This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Concurrent UPDATE/DELETE on overlapping partitions When multiple processes attempt to modify the same partition simultaneously, data conflicts can arise. For example, imagine a dataquality process updating customer records with corrected addresses while another process is deleting outdated customer records.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
It addresses many of the shortcomings of traditional data lakes by providing features such as ACID transactions, schema evolution, row-level updates and deletes, and time travel. In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient.
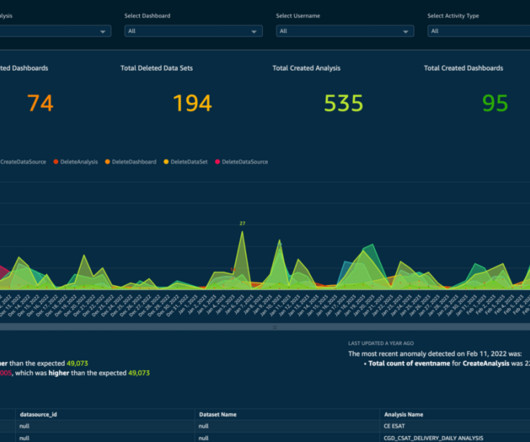
Today, we are pleased to announce that Amazon DataZone is now able to present dataquality information for data assets. Other organizations monitor the quality of their data through third-party solutions. Additionally, Amazon DataZone now offers APIs for importing dataquality scores from external systems.
First, what active metadata management isn’t : “Okay, you metadata! Now, what active metadata management is (well, kind of): “Okay, you metadata! Data assets are tools. Metadata are the details on those tools: what they are, what to use them for, what to use them with. . Quit lounging around!
Fortunately, this is far simpler to do for a data asset than for a can of meat. Data lineage tools give you exactly that kind of transparent, x-ray vision into your dataquality. Data Supervision. Having the right data intelligence tools can be a make-or-break for data responsibility success.
Discoverable – users have access to a catalog or metadata management tool which renders the domain discoverable and accessible. Secure and permissioned – data is protected from unauthorized users. Governed – designed with dataquality and management workflows that empower data usage.
These layers help teams delineate different stages of data processing, storage, and access, offering a structured approach to data management. In the context of Data in Place, validating dataquality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets.
Unstructured data is typically stored across siloed systems in varying formats, and generally not managed or governed with the same level of rigor as structured data. Implement data privacy policies. Implement dataquality by data type and source. Link structured and unstructured datasets.
Data readiness is everything. Whether driving digital experiences, mapping customer journeys, enhancing digital operations, developing digital innovations, finding new ways to interact with customers, or building digital ecosystems or marketplaces – all of this digital transformation is powered by data.
Instead, we got data. Lots and lots of data. Well, we got jetpacks, too, but we rarely interact with them during the workday. It does feel, however, as if we need jet-like speed to analyze and understand our data, who is using it, how it is used, and if it is being used to drive value. This data about data is valuable.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, dataquality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
Keep in mind how named graphs interact with your validation: The SHACL shapes graph will validate the union of all graphs. While these provide no instructions to a SHACL engine, the use of non-validating characteristics such as sh:name and sh:description can add metadata to your shapes that make them easier to maintain as they scale up.
Data governance also relies on business process modeling and analysis to drive improvement , including identifying business practices susceptible to security, compliance or other risks and adding controls to mitigate exposures. The lack of a central metadata repository is a far too common thorn in an organization’s side.
In today’s world, we increasingly interact with the environment around us through data. For all these data operations to flow smoothly, data needs to be interoperable, of good quality and easy to integrate. The catalog stores the asset’s metadata in RDF. Researchers used GraphDB to store semantic metadata.
As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. DataBrew is an excellent tool for dataquality and preprocessing. Choose Create project.
Invest in maturing and improving your enterprise business metrics and metadata repositories, a multitiered data architecture, continuously improving dataquality, and managing data acquisitions. enhanced customer experiences by accelerating the use of data across the organization.
“The number-one issue for our BI team is convincing people that business intelligence will help to make true data-driven decisions,” says Diana Stout, senior business analyst at Schellman, a global cybersecurity assessor based in Tampa, Fl. It’s about being able to find relevant data and connect it through a knowledge graph.
Sources Data can be loaded from multiple sources, such as systems of record, data generated from applications, operational data stores, enterprise-wide reference data and metadata, data from vendors and partners, machine-generated data, social sources, and web sources.
Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. Then, you transform this data into a concise format.
As Dan Jeavons Data Science Manager at Shell stated: “what we try to do is to think about minimal viable products that are going to have a significant business impact immediately and use that to inform the KPIs that really matter to the business”. The goals were multiple: revenue growth, customer satisfaction, and speed of service.
Limiting growth by (data integration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. In both cases, semantic metadata is the glue that turns knowledge graphs into hubs of data, metadata, and content.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies.
An enormous amount of time was being wasted performing manual searches, as the BI team needed to frequently comb through the enterprise data warehouse’s fields to determine how each was calculated or to find their sources. Automated Data Lineage & Discovery Provides Enterprise-Wide Benefits.
The reversal from information scarcity to information abundance and the shift from the primacy of entities to the primacy of interactions has resulted in an increased burden for the data involved in those interactions to be trustworthy.
According to the Forrester Wave: Machine Learning Data Catalogs, Q4 2020 , “Alation exploits machine learning at every opportunity to improve data management, governance, and consumption by analytic citizens. MLDCs improve upon traditional metadata management systems by injecting intelligence. Tracking and Scaling Data Lineage.
Some data teams working remotely are making the most of the situation with advanced metadata management tools that help them deliver faster and more accurately, ensuring business as usual, even during coronavirus. BI reporting systems analyze data and reveal missing or damaged information before it affects dataquality.
What Is Data Intelligence? Data intelligence is a system to deliver trustworthy, reliable data. It includes intelligence about data, or metadata. IDC coined the term, stating, “data intelligence helps organizations answer six fundamental questions about data.” Yet finding data is just the beginning.
This dashboard helps our operations team and end customers improve the dataquality of key attribution and reduce manual intervention. This framework can be described as follows: Findable – Metadata and data should be easy to find for both humans and computers.
In a centralized architecture, data is copied from source systems into a data lake or data warehouse to create a single source of truth serving analytics use cases. This quickly becomes difficult to scale with data discovery and data version issues, schema evolution, tight coupling, and a lack of semantic metadata.
This allows researchers to connect genetic information from NCBI Gene with protein data from UniProt, facilitating a more holistic understanding of gene-protein interactions. Metadata is crucial for data discovery, understanding, and management. Updating a dataset when a new version becomes available is also very easy.
This allows researchers to connect genetic information from NCBI Gene with protein data from UniProt, facilitating a more holistic understanding of gene-protein interactions. Metadata is crucial for data discovery, understanding, and management. Updating a dataset when a new version becomes available is also very easy.
Just as a navigation app provides a detailed map of roads, guiding you from your starting point to your destination while highlighting every turn and intersection, data flow lineage offers a comprehensive view of data movement and transformations throughout its lifecycle. Open Source Data Lineage Tools 1.
Data mesh solves this by promoting data autonomy, allowing users to make decisions about domains without a centralized gatekeeper. It also improves development velocity with better data governance and access with improved dataquality aligned with business needs.
It also adds flexibility in accommodating new kinds of data, including metadata about existing data points that lets users infer new relationships and other facts about the data in the graph. Schemas are an example of how the right metadata can add value to the data it describes.
It delivers the ability to capture and unify the business and technical perspectives of data assets, enables effective collaboration between a variety of stakeholders, and delivers metadata-driven automation to accelerate the creation and maintenance of data sources on virtually any data management platform.
The product collected an impressive amount of metadata, from the user interface to the database structure. It then translated all that metadata into an image resembling a spider’s web. That was my earliest taste of data lineage. I now realize that it was integration with a data catalog like Alation. Or so I thought.
We also used AWS Lambda for data processing. To further optimize and improve the developer velocity for our data consumers, we added Amazon DynamoDB as a metadata store for different data sources landing in the data lake. Clients access this data store with an API’s.
While the essence of success in data governance is people and not technology, having the right tools at your fingertips is crucial. Technology is an enabler, and for data governance this is essentially having an excellent metadata management tool. Next to data governance, data architecture is really embedded in our DNA.
Data privacy laws such as the GDPR in the EU, CCPA in California and PIPEDA in Canada have been enacted at the same time businesses are revitalizing efforts to establish dataquality, not just data volume. Poor dataquality costs organizations an average of $12.9 million each year [1] and $1.2 28, 2021. [2].
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
Moreover, dbt Core enables users to implement business logic directly within transformations, thereby ensuring contract validation for regulatory compliance or dataquality governancesuch as confirming that all high-value transactions include approval codes or that sensitive personal data remains obscured.
For example, Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed—and do all types of processing and analytics across platforms and languages.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content