This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance. Understanding the importance of data […] The post What is DataQuality in Machine Learning?
We suspected that dataquality was a topic brimming with interest. The responses show a surfeit of concerns around dataquality and some uncertainty about how best to address those concerns. Key survey results: The C-suite is engaged with dataquality. Dataquality might get worse before it gets better.
This article was published as a part of the DataScience Blogathon Overview Running data projects takes a lot of time. Poor data results in poor judgments. Running unit tests in datascience and data engineering projects assures dataquality. Table of content Introduction […].
Datascience has become an extremely rewarding career choice for people interested in extracting, manipulating, and generating insights out of large volumes of data. To fully leverage the power of datascience, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with dataquality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor dataquality is holding back enterprise AI projects.
Over the next one to three years, 84% of businesses plan to increase investments in their datascience and engineering teams, with a focus on generative AI, prompt engineering (45%), and datascience/data analytics (44%), identified as the top areas requiring more AI expertise.
This article was published as a part of the DataScience Blogathon. Choosing the best appropriate activation function can help one get better results with even reduced dataquality; hence, […]. The post Sigmoid Function: Derivative and Working Mechanism appeared first on Analytics Vidhya.
Incorrect or unclean data leads to false conclusions. The time you take to understand and clean the data is vital to the outcome and quality of the results. DataQuality always takes the win against complex fancy algorithms.
This article was published as a part of the DataScience Blogathon. Introduction In machine learning, the data is an essential part of the training of machine learning algorithms. The amount of data and the dataquality highly affect the results from the machine learning algorithms.
Piperr.io — Pre-built data pipelines across enterprise stakeholders, from IT to analytics, tech, datascience and LoBs. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs data workflows. Genie — Distributed big data orchestration service by Netflix. Data breaks.
An education in datascience can help you land a job as a data analyst , data engineer , data architect , or data scientist. Here are the top 15 datascience boot camps to help you launch a career in datascience, according to reviews and data collected from Switchup.
Why is high-quality and accessible data foundational? The assumed value of data is a myth leading to inflated valuations of start-ups capturing said data. Generating data with a pre-specified analysis plan and running that analysis is good. Re-analyzing existing data is often very bad.”
Datascience is the sexy thing companies want. The data engineering and operations teams don't get much love. The organizations don’t realize that datascience stands on the shoulders of DataOps and data engineering giants. They know how to operate the big data frameworks. They're right.
SageMaker Lakehouse enables seamless data access directly in the new SageMaker Unified Studio and provides the flexibility to access and query your data with all Apache Iceberg-compatible tools on a single copy of analytics data. Having confidence in your data is key.
The integrated use of datascience and machine learning in healthcare has many applications for improving patient care, business processes and operations, and pharmaceuticals. But the healthcare industry faces considerable challenges in dataquality and infrastructure, compliance and governance, and upskilling.
How can systems thinking and datascience solve digital transformation problems? Understandably, organizations focus on the data and the technology since data retrieval is often viewed as a data problem. However, the thrust here is not to diminish datascience or data engineering.
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. The higher the criticality and sensitivity to data downtime, the more engineering and automation are needed.
Companies are no longer wondering if data visualizations improve analyses but what is the best way to tell each data-story. 2020 will be the year of dataquality management and data discovery: clean and secure data combined with a simple and powerful presentation. 1) DataQuality Management (DQM).
Data debt that undermines decision-making In Digital Trailblazer , I share a story of a private company that reported a profitable year to the board, only to return after the holiday to find that dataquality issues and calculation mistakes turned it into an unprofitable one.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and datascience. Datasphere is not just for data managers.
If you’re a conscientious data scientist, you’re going to clean up your data before using it to make models, predictions and recommendations. In the past, it’s been estimated that data scientists spend somewhere between 30% and 80% of their time just prepping and cleaning data. Data Supervision. Not really.
As model building become easier, the problem of high-qualitydata becomes more evident than ever. Even with advances in building robust models, the reality is that noisy data and incomplete data remain the biggest hurdles to effective end-to-end solutions. Data integration and cleaning.
Generative AI is rapidly transforming the datascience landscape. Its ability to create synthetic data promises exciting possibilities for data augmentation and improved model performance.
Just as Maslow identified a hierarchy of needs for people, data teams have a hierarchy of needs, beginning with data freshness; including volumes, schemas, and values; and culminating with lineage.
They recognize that the overemphasis on big data has created problems, so they have presented alternatives. DataScience Companies Focus on Optimal Data Utilization Rather than Just Emphasizing Data Scalability. Endor is a leading pioneer in datascience. appeared first on SmartData Collective.
By contrast, AI adopters are about one-third more likely to cite problems with missing or inconsistent data. The logic in this case partakes of garbage-in, garbage out : data scientists and ML engineers need qualitydata to train their models. This is consistent with the results of our dataquality survey.
Too much datascience for too little gain There are so many clients who just want to do AI, any AI, and haven’t carefully thought through the use cases. “Now we have to go back and audit everything,” he says. Fortunately, this problem was caught in time. “It
Data is critical for any business as it helps them make decisions based on trends, statistical numbers and facts. Due to this importance of data, datascience as a multi-disciplinary field developed. It utilizes scientific approaches, frameworks, algorithms, and procedures to extract insight from a massive amount of data.
How Long Does It Take to Learn DataScience Fundamentals?; Become a DataScience Professional in Five Steps; New Ways of Sharing Code Blocks for Data Scientists; Machine Learning Algorithms for Classification; The Significance of DataQuality in Making a Successful Machine Learning Model.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in datascience and for managing data infrastructure.
These rules are not necessarily “Rocket Science” (despite the name of this blog site), but they are common business sense for most business-disruptive technology implementations in enterprises. Clean it, annotate it, catalog it, and bring it into the data family (connect the dots and see what happens).
Regulators behind SR 11-7 also emphasize the importance of data—specifically dataquality , relevance , and documentation. While models garner the most press coverage, the reality is that data remains the main bottleneck in most ML projects. Gary Kazantsev on how “Datascience makes an impact on Wall Street”.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
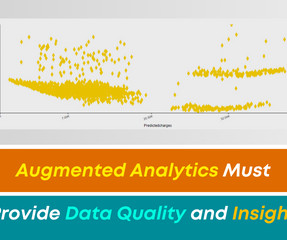
How Can I Ensure DataQuality and Gain Data Insight Using Augmented Analytics? There are many business issues surrounding the use of data to make decisions. One such issue is the inability of an organization to gather and analyze data.
And the worst part – data errors take the fun out of datascience. Remember your first datascience courses? You probably imagined your career would be about helping drive insights with data instead of having to sit in endless meetings discussing analytics errors and painstaking corrective actions.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
In order to help maintain data privacy while validating and standardizing data for use, the IDMC platform offers a DataQuality Accelerator for Crisis Response. Cloud Computing, Data Management, Financial Services Industry, Healthcare Industry
Therefore, the PM should consider the team that will reconvene whenever it is necessary to build out or modify product features that: ensure that inputs are present and complete, establish that inputs are from a realistic (expected) distribution of the data, and trigger alarms, model retraining, or shutdowns (when necessary).
Residual plots place input data and predictions into a two-dimensional visualization where influential outliers, data-quality problems, and other types of bugs often become plainly visible. Small residuals usually mean a model is right, and large residuals usually mean a model is wrong.
They conveniently store data in a flat architecture that can be queried in aggregate and offer the speed and lower cost required for big data analytics. On the other hand, they don’t support transactions or enforce dataquality. Each ETL step risks introducing failures or bugs that reduce dataquality. .
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content