This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
At IKEA, the global home furnishings leader, data is more than an operational necessity—it’s a strategic asset. In a recent presentation at the SAPSA Impuls event in Stockholm , George Sandu, IKEA’s Master Data Leader, shared the company’s datatransformation story, offering valuable lessons for organizations navigating similar challenges.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Alerts and notifications play a crucial role in maintaining dataquality because they facilitate prompt and efficient responses to any dataquality issues that may arise within a dataset. It simplifies your experience of monitoring and evaluating the quality of your data.
The need for streamlined datatransformations As organizations increasingly adopt cloud-based data lakes and warehouses, the demand for efficient datatransformation tools has grown. With dbt, teams can define dataquality checks and access controls as part of their transformation workflow.
This is where we dispel an old “big data” notion (heard a decade ago) that was expressed like this: “we need our data to run at the speed of business.” Instead, what we really need is for our business to run at the speed of data. Datasphere is not just for data managers.
In today’s rapidly evolving financial landscape, data is the bedrock of innovation, enhancing customer and employee experiences and securing a competitive edge. Like many large financial institutions, ANZ Institutional Division operated with siloed data practices and centralized data management teams.
When implementing automated validation, AI-driven regression testing, real-time canary pipelines, synthetic data generation, freshness enforcement, KPI tracking, and CI/CD automation, organizations can shift from reactive data observability to proactive dataquality assurance. Summary: Why thisorder?
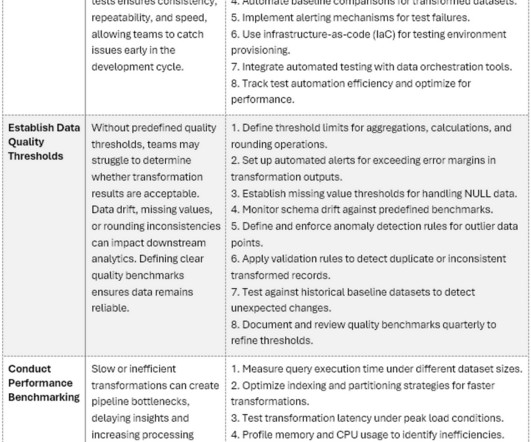
Its EssentialVerifying DataTransformations (Part4) Uncovering the leading problems in datatransformation workflowsand practical ways to detect and preventthem In Parts 13 of this series of blogs, categories of datatransformations were identified as among the top causes of dataquality defects in data pipeline workflows.
Complex Data TransformationsTest Planning Best Practices Ensuring data accuracy with structured testing and best practices Photo by Taylor Vick on Unsplash Introduction Datatransformations and conversions are crucial for data pipelines, enabling organizations to process, integrate, and refine raw data into meaningful insights.
However, Great Expectations (GX ) sets itself apart as a robust, open-source framework that helps data teams maintain consistent and transparent dataquality standards. Dataquality rules are codified into structured Expectation Suites by Great Expectations instead of relying on ad-hoc scripts or manual checks.
Managing tests of complex datatransformations when automated data testing tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
Alation and Bigeye have partnered to bring data observability and dataquality monitoring into the data catalog. Read to learn how our newly combined capabilities put more trustworthy, qualitydata into the hands of those who are best equipped to leverage it. trillion each year due to poor dataquality.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Unregulated ETL/ELT Processes: The absence of stringent dataquality tests in ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes further exacerbates the problem.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
At Workiva, they recognized that they are only as good as their data, so they centered their initial DataOps efforts around lowering errors. At Workiva, they recognized that they are only as good as their data, so they centered their initial DataOps efforts around lowering errors. Others have difficulty collaborating.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-qualitydata as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage.
AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue provides both visual and code-based interfaces to make data integration effortless.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integrate data for analytics , reporting, and operational decision-making.
Data lineage is the journey data takes from its creation through its transformations over time. It describes a certain dataset’s origin, movement, characteristics and quality. Tracing the source of data is an arduous task. What are the transformation rules?
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
Yet as companies fight for skilled analyst roles to utilize data to make better decisions , they often fall short in improving the data supply chain and resulting dataquality. Without a solid data supply-chain management practices in place, dataquality often suffers. First mile/last mile impacts.
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with data engineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. We would like to talk about data visualization and its role in the big data movement.
Unfortunately, the road to data strategy success is fraught with challenges, so CIOs and other technology leaders need to plan and execute carefully. Here are some data strategy mistakes IT leaders would be wise to avoid. Overlooking these data resources is a big mistake. It will not be something they can ignore.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. What is data integrity?
For years, IT and business leaders have been talking about breaking down the data silos that exist within their organizations. Given the importance of sharing information among diverse disciplines in the era of digital transformation, this concept is arguably as important as ever.
Replace manual and recurring tasks for fast, reliable data lineage and overall data governance. It’s paramount that organizations understand the benefits of automating end-to-end data lineage. The importance of end-to-end data lineage is widely understood and ignoring it is risky business. Doing Data Lineage Right.
What is data management? Data management can be defined in many ways. The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). Datatransformation. Data analytics and visualisation. Microsoft Azure.
The company’s orthodontics business, for instance, makes heavy use of image processing to the point that unstructured data is growing at a pace of roughly 20% to 25% per month. For example, imaging data can be used to show patients how an aligner will change their appearance over time. “It The offensive side?
An IDC report estimated the global IT developer shortage will reach four million by 2025, leaving businesses struggling to accelerate digital transformation without the needed workforce. However, this partnership model cannot keep pace with an always-changing technology landscape in which the skill gaps and lack of resources are increasing.
Modern data governance is a strategic, ongoing and collaborative practice that enables organizations to discover and track their data, understand what it means within a business context, and maximize its security, quality and value. The What: Data Governance Defined. Data governance has no standard definition.
They may also learn from evidence, but the data and the modelling fundamentally comes from humans in some way. Data Science – Data science is the field of study that combines domain expertise, programming skills, and knowledge of mathematics and statistics to extract meaningful insights from data. Credit: [link].
The emergence of generative AI prompted several prominent companies to restrict its use because of the mishandling of sensitive internal data. Currently, no standardized process exists for overcoming data ingestion’s challenges, but the model’s accuracy depends on it. Increased variance: Variance measures consistency.
However, you might face significant challenges when planning for a large-scale data warehouse migration. Identify all upstream and downstream applications, as well as business processes that rely on the data warehouse. Datatransformation experts to convert database stored functions in the producer or consumer.
Amazon Redshift enables you to run complex SQL analytics at scale and performance on terabytes to petabytes of structured and unstructured data, and make the insights widely available through popular business intelligence (BI) and analytics tools. It’s common to ingest multiple data sources into Amazon Redshift to perform analytics.
.” The Data Strategy HealthCo, like many forward-thinking organizations, recognized early on that data is not just a valuable asset but a strategic imperative. They put data at the forefront of their business, integrating it into decision-making processes, products, and services. The lack of trust in data created inertia.
The Orca Platform is powered by a state-of-the-art anomaly detection system that uses cutting-edge ML algorithms and big data capabilities to detect potential security threats and alert customers in real time, ensuring maximum security for their cloud environment. Why did Orca choose Apache Iceberg?
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. This will create a session using a configurable subset of the data.
In our last blog , we delved into the seven most prevalent data challenges that can be addressed with effective data governance. Today we will share our approach to developing a data governance program to drive datatransformation and fuel a data-driven culture.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. Cleaning up dirty data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content