This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Talend is a data integration and management software company that offers applications for cloud computing, big data integration, application integration, dataquality and master data management. Its code generation architecture uses a visual interface to create Java or SQL code.
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. This is where SAP Datasphere (the next generation of SAP DataWarehouse Cloud) comes in.
Dataquality is crucial in data pipelines because it directly impacts the validity of the business insights derived from the data. Today, many organizations use AWS Glue DataQuality to define and enforce dataquality rules on their data at rest and in transit.
There are countless examples of big data transforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about datavisualization and its role in the big data movement.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key. The tools to transform your business are here.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and datawarehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and data lakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. OwlDQ — Predictive dataquality.
This can include a multitude of processes, like data profiling, dataquality management, or data cleaning, but we will focus on tips and questions to ask when analyzing data to gain the most cost-effective solution for an effective business strategy. 4) How can you ensure dataquality?
They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML. Based on business needs and the nature of the data, raw vs structured, organizations should determine whether to set up a datawarehouse, a Lakehouse or consider a data fabric technology.
Business leaders, developers, data heads, and tech enthusiasts – it’s time to make some room on your business intelligence bookshelf because once again, datapine has new books for you to add. We have already given you our top datavisualization books , top business intelligence books , and best data analytics books.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. The data science and AI teams are able to explore and use new data sources as they become available through Amazon DataZone.
Data consumers lose trust in data if it isn’t accurate and recent, making dataquality essential for undertaking optimal and correct decisions. Evaluation of the accuracy and freshness of data is a common task for engineers. Currently, various tools are available to evaluate dataquality.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
In addition to increasing the price of deployment, setting up these datawarehouses and processors also impacted expensive IT labor resources. These tools allow for a wide range of users to easily connect to, interact with, visualize and communicate their data. 7) Dealing with the impact of poor dataquality.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
As the volume of available information continues to grow, data management will become an increasingly important factor in effective business management. Lack of proactive data management, on the other hand, can result in incompatible or inconsistent sources of information, as well as dataquality problems.
This should also include creating a plan for data storage services. Are the data sources going to remain disparate? Or does building a datawarehouse make sense for your organization? Clean data in, clean analytics out. Cleaning your data may not be quite as simple, but it will ensure the success of your BI.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. If it’s not done right away, then later.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
From operational systems to support “smart processes”, to the datawarehouse for enterprise management, to exploring new use cases through advanced analytics : all of these environments incorporate disparate systems, each containing data fragments optimized for their own specific task. .
BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions. To gain employee buy-in, Stout’s team builds BI dashboards to show them how they can easily connect to and interact with their data, as well as visualize it in a meaningful way.
However, enterprise data generated from siloed sources combined with the lack of a data integration strategy creates challenges for provisioning the data for generative AI applications. Implement data privacy policies. Implement dataquality by data type and source.
The focus here should be on considering all ways your customers currently consume data as well as new ways they might want to achieve better results. Of course, no set of imperatives for a data strategy would be complete without the need to consider people, process, and technology.
External data sharing gets strategic Data sharing between business partners is becoming far easier and much more cooperative, observes Mike Bechtel, chief futurist at business advisory firm Deloitte Consulting. CIOs should first understand the different approaches to observing data and how it differs from quality management,” he notes.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, dataquality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
Candidates are required to complete a minimum of 12 credits, including four required courses: Algorithms for Data Science, Probability and Statistics for Data Science, Machine Learning for Data Science, and Exploratory Data Analysis and Visualization. Candidates have 90 minutes to complete the exam.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make data integration effortless. Choose Create job and Visual ETL. Choose Create connection.
Data engineers are often responsible for building algorithms for accessing raw data, but to do this, they need to understand a company’s or client’s objectives, as aligning data strategies with business goals is important, especially when large and complex datasets and databases are involved. Data engineer job description.
Gluent’s Smart Connector is capable of pushing processing to Cloudera, thereby reducing the storage and compute footprint on traditional datawarehouses like Oracle. This allows our customers to reduce spend on highly specialized hardware and leverage the tools of a modern datawarehouse. . Certified DataQuality Partner.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
Data and its various uses is increasingly evident in companies, and each professional has their preferences about which technologies to use to visualizedata, which isn’t necessarily in line with the technological needs and infrastructure of a company. In this post, we discuss why we chose QuickSight and how we implemented it.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Data lakes are more focused around storing and maintaining all the data in an organization in one place. And unlike datawarehouses, which are primarily analytical stores, a data hub is a combination of all types of repositories—analytical, transactional, operational, reference, and data I/O services, along with governance processes.
Since its uniquely metadata-driven, the abstraction layer of a data fabric makes it easier to model, integrate and query any data sources, build data pipelines, and integrate data in real-time. This improves data engineering productivity and time-to-value for data consumers. What’s a data mesh?
In 2016, people will realize the importance of scaling the generation of insights in parallel with the data – and finally have the ability to manage sprawl and realize new levels of insights from the data. 2016 will be the year of the “logical datawarehouse.”
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Amazon Redshift enables you to run complex SQL analytics at scale and performance on terabytes to petabytes of structured and unstructured data, and make the insights widely available through popular business intelligence (BI) and analytics tools.
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for VisualizationData pipelines can facilitate easier datavisualization by gathering and transforming the necessary data into a usable state.
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. Communicate and visualize the results. A data catalog can assist directly with every step, but model development.
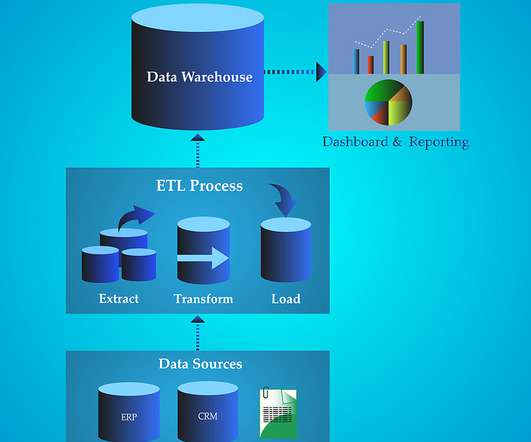
Other challenges to data analytics include data storage, dataquality, and a lack of knowledge and tools necessary to make sense of the data and generate those critical insights. Limited real-time analytics and visuals. Typically, we take our multiple data sources and perform some level of ETL on the data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content