This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. at Facebook—both from 2020.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with dataquality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor dataquality is holding back enterprise AI projects.
The hype around large language models (LLMs) is undeniable. They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. In life sciences, simple statistical software can analyze patient data.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure.
Q: Is datamodeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
In the same way as with data linking, we have to adjust our ML algorithms by giving them plenty of documents to learn from. Once developed and trained, these algorithms become the building blocks of systems that can automatically interpret data. Evaluation is for AI systems what quality assurance (QA) is for software systems.
The main reason is that it is difficult and time-consuming to consolidate, process, label, clean, and protect the information at scale to train AI models. The examples above demonstrate how expanding AI applications and unstructured data help create transformational outcomes.
It will do this, it said, with bidirectional integration between its platform and Salesforce’s to seamlessly delivers data governance and end-to-end lineage within Salesforce Data Cloud. That work takes a lot of machine learning and AI to accomplish.
Your LLM Needs a Data Journey: A Comprehensive Guide for Data Engineers The rise of Large Language Models (LLMs) such as GPT-4 marks a transformative era in artificial intelligence, heralding new possibilities and challenges in equal measure. Without this, LLMs cannot reliably interpret or generate meaningful outputs.
According to Kari Briski, VP of AI models, software, and services at Nvidia, successfully implementing gen AI hinges on effective data management and evaluating how different models work together to serve a specific use case. During the blending process, duplicate information can also be eliminated.
Newer data lakes are highly scalable and can ingest structured and semi-structureddata along with unstructured data like text, images, video, and audio. They conveniently store data in a flat architecture that can be queried in aggregate and offer the speed and lower cost required for big data analytics.
It encompasses the people, processes, and technologies required to manage and protect data assets. The Data Management Association (DAMA) International defines it as the “planning, oversight, and control over management of data and the use of data and data-related sources.”
In terms of representation, data can be broadly classified into two types: structured and unstructured. Structureddata can be defined as data that can be stored in relational databases, and unstructured data as everything else. The challenges of data. Data curation.
“Establishing data governance rules helps organizations comply with these regulations, reducing the risk of legal and financial penalties. Clear governance rules can also help ensure dataquality by defining standards for data collection, storage, and formatting, which can improve the accuracy and reliability of your analysis.”
To attain that level of dataquality, a majority of business and IT leaders have opted to take a hybrid approach to data management, moving data between cloud, on-premises -or a combination of the two – to where they can best use it for analytics or feeding AI models.
. • Structuring and deploying data sources – Connect physical metadata to specific datamodels, business terms, definitions and reusable design standards. Analyzing metadata – Understand how data relates to the business and what attributes it has. Addressing the Complexities of Metadata Management.
These include tracking, documenting, monitoring, versioning, and controlling access to AI/ML models. Currently, models are managed by modelers and by the software tools they use, which results in a patchwork of control, but not on an enterprise level. And until recently, such governance processes have been fragmented.
Ivory tower modeling We’ve seen too many models developed by isolated ontologists that don’t survive the first battle with the data. There’s a famous saying by a statistician, George Box, “All models are wrong, but some are useful.” ” So, how do you know whether your model is useful?
Some prospective projects require custom development using large language models (LLMs), but others simply require flipping a switch to turn on new AI capabilities in enterprise software. “AI A human reviews it to make sure it makes sense, and if it does, the AI incorporates that into the learning model,” she says.
Hence the drive to provide ML as a service to the Data & Tech team’s internal customers. All they would have to do is just build their model and run with it,” he says. That step, primarily undertaken by developers and data architects, established data governance and data integration. The offensive side?
The following are key attributes of our platform that set Cloudera apart: Unlock the Value of Data While Accelerating Analytics and AI The data lakehouse revolutionizes the ability to unlock the power of data. Unlike software, ML models need continuous tuning.
As part of their cloud modernization initiative, they sought to migrate and modernize their legacy data platform. Define dataquality check task to test a package, generate docs and copy the docs to required S3 location data_quality_check = BashOperator( task_id='data_quality_check', dag=dag, bash_command=''' /usr/local/airflow/.local/bin/dbt
The Semantic Web started in the late 90’s as a fascinating vision for a web of data, which is easy to interpret by both humans and machines. One of its pillars are ontologies that represent explicit formal conceptual models, used to describe semantically both unstructured content and databases.
Across the country, data scientists have an unemployment rate of 2% and command an average salary of nearly $100,000. As they attempt to put machine learning models into production, data science teams encounter many of the same hurdles that plagued data analytics teams in years past: Finding trusted, valuable data is time-consuming.
Cost: Snowflake’s pricing model is based on usage, which means you only pay for what you use. This can be more cost-effective than traditional data warehousing solutions that require a significant upfront investment. Support for multiple datastructures.
There must be a representation of the low-level technical and operational metadata as well as the ‘real world’ metadata of the business model or ontologies. Connecting the data in a graph allows concepts and entities to complement each other’s description. Consider using data catalogs for this purpose.
And before we move on and look at these three in the context of the techniques Linked Data provides, here is an important reminder in case we are wondering if Linked Data is too good to be true: Linked Data is no silver bullet. 6 Linked Data, StructuredData on the Web.
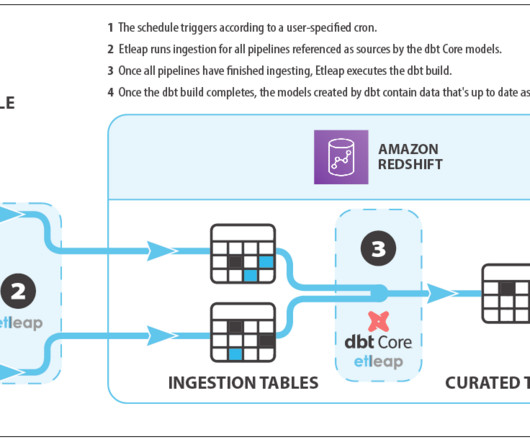
How dbt Core aids data teams test, validate, and monitor complex data transformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based data transformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
This is particularly helpful in environments where upstream data sources are subject to frequent revisions. If a dataset that normally has 10 columns suddenly shows 12 columns, for example, or if a date field starts appearing as a string, the AI model raises alerts immediately.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
According to an article in Harvard Business Review , cross-industry studies show that, on average, big enterprises actively use less than half of their structureddata and sometimes about 1% of their unstructured data. The third challenge is how to combine data management with analytics.
ETL (extract, transform, and load) technologies, streaming services, APIs, and data exchange interfaces are the core components of this pillar. Unlike ingestion processes, data can be transformed as per business rules before loading. You can apply technical or business dataquality rules and load raw data as well.
And before we move on and look at these three in the context of the techniques Linked Data provides, here is an important reminder in case we are wondering if Linked Data is too good to be true: Linked Data is no silver bullet. 6 Linked Data, StructuredData on the Web.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. This model enables the units to focus on insights, with costs aligned to actual consumption.
In Computer Science, we are trained to use the Okham razor – the simplest model of reality that can get the job done is the best one. Limiting growth by (data integration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this.
A knowledge graph can be used as a database because it structuresdata that can be queried such as through a query language like SPARQL. Reuse of knowledge from third party data providers and establishing dataquality principles to populate it. The connections made through these descriptions create context.
Specifically, the increasing amount of data being generated and collected, and the need to make sense of it, and its use in artificial intelligence and machine learning, which can benefit from the structureddata and context provided by knowledge graphs. We get this question regularly. million users.
With a wide array of data sources, including transactional databases, log files, and event streams, you need a simple-to-use solution capable of efficiently ingesting and transforming large volumes of data in real time, ensuring data cleanliness, structural integrity, and data team collaboration.
Healthcare is changing, and it all comes down to data. Leaders in healthcare seek to improve patient outcomes, meet changing business models (including value-based care ), and ensure compliance while creating better experiences. Data & analytics represents a major opportunity to tackle these challenges.
What’s been the impact of using ML models on culture and organization? Who builds their models? We also used maturity , in other words how long had an enterprise organization been deploying ML models in production? There are essentially four types encountered: image/video, audio, text, and structureddata.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content