This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcing DataOps DataQuality TestGen 3.0: Open-Source, Generative DataQuality Software. You don’t have to imagine — start using it today: [link] Introducing DataQuality Scoring in Open Source DataOps DataQuality TestGen 3.0! DataOps just got more intelligent.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry.
Dataquality is crucial in data pipelines because it directly impacts the validity of the business insights derived from the data. Today, many organizations use AWS Glue DataQuality to define and enforce dataquality rules on their data at rest and in transit.
It addresses many of the shortcomings of traditional data lakes by providing features such as ACID transactions, schema evolution, row-level updates and deletes, and time travel. In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient.
There are countless examples of big data transforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about datavisualization and its role in the big data movement.
Today, we are pleased to announce that Amazon DataZone is now able to present dataquality information for data assets. Other organizations monitor the quality of their data through third-party solutions. Additionally, Amazon DataZone now offers APIs for importing dataquality scores from external systems.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
If the data is not easily gathered, managed and analyzed, it can overwhelm and complicate decision-makers. Data insight techniques provide a comprehensive set of tools, data analysis and quality assurance features to allow users to identify errors, enhance dataquality, and boost productivity.’
In order to figure out why the numbers in the two reports didn’t match, Steve needed to understand everything about the data that made up those reports – when the report was created, who created it, any changes made to it, which system it was created in, etc. Enterprise data governance. Metadata in data governance.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key.
Some customers build custom in-house data parity frameworks to validate data during migration. Others use open source dataquality products for data parity use cases. This takes away important person hours from the actual migration effort into building and maintaining a data parity framework.
To marry the epidemiological data to the population data it will require a tremendous amount of data intelligence about the: Source of the data; Currency of the data; Quality of the data; and. Unraveling Data Complexities with Metadata Management. Data lineage to support impact analysis.
As I recently noted , the term “data intelligence” has been used by multiple providers across analytics and data for several years and is becoming more widespread as software providers respond to the need to provide enterprises with a holistic view of data production and consumption.
If you are not observing and reacting to the data, the model will accept every variant and it may end up one of the more than 50% of models, according to Gartner , that never make it to production because there are no clear insights and the results have nothing to do with the original intent of the model.
These layers help teams delineate different stages of data processing, storage, and access, offering a structured approach to data management. In the context of Data in Place, validating dataquality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
Everyone has to manage raw data at one point or another; yet, not everybody stores it in a way that’s useful for further analysis or comparison to other data sets. As data sets become bigger, it becomes harder to visualize information. Draw a chart highlighting each endpoint in your data.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
These tools range from enterprise service bus (ESB) products, data integration tools; extract, transform and load (ETL) tools, procedural code, application program interfaces (API)s, file transfer protocol (FTP) processes, and even business intelligence (BI) reports that further aggregate and transform data. Who are the data owners?
As organizations become data-driven and awash in an overwhelming amount of data from multiple data sources (AI, IoT, ML, etc.), they will find new ways to get a handle on dataquality and focus on data management processes and best practices.
And all of them are asking hard questions: “Can you integrate my data, with my particular format?”, “How well can you scale?”, “How many visualizations do you offer?”. Nowadays, data analytics doesn’t exist on its own. You have to take care of data extraction, transformation and loading, and of visualization.
And it exists across these hybrid architectures in different formats: big and unstructured and traditional structured business data may physically sit in different places. What’s desperately needed is a way to understand the relationships and interconnections between so many entities in data sets in detail. Nine Steps to Data Modeling.
A data catalog benefits organizations in a myriad of ways. With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, dataquality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects.
We also looked at data preparation, governance and intelligence to see where organizations might be getting stuck and spending lots of time. Dataquality and accuracy are recurring themes as well. Because without current and accurate data, a data governance initiative will fall apart.
Metadata Management is the Key to Successful Data Governance Learn more in the webinar, "Metadata Management Automation for the Governance Minded" Watch the Webinar! BCBS 239 and Automated Metadata Management Tools. You may recognize the common thread running through all of these principles: Metadata.
Data fabric is an architecture that enables the end-to-end integration of various data pipelines and cloud environments through the use of intelligent and automated systems. The fabric, especially at the active metadata level, is important, Saibene notes.
However, enterprise data generated from siloed sources combined with the lack of a data integration strategy creates challenges for provisioning the data for generative AI applications. Implement data privacy policies. Implement dataquality by data type and source.
BI software uses algorithms to extract actionable insights from a company’s data and guide its strategic decisions. BI users analyze and present data in the form of dashboards and various types of reports to visualize complex information in an easier, more approachable way. 6) Smart and faster reporting. click to enlarge**.
How much time has your BI team wasted on finding data and creating metadata management reports? BI groups spend more than 50% of their time and effort manually searching for metadata. In fact, BI projects used to take many months to complete and require huge numbers of IT professionals to extract data. Cube to the rescue.
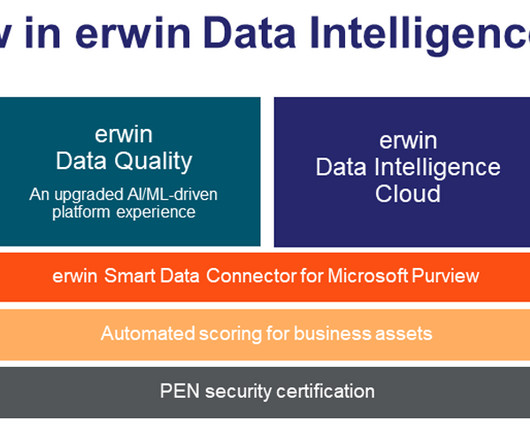
Added dataquality capability ready for an AI era Dataquality has never been more important than as we head into this next AI-focused era. erwin DataQuality is the dataquality heart of erwin Data Intelligence. erwin DataQuality is the dataquality heart of erwin Data Intelligence.
It’s the preferred choice when customers need more control and customization over the data integration process or require complex transformations. This flexibility makes Glue ETL suitable for scenarios where data must be transformed or enriched before analysis.
BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions. To gain employee buy-in, Stout’s team builds BI dashboards to show them how they can easily connect to and interact with their data, as well as visualize it in a meaningful way.
Solution overview OneData defines three personas: Publisher – This role includes the organizational and management team of systems that serve as data sources. Responsibilities include: Load raw data from the data source system at the appropriate frequency. Provide and keep up to date with technical metadata for loaded data.
Data governance also relies on business process modeling and analysis to drive improvement , including identifying business practices susceptible to security, compliance or other risks and adding controls to mitigate exposures. The lack of a central metadata repository is a far too common thorn in an organization’s side.
Are you an aspiring data scientist , or just want to understand the benefits of integrating data catalogs with visualization tools? In today’s ever-growing world of data, having an easy way to gain insights quickly is essential. What are datavisualization tools?
DataOps is an approach to best practices for data management that increases the quantity of data analytics products a data team can develop and deploy in a given time while drastically improving the level of dataquality. Automated workflows for data product creation, testing and deployment.
Easily and securely prepare, share, and query data – This session shows how you can use Lake Formation and the AWS Glue Data Catalog to share data without copying, transform and prepare data without coding, and query data. DataZone automatically manages the permissions of your shared data in the DataZone projects.
The right self-serve data prep solution can provide easy-to-use yet sophisticated data prep tools that are suitable for your business users, and enable data preparation techniques like: Connect and Mash Up Auto Suggesting Relationships JOINS and Types Sampling and Outliers Exploration, Cleaning, Shaping Reducing and Combining Data Insights (DataQuality (..)
The Data Fabric paradigm combines design principles and methodologies for building efficient, flexible and reliable data management ecosystems. Knowledge Graphs are the Warp and Weft of a Data Fabric. To implement any Data Fabric approach, it is essential to be able to understand the context of data.
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content