This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
We will explore Icebergs concurrency model, examine common conflict scenarios, and provide practical implementation patterns of both automatic retry mechanisms and situations requiring custom conflict resolution logic for building resilient data pipelines. The Data Catalog provides the functionality as the Iceberg catalog.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
First, what active metadata management isn’t : “Okay, you metadata! Now, what active metadata management is (well, kind of): “Okay, you metadata! I will, of course, end up with a very amateurish finished product, because I used sub-optimal tools to do the job. Data assets are tools. Quit lounging around!
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes. What is Data in Use?
Well, we got jetpacks, too, but we rarely interact with them during the workday. It does feel, however, as if we need jet-like speed to analyze and understand our data, who is using it, how it is used, and if it is being used to drive value. Analysis, however, requires enterprises to find and collect metadata.
As Dan Jeavons Data Science Manager at Shell stated: “what we try to do is to think about minimal viable products that are going to have a significant business impact immediately and use that to inform the KPIs that really matter to the business”. Business intelligence and analytics allow users to know their businesses on a deeper level.
As part of a data governance strategy, a BPM tool aids organizations in visualizing their business processes, system interactions and organizational hierarchies to ensure elements are aligned and core operations are optimized. The lack of a central metadata repository is a far too common thorn in an organization’s side.
Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. Then, you transform this data into a concise format.
As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. DataBrew is an excellent tool for dataquality and preprocessing. Choose Create project.
This introduces the need for both polling and pushing the data to access and analyze in near-real time. From an operational standpoint, we designed a new shared responsibility model for data ingestion using AWS Glue instead of internal services (REST APIs) designed on Amazon EC2 to extract the data.
Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. They should also provide optimal performance with low or no tuning. The source data is usually in either structured or semi-structured formats, which are highly and loosely formatted, respectively.
So relying upon the past for future insights with data that is outdated due to changing customer preferences, the hyper-competitive world and emphasis on environment, society and governance produces non-relevant insights and sub-optimized returns. Qualitydata needs to be the normalizing factor.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies.
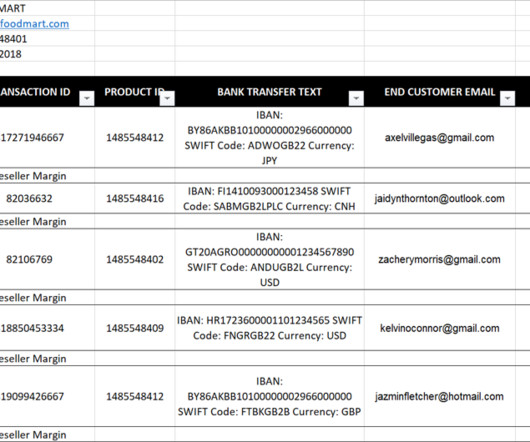
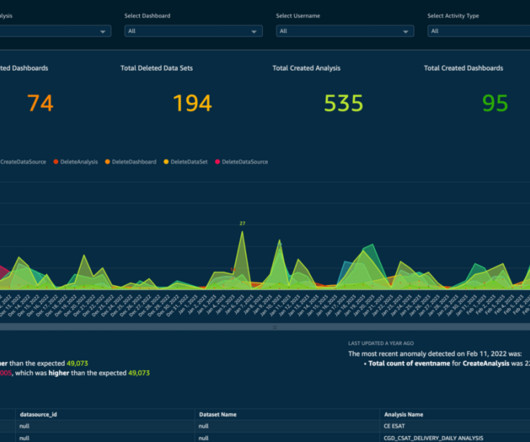
This dashboard helps our operations team and end customers improve the dataquality of key attribution and reduce manual intervention. This framework can be described as follows: Findable – Metadata and data should be easy to find for both humans and computers.
It delivers the ability to capture and unify the business and technical perspectives of data assets, enables effective collaboration between a variety of stakeholders, and delivers metadata-driven automation to accelerate the creation and maintenance of data sources on virtually any data management platform.
According to the Forrester Wave: Machine Learning Data Catalogs, Q4 2020 , “Alation exploits machine learning at every opportunity to improve data management, governance, and consumption by analytic citizens. MLDCs improve upon traditional metadata management systems by injecting intelligence. Tracking and Scaling Data Lineage.
Performance It is not uncommon for sub-second SLAs to be associated with data vault queries, particularly when interacting with the business vault and the data marts sitting atop the business vault. String-optimized compression The Data Vault 2.0 Support of transactional data lake frameworks Data Vault 2.0
What Is Data Intelligence? Data intelligence is a system to deliver trustworthy, reliable data. It includes intelligence about data, or metadata. IDC coined the term, stating, “data intelligence helps organizations answer six fundamental questions about data.” Yet finding data is just the beginning.
For example, Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed—and do all types of processing and analytics across platforms and languages. Future-Proofing your Data.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
Just as a navigation app provides a detailed map of roads, guiding you from your starting point to your destination while highlighting every turn and intersection, data flow lineage offers a comprehensive view of data movement and transformations throughout its lifecycle. Open Source Data Lineage Tools 1.
Earlier in their lifecycle, data products may be measured by alternative metrics, including adoption (number of consumers) and level of activity (releases, interaction with consumers, and so on). Legal & Compliance C Legal & Compliance Officer Consults on permissibility of data products with reference to local regulation.
In this way, data lineage is a powerful tool for understanding. Knowing the data lineage helps you find the source of errors, determine the data’s suitability for usage, understand how processes can be optimized or improved, speed the time to insights, and much more. Why is Data Lineage Important? Was it updated?
To assess the nodes and find an optimal RA3 cluster configuration, we collaborated with AllCloud , the AWS premier consulting partner. A set of queries from the production cluster – This set can be reconstructed from the Amazon Redshift logs ( STL_QUERYTEXT ) and enriched by metadata ( STL_QUERY ).
Therefore, it’s crucial to keep the schema definition in the Schema Registry and the Data Catalog table in sync. To avoid this, it’s recommended to use a dataquality check mechanism to identify such anomalies and take appropriate action in case of unexpected behavior. The following diagram illustrates our solution architecture.
Architecture for data democratization Data democratization requires a move away from traditional “data at rest” architecture, which is meant for storing static data. Traditionally, data was seen as information to be put on reserve, only called upon during customer interactions or executing a program.
This shift of both a technical and an outcome mindset allows them to establish a centralized metadata hub for their data assets and effortlessly access information from diverse systems that previously had limited interaction. There are four groups of data that are naturally siloed: Structured data (e.g.,
Here, I will draw upon our own experience from client projects and lessons learned to provide a selection of optimal use cases for knowledge graphs and semantic solutions along with real world examples of their applications. For many organizations, however, the question remains, “Is it the right solution for us?” million users.
For a time, I believed simulation was more useful a capability than optimization, at the time that larger firms were seeking optimization solutions. where performance and dataquality is imperative? We cannot of course forget metadata management tools, of which there are many different. Do you play SimCity?
If this sounds fanciful, it’s not hard to find AI systems that took inappropriate actions because they optimized a poorly thought-out metric. CTRs are easy to measure, but if you build a system designed to optimize these kinds of metrics, you might find that the system sacrifices actual usefulness and user satisfaction.
By virtue of that, if you take those log files of customers interactions, you aggregate them, then you take that aggregated data, run machine learning models on them, you can produce data products that you feed back into your web apps, and then you get this kind of effect in business. You know what?
The quick and dirty definition of data mapping is the process of connecting different types of data from various data sources. Data mapping is a crucial step in data modeling and can help organizations achieve their business goals by enabling data integration, migration, transformation, and quality.
Business software providers are already incorporating data stores on applications and platforms optimized for specific users and use cases. We refer to this somewhat tongue-in-cheek as a data pantry. By automating the collection of data, reports and dashboards can be timelier.
The collision of traditional EA with cognitive-driven data architectures Enterprise architecture has a storied history of providing organizations with a structured methodology for aligning IT systems with business goals, focusing on standardized business processes, data governance and technology stacks. On-demand data access.
As data lakes increasingly handle sensitive business data and transactional workloads, maintaining strong dataquality, governance, and compliance becomes vital to maintaining trust and regulatory alignment. With this new feature, as you enable the Data Catalog optimizer.
However, a closer look reveals that these systems are far more than simple repositories: Data catalogs are at the forefront of bringing AI into your business for at least two reasons. However, lineage information and comprehensive metadata are also crucial to document and assess AI models holistically in the domain of AI governance.
At the BMW Group, our Cloud Efficiency Analytics (CLEA) team has developed a FinOps solution to optimize costs across over 10,000 cloud accounts. While enabling organization-wide efficiency, the team also applied these principles to the data architecture, making sure that CLEA itself operates frugally.
Modernizing and optimizing enterprise reporting – or classical BI – has not been such a priority for many of today’s organizations, even though it constitutes the backbone of information supply for decision support. Data management has always been a challenge for companies. Modernize data management to guarantee high dataquality.
This is where we blend optimization engines, business rules, AI and contextual data to recommend or automate the best possible action. Think of the next-best-offer algorithms in e-commerce, dynamic hospitality pricing or logistics route optimization. What do dataquality issues look like in the real world?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content