This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in datascience, realizing the return on these investments requires embedding AI deeply into business processes.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly datadriven.
Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. These changes may include requirements drift, data drift, model drift, or concept drift. encouraging and rewarding) a culture of experimentation across the organization.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. Why: Data Makes It Different. Not only is data larger, but models—deep learning models in particular—are much larger than before.
In at least one way, it was not different, and that was in the continued development of innovations that are inspired by data. This steady march of data-driven innovation has been a consistent characteristic of each year for at least the past decade.
Whereas robotic process automation (RPA) aims to automate tasks and improve process orchestration, AI agents backed by the companys proprietary data may rewire workflows, scale operations, and improve contextually specific decision-making.
This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Companies that implement DataOps find that they are able to reduce cycle times from weeks (or months) to days, virtually eliminate data errors, increase collaboration, and dramatically improve productivity.
Savvy data scientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results.
It’s official – Cloudera and Hortonworks have merged , and today I’m excited to announce the availability of Cloudera DataScience Workbench (CDSW) for Hortonworks Data Platform (HDP). Trusted by large datascience teams across hundreds of enterprises —. Sound familiar? What is CDSW?
Today, we announced the latest release of Domino’s datascience platform which represents a big step forward for enterprise datascience teams. You can identify data drift, missing information, and other issues, and take corrective action before bigger problems occur.
AGI (Artificial General Intelligence): AI (Artificial Intelligence): Application of Machine Learning algorithms to robotics and machines (including bots), focused on taking actions based on sensory inputs (data). Analytics: The products of Machine Learning and DataScience (such as predictive analytics, health analytics, cyber analytics).
In 2018 we saw the “datascience platform” market rapidly crystallize into three distinct product segments. Over the last couple years, it would be hard to blame anyone for being overwhelmed looking at the datascience platform market landscape. Proprietary (often GUI-driven) datascience platforms.
The following is a summary list of the key data-related priorities facing ICSs during 2022 and how we believe the combined Snowflake & DataRobot AI Cloud Platform stack can empower the ICS teams to deliver on these priorities. Key Data Challenges for Integrated Care Systems in 2022. Building data communities.
Data and big data analytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for big data and analytics skills and certifications.
From a technical perspective, it is entirely possible for ML systems to function on wildly different data. For example, you can ask an ML model to make an inference on data taken from a distribution very different from what it was trained on—but that, of course, results in unpredictable and often undesired performance. I/O validation.
Some IT organizations elected to lift and shift apps to the cloud and get out of the data center faster, hoping that a second phase of funding for modernization would come. There are similar concerns for CIOs looking to build data and analytics capabilities. Release an updated data viz, then automate a regression test.
Due to the convergence of events in the data analytics and AI landscape, many organizations are at an inflection point. Furthermore, a global effort to create new data privacy laws, and the increased attention on biases in AI models, has resulted in convoluted business processes for getting data to users. Data governance.
Pre-pandemic, high-performance teams were co-located, multidisciplinary, self-organizing, agile, and data-driven. These teams focused on delivering reliable technology capabilities, improving end-user experiences, and establishing data and analytics capabilities.
The tools include sophisticated pipelines for gathering data from across the enterprise, add layers of statistical analysis and machine learning to make projections about the future, and distill these insights into useful summaries so that business users can act on them. Visual IDE for data pipelines; RPA for rote tasks. Highlights.
Because things are changing and becoming more competitive in every sector of business, the benefits of business intelligence and proper use of data analytics are key to outperforming the competition. BI software uses algorithms to extract actionable insights from a company’s data and guide its strategic decisions.
After all, every department is pressured to drive efficiencies and is clamoring for automation, data capabilities, and improvements in employee experiences, some of which could be addressed with generative AI. As every CIO can attest, the aggregate demand for IT and data capabilities is straining their IT leadership teams.
DataRobot on Azure accelerates the machine learning lifecycle with advanced capabilities for rapid experimentation across new data sources and multiple problem types. This generates reliable business insights and sustains AI-driven value across the enterprise.
Businesses had to literally switch operations, and enable better collaboration and access to data in an instant — while streamlining processes to accommodate a whole new way of doing things. This year, we hope to see even more stories of ML and AI driven innovation among the finalists. That’s really important.
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) and data sources residing in AWS, on-premises, or other cloud systems using SQL or Python. Solution overview Data scientists are generally accustomed to working with large datasets.
After all, 41% of employees acquire, modify, or create technology outside of IT’s visibility , and 52% of respondents to EY’s Global Third-Party Risk Management Survey had an outage — and 38% reported a data breach — caused by third parties over the past two years. There may be times when department-specific data needs and tools are required.
Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well. To find optimal values of two parameters experimentally, the obvious strategy would be to experiment with and update them in separate, sequential stages.
This post is for people making technology decisions, by which I mean datascience team leads, architects, dev team leads, even managers who are involved in strategic decisions about the technology used in their organizations. Suppose you have an “expensive” function to run repeatedly over data records. Introduction. ray.remote?
Originally posted on Open DataScience (ODSC). In this article, we share some data-driven advice on how to get started on the right foot with an effective and appropriate screening process. Designing a DataScience Interview Onsite interviews are indispensable, but they are time-consuming.
The partners say they will create the future of digital manufacturing by leveraging the industrial internet of things (IIoT), digital twin , data, and AI to bring products to consumers faster and increase customer satisfaction, all while improving productivity and reducing costs. Data and AI as digital fundamentals.
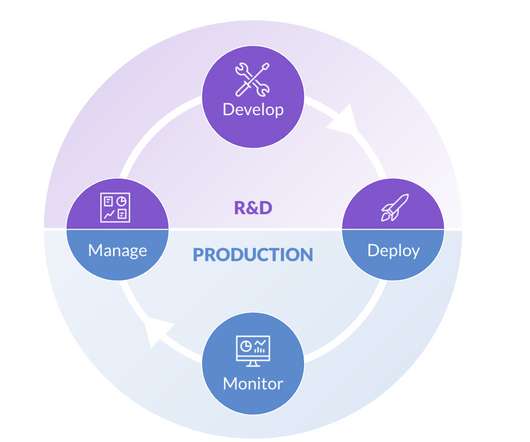
The datascience lifecycle (DLSC) has been defined as an iterative process that leads from problem formulation to exploration, algorithmic analysis and data cleaning to obtaining a verifiable solution that can be used for decision making. The datascience process in a business environment begins with the Manage stage.
Paco Nathan ‘s latest article covers program synthesis, AutoPandas, model-drivendata queries, and more. In other words, using metadata about datascience work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in datascience work is concentrated.
In especially high demand are IT pros with software development, datascience and machine learning skills. Government agencies and nonprofits also seek IT talent for environmental data analysis and policy development.
This Domino DataScience Field Note covers Chris Wiggins ‘s recent data ethics seminar at Berkeley. Data Scientists, Tradeoffs, and Data Ethics. As more companies become model-driven , data scientists are uniquely positioned to drive innovation and to help their companies remain economically strong.
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on Data Collection.
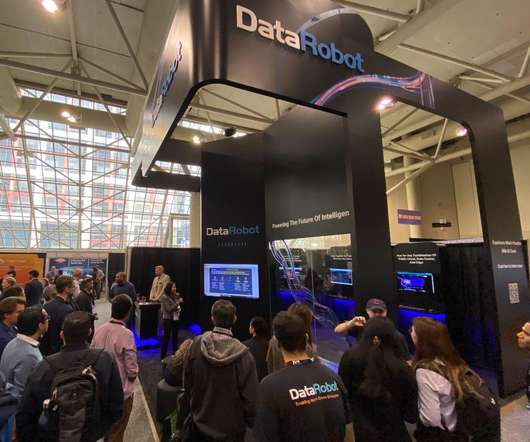
Organizations are looking for AI platforms that drive efficiency, scalability, and best practices, trends that were very clear at Big Data & AI Toronto. DataRobot Booth at Big Data & AI Toronto 2022. Monitoring and Managing AI Projects with Model Observability. Accelerating Value-Realization with Industry Specific Use Cases.
Guest post by Jeff Melching, Distinguished Engineer / Chief Architect Data & Analytics. We’ve developed a model-driven software platform, called Climate FieldView , that captures, visualizes, and analyzes a vast array of data for farmers and provides new insight and personalized recommendations to maximize crop yield.
But with all the excitement and hype, it’s easy for employees to invest time in AI tools that compromise confidential data or for managers to select shadow AI tools that haven’t been through security, data governance, and other vendor compliance reviews.
The decision to launch this pilot phase was driven by a desire to stay ahead in the field, assess the potential applications of gen AI, and subsequently transition into targeted proof-of-concept projects,” says Vlad-George Iacob, vice president of engineering at Hackajob. IT leaders should create a “safe space” for innovation, Iacob says.
An enterprise starts by using a framework to formalize its processes and procedures, which gets increasingly difficult as datascience programs grow. As a business becomes model driven, Model Risk Management can help limit risks for sustainable growth in almost any industry vertical. Types of Model Risk. Model implementation.
Everyone wants to get more out of their data, but how exactly to do that can leave you scratching your head. One of the simplest ways to start exploring your data is to aggregate the metrics you are interested in by their relevant dimensions. How can good data lead to faulty conclusions? How does this happen? 9/10 = 90%.
This Domino DataScience Field Note covers a proposed definition of interpretability and distilled overview of the PDR framework. Yet, despite the complexity (or because of it), data scientists and researchers curate and use different languages, tools, packages, techniques, and frameworks to tackle the problem they are trying to solve.
Organizations are looking to deliver more business value from their AI investments, a hot topic at Big Data & AI World Asia. At the well-attended datascience event, a DataRobot customer panel highlighted innovation with AI that challenges the status quo. Automate with Rapid Iteration to Get to Scale and Compliance.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Without large amounts of labeled training data solving most AI problems is not possible.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content