This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
He outlined the challenges of working effectively with AI and machinelearning, where knowledge graphs are a differentiator. In an engaging narrative built on the premise that most organizations are not ready for a knowledge graph, Lance talked about the usual pitfalls when building such a solution.
Several factors are driving the adoption of knowledge graphs. Specifically, the increasing amount of data being generated and collected, and the need to make sense of it, and its use in artificial intelligence and machinelearning, which can benefit from the structured data and context provided by knowledge graphs.
Have you ever been in a conversation where someone mentioned a “knowledge graph,” only to realize that their description was completely different from what you had in mind? Imagine that you want to optimize your supply chain using machinelearning. Unlock the full potential of your data!
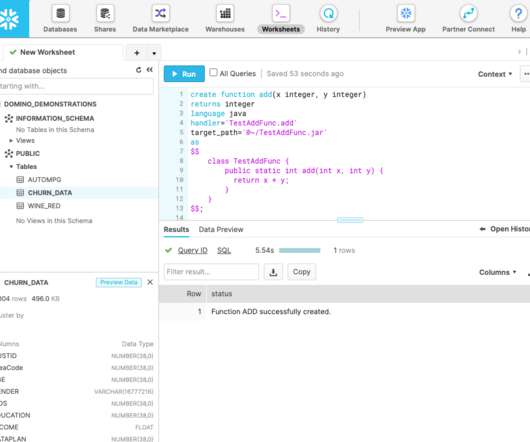
Advanced data wrangling and preprocessing pipelines A Java UDF can use a wider range of techniques for data cleansing, feature engineering, and mode advanced preprocessing, compared to what is available in SQL. Existing preprocessing, data ingestion, and dataquality processes can be converted from Java/Spark into Java UDFs.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content