This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Race For DataQuality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure dataquality in every layer ?
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQualityMetrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. These rules commonly assess the data based on fixed criteria reflecting the current business state. In this post, we demonstrate how this feature works with an example.
While RAG leverages nearest neighbor metrics based on the relative similarity of texts, graphs allow for better recall of less intuitive connections. A generalized, unbundled workflow A more accountable approach to GraphRAG is to unbundle the process of knowledge graph construction, paying special attention to dataquality.
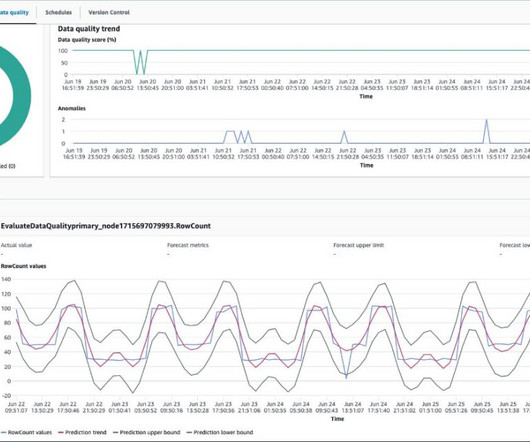
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues.
Key Success Metrics, Benefits, and Results for Data Observability Using DataKitchen Software Lowering Serious Production Errors Key Benefit Errors in production can come from many sources – poor data, problems in the production process, being late, or infrastructure problems. DataKitchen Customer Quotes “.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Companies are no longer wondering if data visualizations improve analyses but what is the best way to tell each data-story. 2020 will be the year of dataquality management and data discovery: clean and secure data combined with a simple and powerful presentation. 1) DataQuality Management (DQM).
Today, we are pleased to announce that Amazon DataZone is now able to present dataquality information for data assets. Other organizations monitor the quality of their data through third-party solutions. Additionally, Amazon DataZone now offers APIs for importing dataquality scores from external systems.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. These rules assess the data based on fixed criteria reflecting current business states. We are excited to talk about how to use dynamic rules , a new capability of AWS Glue DataQuality.
In recent years, data lakes have become a mainstream architecture, and dataquality validation is a critical factor to improve the reusability and consistency of the data. In this post, we provide benchmark results of running increasingly complex dataquality rulesets over a predefined test dataset.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
Alerts and notifications play a crucial role in maintaining dataquality because they facilitate prompt and efficient responses to any dataquality issues that may arise within a dataset. This proactive approach helps mitigate the risk of making decisions based on inaccurate information.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. After training, the system can make predictions (or deliver other results) based on data it hasn’t seen before. Machine learning adds uncertainty.
While sometimes it’s okay to follow your instincts, the vast majority of your business-based decisions should be backed by metrics, facts, or figures related to your aims, goals, or initiatives that can ensure a stable backbone to your management reports and business operations. Quantitative data analysis focuses on numbers and statistics.
Some will argue that observability is nothing more than testing and monitoring applications using tests, metrics, logs, and other artifacts. That’s a fair point, and it places emphasis on what is most important – what best practices should data teams employ to apply observability to data analytics. It’s not about dataquality
It’s the preferred choice when customers need more control and customization over the data integration process or require complex transformations. This flexibility makes Glue ETL suitable for scenarios where data must be transformed or enriched before analysis. The status and statistics of the CDC load are published into CloudWatch.
The purpose is not to track every statistic possible, as you risk being drowned in data and losing focus. Inclusivity: Expanding on decision-making, as these kinds of dashboards and reports serve up digestible data visualizations, members of your IT department will be able to use these reporting tools with ease, even under pressure.
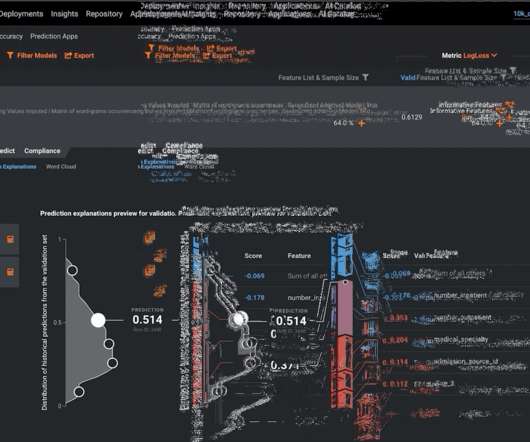
Residual plots place input data and predictions into a two-dimensional visualization where influential outliers, data-quality problems, and other types of bugs often become plainly visible. For model training and selection, we recommend considering fairness metrics when selecting hyperparameters and decision cutoff thresholds.
By collecting and evaluating large amounts of data, HR managers can make better personnel decisions faster that are not (only) based on intuition and experience. However, it is often unclear where the data needed for reporting is stored and what quality it is in.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. It is essential for optimizing read and write performance. The default output is log based.
Based on business rules, additional dataquality tests check the dimensional model after the ETL job completes. While implementing a DataOps solution, we make sure that the pipeline has enough automated tests to ensure dataquality and reduce the fear of failure. Data Completeness – check for missing data.
GE formed its Digital League to create a data culture. One of the keys for our success was really focusing that effort on what our key business initiatives were and what sorts of metrics mattered most to our customers. Chapin also mentioned that measuring cycle time and benchmarking metrics upfront was absolutely critical. “It
Facts, events, statements, and statistics without proper context have little value and only lead to questions and confusion.?This This is true for life in general, but it’s especially applicable to the data you use to power your business. Dataquality vs data condition: basic definitions & differences.
In addition to the tracking of relationships and qualitymetrics, DataOps Observability journeys allow users to establish baselines?concrete concrete expectations for run schedules, run durations, dataquality, and upstream and downstream dependencies. An interface for both business and technical users.
Data scientists usually build models for data-driven decisions asking challenging questions that only complex calculations can try to answer and creating new solutions where necessary. Programming and statistics are two fundamental technical skills for data analysts, as well as data wrangling and data visualization.
Hopefully, with metrics in place, you can show measured improvements in productivity and quality that will win converts. Improve Collaboration, both Inter- and Intra -team – If the individuals in your data-analytics team don’t work together, it can impact analytics-cycle time, dataquality, governance, security and more.
DataOps is an approach to best practices for data management that increases the quantity of data analytics products a data team can develop and deploy in a given time while drastically improving the level of dataquality. Continuous pipeline monitoring with SPC (statistical process control). Results (i.e.
Although adding noise slightly reduces output accuracy (this is the “cost” of differential privacy), it does not compromise utility or dataquality compared to traditional data masking techniques. Utility AI models require sufficient data for effective training and obtaining real datasets can be time-consuming.
Data observability provides insight into the condition and evolution of the data resources from source through the delivery of the data products. Barr Moses of Monte Carlo presents it as a combination of data flow, dataquality, data governance, and data lineage.
For example, after a Matillion job completes, DataKitchen pulls runtime variables like rowCount, invalid orders, and invalid zip codes and can perform historical balance, location balance, and statistical process control on these values.
Applied to business, it is used to analyze current and historical data in order to better understand customers, products, and partners and to identify potential risks and opportunities for a company. The accuracy of the predictions depends on the data used to create the model. Graph Analytics.
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI). This can help identify any discrepancies in data values or data types.
However, often the biggest stumbling block is a human one, getting people to buy in to the idea that the care and attention they pay to data capture will pay dividends later in the process. These and other areas are covered in greater detail in an older article, Using BI to drive improvements in dataquality.
In this way, a data scientist benefits from business knowledge that they might not otherwise have access to. The catalog facilitates the synergy of the domain experts’ subject matter expertise with the data scientists statistical and coding expertise. Modern data catalogs surface a wide range of data asset types.
In the morass of dataquality and TV and UV and cookie values and ab test id’s and sessions and shopper_ids we look at massive amounts of data and forget that real people are using our websites. A vast majority of us fail at this, we face bad or incomplete data and we get paralysed.
Companies with successful ML projects are often companies that already have an experimental culture in place as well as analytics that enable them to learn from data. Ensure that product managers work on projects that matter to the business and/or are aligned to strategic company metrics. That’s another pattern.
Recent statistics shed light on the realities in the world of current drug development: out of about 10,000 compounds that undergo clinical research, only 1 emerges successfully as an approved drug. The current process involves costly wet lab experiments, which are often performed multiple times to achieve statistically significant results.
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively. Support for BI reporting. Public API.
Then the claims data is ingested into the catalog (so it’s visible to analysts), after enriching it with some relevant details about the corresponding medical providers coming from a separate source. Claim Amount values will likely be used for some calculations, so convert to number, and Claim Data should be converted to date type.
These methods provided the benefit of being supported by rich literature on the relevant statistical tests to confirm the model’s validity—if a validator wanted to confirm that the input predictors of a regression model were indeed relevant to the response, they need only to construct a hypothesis test to validate the input.
If your source data structure changes or new business logic is added, the process AI can create corresponding tests on the fly, reducing the maintenance burden on your QA team. This leads to faster iteration cycles and helps maintain high dataquality standards, even as data pipelines grow morecomplex.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content