This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Alation and Bigeye have partnered to bring data observability and dataquality monitoring into the data catalog. Read to learn how our newly combined capabilities put more trustworthy, qualitydata into the hands of those who are best equipped to leverage it. trillion each year due to poor dataquality.
Selecting the strategies and tools for validating datatransformations and data conversions in your data pipelines. Introduction Datatransformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Dataquality and governance: Dataquality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
Many large organizations, in their desire to modernize with technology, have acquired several different systems with various data entry points and transformation rules for data as it moves into and across the organization. Business terms and data policies should be implemented through standardized and documented business rules.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with data engineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. It’s a fluid situation.”
Organizations can’t afford to mess up their data strategies, because too much is at stake in the digital economy. How enterprises gather, store, cleanse, access, and secure their data can be a major factor in their ability to meet corporate goals. Here are some data strategy mistakes IT leaders would be wise to avoid.
It does this by helping teams handle the T in ETL (extract, transform, and load) processes. It allows users to write datatransformation code, run it, and test the output, all within the framework it provides. As part of their cloud modernization initiative, they sought to migrate and modernize their legacy data platform.
Instead, he suggests they put data governance in real-world scenarios to answer these questions: “What is the problem you believe data governance is the answer to?” Or “How would you recognize having effective data governance in place?”. The Benefits of erwin Data Intelligence. Where is it?
It’s paramount that organizations understand the benefits of automating end-to-end data lineage. Critically, it makes it easier to get a clear view of how information is created and flows into, across and outside an enterprise. The importance of end-to-end data lineage is widely understood and ignoring it is risky business.
The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Datatransformation. Microsoft Azure.
But to augment its various businesses with ML and AI, Iyengar’s team first had to break down data silos within the organization and transform the company’s data operations. Digitizing was our first stake at the table in our data journey,” he says. The offensive side? That takes its own time. The company’s Findability.ai
However, you might face significant challenges when planning for a large-scale data warehouse migration. For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprisedata platform. Platform architects define a well-architected platform.
We can kind of do it within one enterprise, agreeing on certain templates, but when we start going cross-enterprise, or when we start integrating legacy data, it will be a lot of work doing that by hand. OntoRefine is a datatransformation tool that lets you unite plenty of data formats and get them into your triplestore.
However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to know which data products they can join to create new insights. This is especially true in a large enterprise with thousands of data products.
In our last blog , we delved into the seven most prevalent data challenges that can be addressed with effective data governance. Today we will share our approach to developing a data governance program to drive datatransformation and fuel a data-driven culture.
Organizations have spent a lot of time and money trying to harmonize data across diverse platforms , including cleansing, uploading metadata, converting code, defining business glossaries, tracking datatransformations and so on. So questions linger about whether transformeddata can be trusted.
With Octopai’s support and analysis of Azure Data Factory, enterprises can now view complete end-to-end data lineage from Azure Data Factory all the way through to reporting for the first time ever.
They also don’t have features for enterprisedata management such as schema language, data validation capabilities, interoperable serialization formats, or a proper modeling language. RDF is used extensively for data publishing and data interchange and is based on W3C and other industry standards.
For HealthCo, this meant they could finally see how data moved from its source through various transformations to its final destination. This visibility was crucial for identifying and rectifying dataquality issues quickly, ensuring consistent and reliable insights.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Just as a navigation app provides a detailed map of roads, guiding you from your starting point to your destination while highlighting every turn and intersection, data flow lineage offers a comprehensive view of data movement and transformations throughout its lifecycle.
As the latest iteration in this pursuit of high-qualitydata sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, dataquality , and ETL/ELT. Simply put, IDF standardizes data engineering processes. DataOps has emerged as an exciting solution. Transparency is key.
But there are only so many data engineers available in the market today; there’s a big skills shortage. So to get away from that lack of data engineers, what data mesh says is, ‘Take those business logic datatransformation capabilities and move that to the domains.’ Let’s take data privacy as an example.
Tricentis is the global leader in continuous testing for DevOps, cloud, and enterprise applications. Finally, data integrity is of paramount importance. Every event in the data source can be relevant, and our customers don’t tolerate data loss, poor dataquality, or discrepancies between the source and Tricentis Analytics.
DataRobot and Snowflake Jointly Unleash Human and Machine Intelligence Across the Industrial Enterprise Landscape. The first step in building a model that can predict machine failure and even recommend the next best course of action is to aggregate, clean, and prepare data to train against. Native Python Support for Snowpark.
To make good on this potential, healthcare organizations need to understand their data and how they can use it. These systems should collectively maintain dataquality, integrity, and security, so the organization can use data effectively and efficiently. Why Is Data Governance in Healthcare Important?
Reading Time: < 1 minute In this post, I’m going to cover logical data management and its impact on data mesh architectures. But there’s a lot of confusion in the marketplace today between different types of architectures, specifically data mesh and data fabric, so I’ll.
We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry. This is where we dispel an old “big data” notion (heard a decade ago) that was expressed like this: “we need our data to run at the speed of business.”
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
In early April 2021, DataKItchen sat down with Jonathan Hodges, VP Data Management & Analytics, at Workiva ; Chuck Smith, VP of R&D Data Strategy at GlaxoSmithKline (GSK) ; and Chris Bergh, CEO and Head Chef at DataKitchen, to find out about their enterprise DataOps transformation journey, including key successes and lessons learned.
In this blog, we’ll delve into the critical role of governance and data modeling tools in supporting a seamless data mesh implementation and explore how erwin tools can be used in that role. erwin also provides data governance, metadata management and data lineage software called erwin Data Intelligence by Quest.
As organizations become more data-driven, different use cases will always require different types of transformations, putting a heavy load on the centralized teams. For large enterprises, data mesh distributes data ownership and reduces dependencies between services.
In fact, as companies undertake digital transformations , usually the datatransformation comes first, and doing so often begins with breaking down data — and political — silos in various corners of the enterprise. Some of this data might previously have been accessible to only a small number of groups or users.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
Extract, Transform and Load (ETL) refers to a process of connecting to data sources, integrating data from various data sources, improving dataquality, aggregating it and then storing it in staging data source or data marts or data warehouses for consumption of various business applications including BI, Analytics and Reporting.
The Right Self-Serve Data Preparation Solution is Sophisticated, Easy-to-Use and Ensures User Adoption! When your enterprise decides to roll out analytics for business users, it is important to implement the right solution.
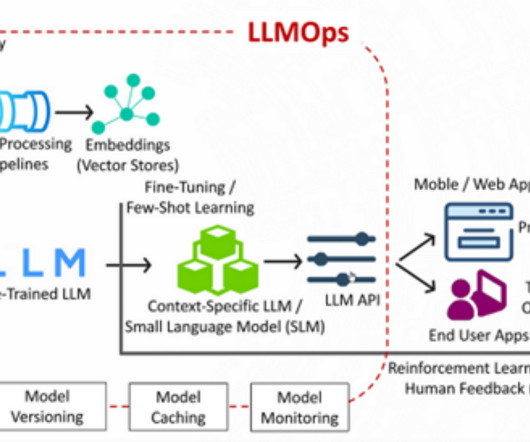
Unleashing GenAIEnsuring DataQuality at Scale (Part2) Transitioning from individual repository source systems to consolidated AI LLM pipelines, the importance of automated checks, end-to-end observability, and compliance with enterprise businessrules. T Introduction There are several opportunities (and needs!)
Give up on using traditional IT for AI The ultimate goal is to have AI-ready data, which means quality and consistent data with the right structures optimized to be effectively used in AI models and to produce the desired outcomes for a given application, says Beatriz Sanz Siz, global AI sector leader at EY.
For data management teams, achieving more with fewer resources has become a familiar challenge. While efficiency is a priority, dataquality and security remain non-negotiable. Developing and maintaining datatransformation pipelines are among the first tasks to be targeted for automation.
Businesses of all sizes are challenged with the complexities and constraints posed by traditional extract, transform and load (ETL) tools. These intricate solutions, while powerful, often come with a significant financial burden, particularly for small and medium enterprise customers.
Data Extraction : The process of gathering data from disparate sources, each of which may have its own schema defining the structure and format of the data and making it available for processing. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization. What is an ETL pipeline?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content