This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., Split each document into chunks.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with dataquality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor dataquality is holding back enterprise AI projects.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Data debt that undermines decision-making In Digital Trailblazer , I share a story of a private company that reported a profitable year to the board, only to return after the holiday to find that dataquality issues and calculation mistakes turned it into an unprofitable one.
In recent posts, we described requisite foundational technologies needed to sustain machine learning practices within organizations, and specialized tools for model development, model governance, and model operations/testing/monitoring. Sources of model risk. Model risk management. Image by Ben Lorica.
There has been a significant increase in our ability to build complex AI models for predictions, classifications, and various analytics tasks, and there’s an abundance of (fairly easy-to-use) tools that allow data scientists and analysts to provision complex models within days. Data integration and cleaning.
Companies are no longer wondering if data visualizations improve analyses but what is the best way to tell each data-story. 2020 will be the year of dataquality management and data discovery: clean and secure data combined with a simple and powerful presentation. 1) DataQuality Management (DQM).
In a world focused on buzzword-driven models and algorithms, you’d be forgiven for forgetting about the unreasonable importance of data preparation and quality: your models are only as good as the data you feed them. The model and the data specification become more important than the code.
We actually started our AI journey using agents almost right out of the gate, says Gary Kotovets, chief data and analytics officer at Dun & Bradstreet. The knowledge management systems are up to date and support API calls, but gen AI models communicate in plain English. Thats what Cisco is doing.
Now, with support for dbt Cloud, you can access a managed, cloud-based environment that automates and enhances your data transformation workflows. This upgrade allows you to build, test, and deploy datamodels in dbt with greater ease and efficiency, using all the features that dbt Cloud provides.
And everyone has opinions about how these language models and art generation programs are going to change the nature of work, usher in the singularity, or perhaps even doom the human race. 16% of respondents working with AI are using open source models. A few have even tried out Bard or Claude, or run LLaMA 1 on their laptop.
The hype around large language models (LLMs) is undeniable. They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. In life sciences, simple statistical software can analyze patient data.
Working software over comprehensive documentation. Business intelligence is moving away from the traditional engineering model: analysis, design, construction, testing, and implementation. In the traditional model communication between developers and business users is not a priority. Finalize documentation, where necessary.
DataKitchen Training And Certification Offerings For Individual contributors with a background in Data Analytics/Science/Engineering Overall Ideas and Principles of DataOps DataOps Cookbook (200 page book over 30,000 readers, free): DataOps Certificatio n (3 hours, online, free, signup online): DataOps Manifesto (over 30,000 signatures) One (..)
Digital transformation started creating a digital presence of everything we do in our lives, and artificial intelligence (AI) and machine learning (ML) advancements in the past decade dramatically altered the data landscape. Implementing ML capabilities can help find the right thresholds.
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities. So, if you have 1 trillion data points (g.,
Similarly, in “ Building Machine Learning Powered Applications: Going from Idea to Product ,” Emmanuel Ameisen states: “Indeed, exposing a model to users in production comes with a set of challenges that mirrors the ones that come with debugging a model.”.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure.
We will explore Icebergs concurrency model, examine common conflict scenarios, and provide practical implementation patterns of both automatic retry mechanisms and situations requiring custom conflict resolution logic for building resilient data pipelines. This scenario applies to any type of updates on an Iceberg table.
While there is a lot of effort and content that is now available, it tends to be at a higher level which will require work to be done to create a governance model specifically for your organization. Governance is action and there are many actions an organization can take to create and implement an effective AI governance model.
Datamodeling supports collaboration among business stakeholders – with different job roles and skills – to coordinate with business objectives. Data resides everywhere in a business , on-premise and in private or public clouds. A single source of data truth helps companies begin to leverage data as a strategic asset.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. The insights are used to produce informative content for stakeholders (decision-makers, business users, and clients).
In natural language processing (NLP) and computational linguistics the Gold Standard typically represents a corpus of text or a set of documents, annotated or tagged with the desired results for the analysis – be it designation of the corresponding part of speech, syntactic parsing, concept or relationship.
The main reason is that it is difficult and time-consuming to consolidate, process, label, clean, and protect the information at scale to train AI models. An aircraft engine provider uses AI to manage thousands of technical documents required for engine certification, reducing administration time from 3-6 months to a few weeks.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States.
Crucial data resides in hundreds of emails sent and received every day, on spreadsheets, in PowerPoint presentations, on videos, in pictures, in reports with graphs, in text documents, on web pages, in purchase orders, in utility bills, and on PDFs. That data is free flowing and does not reside in one place.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
To help alleviate the complexity and extract insights, the foundation, using different AI models, is building an analytics layer on top of this database, having partnered with DataBricks and DataRobot. Some of the models are traditional machine learning (ML), and some, LaRovere says, are gen AI, including the new multi-modal advances.
With business process modeling (BPM) being a key component of data governance , choosing a BPM tool is part of a dilemma many businesses either have or will soon face. Historically, BPM didn’t necessarily have to be tied to an organization’s data governance initiative. Choosing a BPM Tool: An Overview. Silo Buster.
Data visualization enables you to: Make sense of the distributional characteristics of variables Easily identify data entry issues Choose suitable variables for data analysis Assess the outcome of predictive models Communicate the results to those interested. The central concept is the idea of a document.
While these will remain big data governance trends for 2020, we anticipate organizations will finally begin tapping into the true value of data as the foundation of the digital business model. DataModeling: Drive Business Value and Underpin Governance with an Enterprise DataModel.
It encompasses the people, processes, and technologies required to manage and protect data assets. The Data Management Association (DAMA) International defines it as the “planning, oversight, and control over management of data and the use of data and data-related sources.”
This AI-augmented approach ensures that no critical feature falls through the cracks and that accurate requirements documents reduce the likelihood of defects. Invest in dataquality: GenAI models are only as good as the data they’re trained on -with GenAI, mistakes can be amplified at speed.
Worse is when prioritized initiatives don’t have a documented shared vision, including a definition of the customer, targeted value propositions, and achievable success criteria. One recent study shows that only 50% follow a product-centric operating model focusing on customer centricity and delivering delightful customer experiences.
It will do this, it said, with bidirectional integration between its platform and Salesforce’s to seamlessly delivers data governance and end-to-end lineage within Salesforce Data Cloud. We look at the entire landscape of information that an enterprise has,” Sangani said. “As
This can include a multitude of processes, like data profiling, dataquality management, or data cleaning, but we will focus on tips and questions to ask when analyzing data to gain the most cost-effective solution for an effective business strategy. 4) How can you ensure dataquality?
A strong data management strategy and supporting technology enables the dataquality the business requires, including data cataloging (integration of data sets from various sources), mapping, versioning, business rules and glossaries maintenance and metadata management (associations and lineage). Map data flows.
It’s embedded in the applications we use every day and the security model overall is pretty airtight. Microsoft has also made investments beyond OpenAI, for example in Mistral and Meta’s LLAMA models, in its own small language models like Phi, and by partnering with providers like Cohere, Hugging Face, and Nvidia. That’s risky.”
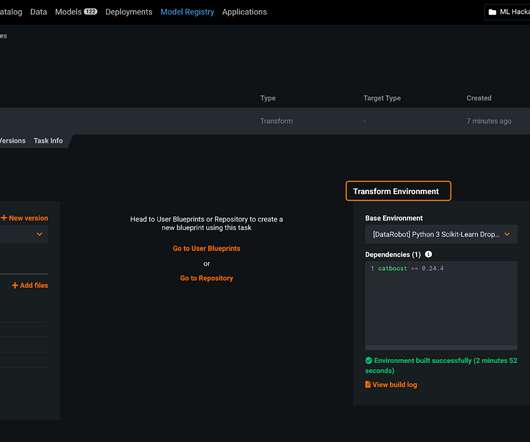
Working from datasets you already have, a Time Series Forecasting model can help you better understand seasonality and cyclical behavior and make future-facing decisions, such as reducing inventory or staff planning. Prepare your data for Time Series Forecasting. Configuring an ML project. Settings for Time Series projects.
With seven operating centers, nine research facilities, and more than 18,000 staff, the agency continually generates an overwhelming amount of data, which it stores in more than 30 science data repositories across five topical areas — astrophysics, heliophysics, biological science, physical science, earth science, and planetary science.
The results of our new research show that organizations are still trying to master data governance, including adjusting their strategies to address changing priorities and overcoming challenges related to data discovery, preparation, quality and traceability. Organizations still depend too much on manual data management.
Modern, strategic data governance , which involves both IT and the business, enables organizations to plan and document how they will discover and understand their data within context, track its physical existence and lineage, and maximize its security, quality and value. How erwin Can Help.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content