This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Once the province of the datawarehouse team, data management has increasingly become a C-suite priority, with dataquality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor dataquality is holding back enterprise AI projects.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
In fact, by putting a single label like AI on all the steps of a data-driven business process, we have effectively not only blurred the process, but we have also blurred the particular characteristics that make each step separately distinct, uniquely critical, and ultimately dependent on specialized, specific technologies at each step.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
Organizations face various challenges with analytics and business intelligence processes, including data curation and modeling across disparate sources and datawarehouses, maintaining dataquality and ensuring security and governance.
Digital transformation started creating a digital presence of everything we do in our lives, and artificial intelligence (AI) and machine learning (ML) advancements in the past decade dramatically altered the data landscape. The choice of vendors should align with the broader cloud or on-premises strategy.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. OwlDQ — Predictive dataquality.
Now, with support for dbt Cloud, you can access a managed, cloud-based environment that automates and enhances your data transformation workflows. This upgrade allows you to build, test, and deploy datamodels in dbt with greater ease and efficiency, using all the features that dbt Cloud provides.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and data lakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and datawarehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. DDD divides a system or model into smaller subsystems called domains.
It’s costly and time-consuming to manage on-premises datawarehouses — and modern cloud data architectures can deliver business agility and innovation. However, CIOs declare that agility, innovation, security, adopting new capabilities, and time to value — never cost — are the top drivers for cloud data warehousing.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
This can include a multitude of processes, like data profiling, dataquality management, or data cleaning, but we will focus on tips and questions to ask when analyzing data to gain the most cost-effective solution for an effective business strategy. 4) How can you ensure dataquality?
Some of these ‘structures’ may include putting all the information; for instance, a structure could be about cars, placing them into tables that consist of makes, models, year of manufacture, and color. With a MySQL dashboard builder , for example, you can connect all the data with a few clicks. Viescas, Douglas J.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Centralized reporting boosts data value For more than a decade, pediatric health system Phoenix Children’s has operated a datawarehouse containing more than 120 separate data systems, providing the ability to connect data from disparate systems. Companies should also incorporate data discovery, Higginson says.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
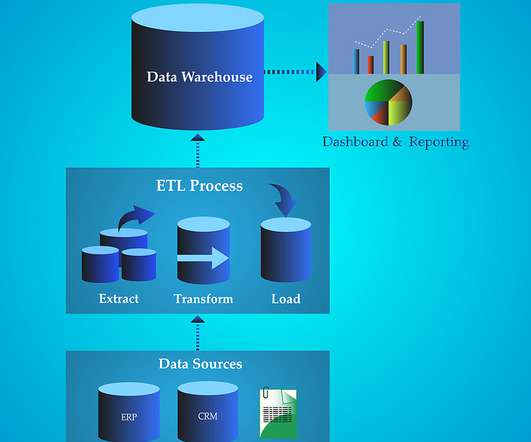
ETL is a three-step process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target database or datawarehouse. Extract The extraction phase involves retrieving data from diverse sources such as databases, spreadsheets, APIs, or other systems.
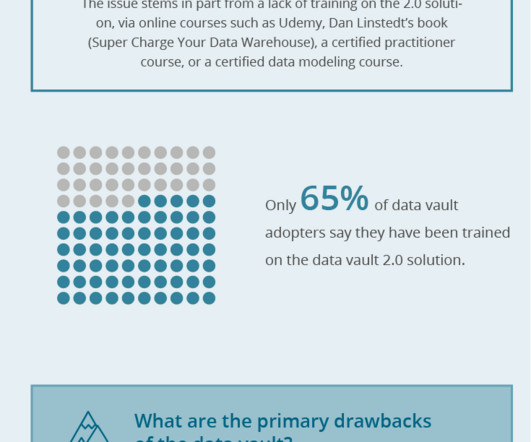
While most continue to struggle with dataquality issues and cumbersome manual processes, best-in-class companies are making improvements with commercial automation tools. The data vault has strong adherents among best-in-class companies, even though its usage lags the alternative approaches of third-normal-form and star schema.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Organizations that can effectively leverage data as a strategic asset will inevitably build a competitive advantage and outperform their peers over the long term. In order to achieve that, though, business managers must bring order to the chaotic landscape of multiple data sources and datamodels.
A strong data management strategy and supporting technology enables the dataquality the business requires, including data cataloging (integration of data sets from various sources), mapping, versioning, business rules and glossaries maintenance and metadata management (associations and lineage). Map data flows.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
It seeks to improve the way data are managed and products are created, and to coordinate these improvements with the goals of the business. According to Gartner, DataOps also aims “to deliver value faster by creating predictable delivery and change management of data, datamodels, and related artifacts.”
The SAP Data Intelligence Cloud solution helps you simplify your landscape with tools for creating data pipelines that integrate data and data streams on the fly for any type of use – from data warehousing to complex data science projects to real-time embedded analytics in business applications.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. With automation, dataquality is systemically assured.
The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high dataquality, all with low total cost of ownership (TCO) and no need for additional tools or licenses. dbt emerged as the perfect choice for this transformation within their existing AWS environment.
The format of the outcome is not a defining characteristic of the data product, which could be a business intelligence (BI) dashboard (and the underlying datawarehouse), a decision intelligence application, an algorithm or artificial intelligence/machine learning (AI/ML) model, or a custom-built operational application.
According to Kari Briski, VP of AI models, software, and services at Nvidia, successfully implementing gen AI hinges on effective data management and evaluating how different models work together to serve a specific use case. But some IT leaders are getting it right because they focus on three key aspects.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, dataquality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. If it’s not done right away, then later.
One option is a data lake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Another option is a datawarehouse, which stores processed and refined data. Ready to evolve your analytics strategy or improve your dataquality?
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
As we have already said, the challenge for companies is to extract value from data, and to do so it is necessary to have the best visualization tools. Over time, it is true that artificial intelligence and deep learning models will be help process these massive amounts of data (in fact, this is already being done in some fields).
Following are two examples that illustrate the data governance stock check, including the Any 2 approach in action, based on real consulting engagements. Therefore, the organization needed to catalog the data it acquires from suppliers, ensure its quality, classify it, and then sell it to customers.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content