This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
One of our key datawarehouse refreshes had failed. No new data. The refresh was long past its deadline, the projects key data engineer was on vacation, and I was playing backup. At the moment, I was flying home from a dataquality conference. The value of dataquality is often invisible.
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. Introducing the next generation of SageMaker The rise of generative AI is changing how data and AI teams work together.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. This is where SAP Datasphere (the next generation of SAP DataWarehouse Cloud) comes in.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Organizations face various challenges with analytics and business intelligence processes, including data curation and modeling across disparate sources and datawarehouses, maintaining dataquality and ensuring security and governance.
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML.
The success of any business into the next year and beyond will depend entirely on the volume, accuracy, and reportability of the data they collect—and how well the business can analyze, extract insight from, and take action on that data. All About That (Data)Base. Enter the Warehouse.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
This can include a multitude of processes, like data profiling, dataquality management, or data cleaning, but we will focus on tips and questions to ask when analyzing data to gain the most cost-effective solution for an effective business strategy. 4) How can you ensure dataquality?
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Easy to report problems and receive updates on fixes.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Bridging the Gap: How ‘Data in Place’ and ‘Data in Use’ Define Complete Data Observability In a world where 97% of data engineers report burnout and crisis mode seems to be the default setting for data teams, a Zen-like calm feels like an unattainable dream. What is Data in Use?
Centralized reporting boosts data value For more than a decade, pediatric health system Phoenix Children’s has operated a datawarehouse containing more than 120 separate data systems, providing the ability to connect data from disparate systems.
A host of notable brands and retailers with colossal inventories and multiple site pages use SQL to enhance their site’s structure functionality and MySQL reporting processes. Whether you need to write database applications, perform administrative tasks or utilize a SQL report builder , this book is amongst the best books to learn SQL.
In addition to increasing the price of deployment, setting up these datawarehouses and processors also impacted expensive IT labor resources. The ROI alone from hours saved and reduced costs of producing current reports will improve your bottom line. 3) Analyzing data from different data sources.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. In the past, one-to-one connections were established between Tableau and respective applications.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure.
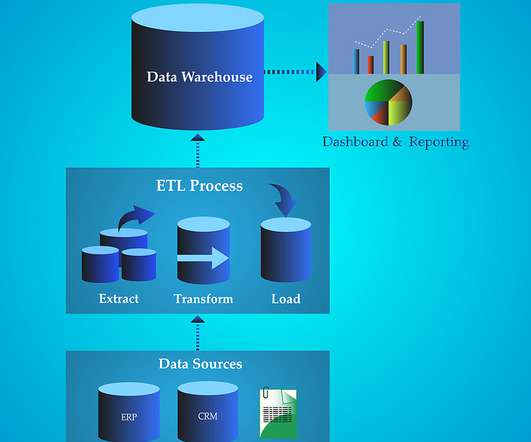
ETL is a three-step process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target database or datawarehouse. Extract The extraction phase involves retrieving data from diverse sources such as databases, spreadsheets, APIs, or other systems.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
The application supports custom workflows to allow demand and supply planning teams to collaborate, plan, source, and fulfill customer orders, then track fulfillment metrics via persona-based operational and management reports and dashboards. The following diagram illustrates the solution architecture.
As the volume of available information continues to grow, data management will become an increasingly important factor in effective business management. Lack of proactive data management, on the other hand, can result in incompatible or inconsistent sources of information, as well as dataquality problems.
The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high dataquality, all with low total cost of ownership (TCO) and no need for additional tools or licenses. Flat files – Other systems supply data in the form of flat files of different formats.
Each data producer within the organization has its own data lake in Apache Hudi format, ensuring data sovereignty and autonomy. These datasets are pivotal for reporting and analytics use cases, powered by services like Amazon Redshift and tools like Power BI.
History management in data systems is fundamental for compliance, business intelligence, dataquality, and time-based analysis. It enables organizations to maintain audit trails, perform trend analysis, identify dataquality issues, and conduct point-in-time reporting.
The 2020 State of Data Governance and Automation (DGA) shows that attitudes about data governance and the drivers behind it are changing – arguably for the better. Regulatory compliance was the biggest driver for data governance implementation, according to the 2018 report. Metadata Management Takes Time.
From operational systems to support “smart processes”, to the datawarehouse for enterprise management, to exploring new use cases through advanced analytics : all of these environments incorporate disparate systems, each containing data fragments optimized for their own specific task. .
A strong data management strategy and supporting technology enables the dataquality the business requires, including data cataloging (integration of data sets from various sources), mapping, versioning, business rules and glossaries maintenance and metadata management (associations and lineage).
Find out what is working, as you don’t want to totally scrap an already essential report or process. What data analysis questions are you unable to currently answer? This should also include creating a plan for data storage services. Are the data sources going to remain disparate? Clean data in, clean analytics out.
Data lakes are more focused around storing and maintaining all the data in an organization in one place. And unlike datawarehouses, which are primarily analytical stores, a data hub is a combination of all types of repositories—analytical, transactional, operational, reference, and data I/O services, along with governance processes.
Without C360, businesses face missed opportunities, inaccurate reports, and disjointed customer experiences, leading to customer churn. AWS provides different services for building data ingestion pipelines: AWS Glue is a serverless data integration service that ingests data in batches from on-premises databases and data stores in the cloud.
External data sharing gets strategic Data sharing between business partners is becoming far easier and much more cooperative, observes Mike Bechtel, chief futurist at business advisory firm Deloitte Consulting. CIOs should first understand the different approaches to observing data and how it differs from quality management,” he notes.
Consolidation creates a single source of truth on which to base decisions, actions, and reports. Which type(s) of storage consolidation you use depends on the data you generate and collect. . Another option is a datawarehouse, which stores processed and refined data. Just starting out with analytics?
Data engineers are often responsible for building algorithms for accessing raw data, but to do this, they need to understand a company’s or client’s objectives, as aligning data strategies with business goals is important, especially when large and complex datasets and databases are involved. Data engineer job description.
Data virtualization is ideal in any situation where the is necessary: Information coming from diverse data sources. Multi-channel publishing of data services. How does Data Virtualization manage dataquality requirements? How does Data Virtualization complement Data Warehousing and SOA Architectures?
BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions. Determining which BI delivery method fits best There are many traditional IT-managed ways to deliver reports and insights from data.
Here are some benefits of metadata management for data governance use cases: Better DataQuality: Data issues and inconsistencies within integrated data sources or targets are identified in real time to improve overall dataquality by increasing time to insights and/or repair. by up to 70 percent.
It’s About the Data For companies that have succeeded in an AI and analytics deployment, data availability is a key performance indicator, according to a Harvard Business Review report. [3] It provides rapid, direct access to trusted data for data scientists, business analysts, and others who need data to drive business value.
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders. Athena exposes the content of the reporting zone for consumption.
It’s hard to answer that question because, truth be told, you don’t know you’re using bad data until it’s too late. . states that about 40 percent of enterprise data is either inaccurate, incomplete, or unavailable. Because bad data is the reason behind poor analytics. . Top 5 Warning Signs of Bad Data. Ted Friedman.
Griffin is an open source dataquality solution for big data, which supports both batch and streaming mode. In today’s data-driven landscape, where organizations deal with petabytes of data, the need for automated data validation frameworks has become increasingly critical.
At the same time, it reduces risk by ensuring that all data is under control, avoiding inconsistencies, and adhering to a single source of truth. In a recent IDC Infobrief , more than half of respondents report that regulatory compliance is a primary factor in deciding how and where they store enterprise data.
DataKitchen acts as a process hub that unifies tools and pipelines across teams, tools and data centers. DataKitchen could, for example, provide the scaffolding upon which a Snowflake cloud data platform or datawarehouse could be integrated into a heterogeneous data mesh domain.
After all, how do you adjust this month’s operations based on last month’s data if it takes two weeks to finally receive the information you need? This is exactly how Octopai customer, Farm Credit Services of America (FCSA) , felt when their BI team needed to modernize their datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content