

What is Data Quality in Machine Learning?
Analytics Vidhya
JANUARY 20, 2023
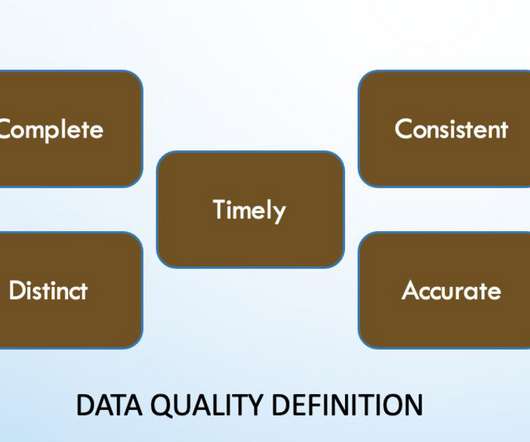
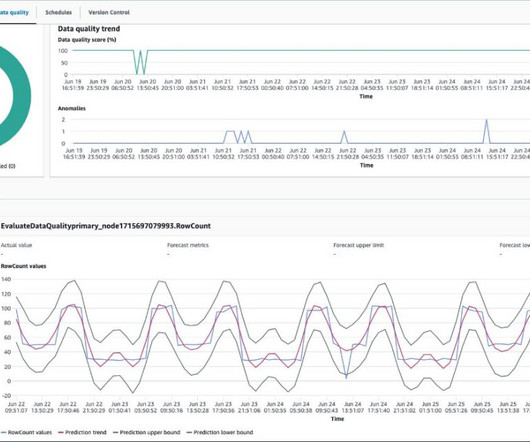
However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor data quality can lead to inaccurate predictions and poor model performance. Understanding the importance of data […] The post What is Data Quality in Machine Learning?

















































Let's personalize your content