This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We suspected that dataquality was a topic brimming with interest. The responses show a surfeit of concerns around dataquality and some uncertainty about how best to address those concerns. Key survey results: The C-suite is engaged with dataquality. Dataquality might get worse before it gets better.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and datascience. Datasphere is not just for data managers. As you would guess, maintaining context relies on metadata.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with dataquality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor dataquality is holding back enterprise AI projects.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
SageMaker Lakehouse enables seamless data access directly in the new SageMaker Unified Studio and provides the flexibility to access and query your data with all Apache Iceberg-compatible tools on a single copy of analytics data. Having confidence in your data is key.
What enables you to use all those gigabytes and terabytes of data you’ve collected? Metadata is the pertinent, practical details about data assets: what they are, what to use them for, what to use them with. Without metadata, data is just a heap of numbers and letters collecting dust. Where does metadata come from?
First, what active metadata management isn’t : “Okay, you metadata! Now, what active metadata management is (well, kind of): “Okay, you metadata! Data assets are tools. Metadata are the details on those tools: what they are, what to use them for, what to use them with. . Quit lounging around!
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in datascience and for managing data infrastructure.
These rules are not necessarily “Rocket Science” (despite the name of this blog site), but they are common business sense for most business-disruptive technology implementations in enterprises. Love thy data: data are never perfect, but all the data may produce value, though not immediately.
By contrast, AI adopters are about one-third more likely to cite problems with missing or inconsistent data. The logic in this case partakes of garbage-in, garbage out : data scientists and ML engineers need qualitydata to train their models. This is consistent with the results of our dataquality survey.
If you’re a conscientious data scientist, you’re going to clean up your data before using it to make models, predictions and recommendations. In the past, it’s been estimated that data scientists spend somewhere between 30% and 80% of their time just prepping and cleaning data. Data Supervision. Not really.
In order to help maintain data privacy while validating and standardizing data for use, the IDMC platform offers a DataQuality Accelerator for Crisis Response. Cloud Computing, Data Management, Financial Services Industry, Healthcare Industry
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
The data you’ve collected and saved over the years isn’t free. If storage costs are escalating in a particular area, you may have found a good source of dark data. Analyze your metadata. If you’ve yet to implement data governance, this is another great reason to get moving quickly.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Data fabric is an architecture that enables the end-to-end integration of various data pipelines and cloud environments through the use of intelligent and automated systems. The fabric, especially at the active metadata level, is important, Saibene notes.
They conveniently store data in a flat architecture that can be queried in aggregate and offer the speed and lower cost required for big data analytics. On the other hand, they don’t support transactions or enforce dataquality. Each ETL step risks introducing failures or bugs that reduce dataquality. .
Figure 1: Flow of actions for self-service analytics around data assets stored in relational databases First, the data producer needs to capture and catalog the technical metadata of the data asset. The producer also needs to manage and publish the data asset so it’s discoverable throughout the organization.
By 2023, ERP data will be the basis for 30% of AI-generated predictive analyses and forecasts. Through 2023, up to 10% of AI training data will be poisoned by benign or malicious actors. By 2024, 75% of organizations will have deployed multiple data hubs to drive mission-critical data and analytics sharing and governance.
Cloudera has been supporting data lakehouse use cases for many years now, using open source engines on open data and table formats, allowing for easy use of data engineering, datascience, data warehousing, and machine learning on the same data, on premises, or in any cloud.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Dataquality using table rollback.
Sources Data can be loaded from multiple sources, such as systems of record, data generated from applications, operational data stores, enterprise-wide reference data and metadata, data from vendors and partners, machine-generated data, social sources, and web sources.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data. Then, you transform this data into a concise format.
A couple of years ago we postulated that an organizations data and analytics platform, that sits at the heart of their digital business , comprises three core platforms or layers: Analytics/BI, datascience/ML and AI. Data Management. Data and Analytics Governance. Some aspects of DataQuality.
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. The business end-users were given a tool to discover data assets produced within the mesh and seamlessly self-serve on their data sharing needs.
Business users cannot even hope to prepare data for analytics – at least not without the right tools. Gartner predicts that, ‘data preparation will be utilized in more than 70% of new data integration projects for analytics and datascience.’ So, why is there so much attention paid to the task of data preparation?
For state and local agencies, data silos create compounding problems: Inaccessible or hard-to-access data creates barriers to data-driven decision making. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Towards DataScience ).
As they attempt to put machine learning models into production, datascience teams encounter many of the same hurdles that plagued data analytics teams in years past: Finding trusted, valuable data is time-consuming. Obstacles, such as user roles, permissions, and approval request prevent speedy data access.
Cloudera, a leader in big data analytics, provides a unified Data Platform for data management, AI, and analytics. Our customers run some of the world’s most innovative, largest, and most demanding datascience, data engineering, analytics, and AI use cases, including PB-size generative AI workloads.
This data supports all kinds of use cases within organizations, from helping production analysts understand how production is progressing, to allowing research scientists to look at the results of a set of treatments across different trials and cross-sections of the population.
Centralization of metadata. A decade ago, metadata was everywhere. Consequently, useful metadata was unfindable and unusable. We had data but no data intelligence and, as a result, insights remained hidden or hard to come by. This universe of metadata represents a treasure trove of connected information.
As Dan Jeavons DataScience Manager at Shell stated: “what we try to do is to think about minimal viable products that are going to have a significant business impact immediately and use that to inform the KPIs that really matter to the business”.
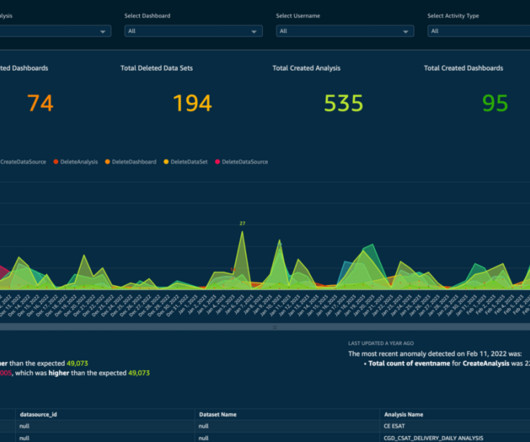
This dashboard helps our operations team and end customers improve the dataquality of key attribution and reduce manual intervention. This framework can be described as follows: Findable – Metadata and data should be easy to find for both humans and computers. Outside of work, Ameya is a professional pilot.
In this model, the centralized hub — Enterprise D&A — will provide the platform, security, and best practices, along with tracking and governance of data products. The spokes — Dow’s businesses and functions — will perform much of their own analytics and datascience.
Background The success of a data-driven organization recognizes data as a key enabler to increase and sustain innovation. The goal of a data product is to solve the long-standing issue of data silos and dataquality. The datascience algorithm Valentine is an effective tool for this.
The first one is: companies should invest more in improving their dataquality before doing anything else. You must master your metadata and make sure that everything is lined up. To make a big step forward with datascience, you first need to do that painful work.
Running on CDW is fully integrated with streaming, data engineering, and machine learning analytics. It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. Consideration of both data & metadata in the migration.
These new technologies and approaches, along with the desire to reduce data duplication and complex ETL pipelines, have resulted in a new architectural data platform approach known as the data lakehouse – offering the flexibility of a data lake with the performance and structure of a data warehouse.
Octopai can fully map the BI landscape and trace metadata movement in a mixed environment including complex multi-vendor landscapes. Octopai’s cloud-based offerings hasten data delivery and allow full automation to dramatically accelerate the entire BI data lifecycle.
The ultimate data organizational tool, letting any data user in your organization easily see what data assets you have and all the pertinent details about them, is a data catalog. Bonus tool: active metadata management. An active metadata management tool adds a maître d’ to self-serve analytics.
March 2015: Alation emerges from stealth mode to launch the first official data catalog to empower people in enterprises to easily find, understand, govern and use data for informed decision making that supports the business. May 2016: Alation named a Gartner Cool Vendor in their Data Integration and DataQuality, 2016 report.
Data privacy laws such as the GDPR in the EU, CCPA in California and PIPEDA in Canada have been enacted at the same time businesses are revitalizing efforts to establish dataquality, not just data volume. Poor dataquality costs organizations an average of $12.9 million each year [1] and $1.2 28, 2021. [2].
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content