amazon Route 53 private hosted zone is used to host the DNS records, and is associated with the client’s VPC to enable DNS resolution from the Route 53 VPC resolver. The Route 53 private hosted zone is not a required part of the solution. example.com DNS.3
Refer to IAM Identity Center identity source tutorials for the IdP setup. Generate the client secret and set sign-in redirect URL and sign-out URL to [link] (we will host the Streamlit application locally on port 8501). For more details, refer to Creating a workgroup with a namespace. IAM Identity Center enabled. and v3.12.2.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. Test access to the producer cataloged Amazon S3 data using EMR Serverless in the consumer account. Test access using Athena queries in the consumer account.
If you’re new to OpenSearch Serverless, refer to Log analytics the easy way with Amazon OpenSearch Serverless for details on how to set up your collection. For other distros, refer to the artifacts.) For other distros, refer to the artifacts.) Create an OpenSearch Serverless collection. cd logstash-8.4.0/ cd logstash-8.4.0/
” Software as a service (SaaS) is a software licensing and delivery paradigm in which software is licensed on a subscription basis and is hosted centrally. It gives the customer entire shopping cart software and hosting infrastructure, allowing enterprises to launch an online shop in a snap. 5) Make a final analysis.
For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). You can install OpenSearch Benchmark directly on a host running Linux or macOS , or you can run OpenSearch Benchmark in a Docker container on any compatible host.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. For instructions, refer to create key-pair here.
Test out the disaster recovery plan by simulating a failover event in a non-production environment. For additional details, refer to Automated snapshots. For additional details, refer to Manual snapshots. To learn more about setting up AWS Backup for Amazon Redshift, refer to Amazon Redshift backups.
This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines. If you’d like to learn more about other workflows in this solution, please refer to the implementation guide.
Refer to Creating an Apache Airflow web login token for more details. Args: region (str): AWS region where the MWAA environment is hosted. Args: region (str): AWS region where the MWAA environment is hosted. To learn more about the Airflow REST API and its various endpoints, refer to the Airflow documentation.
Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS. For more information, refer to Guidance for Distributed Computing with Cross Regional Dask on AWS and the GitHub repo for open-source code. These datasets are distributed across the world and hosted for public use.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content