This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We suspected that data quality was a topic brimming with interest. The responses show a surfeit of concerns around data quality and some uncertainty about how best to address those concerns. Key survey results: The C-suite is engaged with data quality. Data quality might get worse before it gets better.
Over the past 5 years, big data and BI became more than just datascience buzzwords. Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on.
Welcome to the era of data. The sheer volume of data captured daily continues to grow, calling for platforms and solutions to evolve. The Amazon Sustainability Data Initiative (ASDI) uses the capabilities of Amazon S3 to provide a no-cost solution for you to store and share climate science workloads across the globe.
Producing insights from raw data is a time-consuming process. The Importance of Exploratory Analytics in the DataScience Lifecycle. Exploratory analysis is a critical component of the datascience lifecycle. For one, Python remains the leading language for datascience research. ref: [link].
Have you ever asked a data scientist if they wanted their code to run faster? According to a poll in Kaggle’s State of Machine Learning and DataScience 2020 , A Convolutional Neural Network was the most popular deep learning algorithm used amongst polled individuals, but it was not even in the top 3. In fact only 43.2%
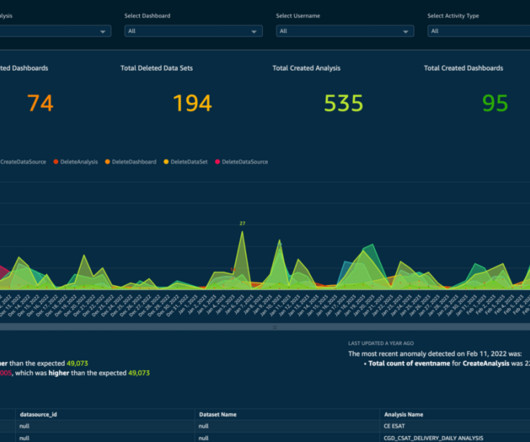
The AWS Professional Services (ProServe) Insights team builds global operational data products that serve over 8,000 users within Amazon. In this post, we discuss how QuickSight has helped us improve our performance, democratize our data, and provide insights to our internal customers at scale.
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, Machine Learning with Python for Everyone by Mark E. Feature engineering is useful for data scientists when assessing tradeoff decisions regarding the impact of their ML models.
Data scientists and researchers require an extensive array of techniques, packages, and tools to accelerate core work flow tasks including prepping, processing, and analyzing data. Utilizing NLP helps researchers and data scientists complete core tasks faster. Preprocessing Natural Language Data. Example 11.4
I frequently run into this issue in my datascience workflow with complex objects in libraries, like TensorFlow. kwonlydefaults is a dictionary with keyword-only arg default values. annotations is a dictionary specifying any type annotations. args contains the argument names. kwonlyargs lists names of keyword-only args.
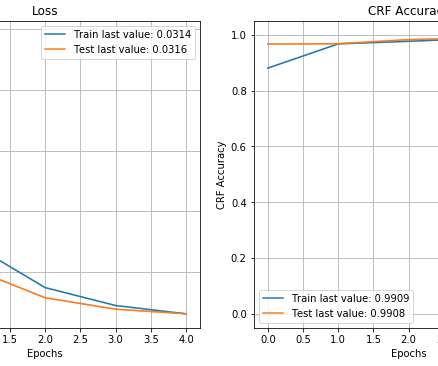
Data scientists, machine learning (ML) researchers, and business stakeholders have a high-stakes investment in the predictive accuracy of models. Data scientists and researchers ascertain predictive accuracy of models using different techniques, methodologies, and settings, including model parameters and hyperparameters. Introduction.
The model achieves relatively high accuracy and all data and code is freely available in the article. The drawback with statistical model-based techniques is that the automated extraction of a comprehensive set of rules requires a large amount of labeled training data. Data exploration and preparation.
Organizations are looking for products that let them spend less time managing data and more time on core business functions. Data security is one of the key functions in managing a data warehouse. With Immuta integration with Amazon Redshift , user and data security operations are managed using an intuitive user interface.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content