This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner.
According to data from PayScale, $99,842 is the average base salary for a data scientist in 2024. Check out our list of top big data and data analytics certifications.) The exam consists of 60 questions and the candidate has 90 minutes to complete it.
Pruitt says the airport’s new capabilities provide data-driven insights for improving operations, passenger experience, and non-aeronautical revenue across airport business units. Applying AI to elevate ROI Pruitt and Databricks recently finished a pilot test with Microsoft called Smart Flow.
Although CRISP-DM is not perfect , the CRISP-DM framework offers a pathway for machine learning using AzureML for Microsoft Data Platform professionals. AI vs ML vs DataScience vs Business Intelligence. They may also learn from evidence, but the data and the modelling fundamentally comes from humans in some way.
As one of the world’s largest biopharmaceutical companies, AstraZeneca pushes the boundaries of science to deliver life-changing medicines that create enduring value for patients and society. Before AI Bench, every datascience project was like a separate IT project. We would spend weeks getting the right environment in place.”.
Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance. What are the four types of data analytics? Data analytics and datascience are closely related.
We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP — Apache Hive , Apache Impala , and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. This variety can result in a lack of standardization, leading to data duplication and inconsistency.
The goal of DataOps Observability is to provide visibility of every journey that data takes from source to customer value across every tool, environment, data store, data and analytic team, and customer so that problems are detected, localized and raised immediately. A data journey spans and tracks multiple pipelines.
The downstream consumers consist of business intelligence (BI) tools, with multiple datascience and data analytics teams having their own WLM queues with appropriate priority values. Consequently, there was a fivefold rise in data integrations and a fivefold increase in ad hoc queries submitted to the Redshift cluster.
In the fast-evolving landscape of datascience and machine learning, efficiency is not just desirable—it’s essential. Imagine a world where every data practitioner, from seasoned data scientists to budding developers, has an intelligent assistant at their fingertips.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and datascience use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. A question arises on what level of details we need to include in the table metadata.
Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x. Modak Nabu relies on a framework of “Botworks”, a series of micro-jobs to accomplish various datatransformation steps from ingestion to profiling, and indexing. Cloud Speed and Scale.
Be sure test cases represent the diversity of app users. As an AI product manager, here are some important data-related questions you should ask yourself: What is the problem you’re trying to solve? What datatransformations are needed from your data scientists to prepare the data? The perfect fit.
Datatransforms businesses. That’s where the data lifecycle comes into play. Managing data and its flow, from the edge to the cloud, is one of the most important tasks in the process of gaining data intelligence. .
Having run a data engineering program at Insight for several years, we’ve identified three broad categories of data engineers: Software engineers who focus on building data pipelines. In some cases, they work to deploy datascience models into production with an eye towards optimization, scalability and maintainability.
The problem is that a new unique identifier of a test example won’t be anywhere in the tree. Feature extraction means moving from low-level features that are unsuitable for learning—practically speaking, we get poor testing results—to higher-level features which are useful for learning. Separate out a hold-out test set.
Powered by cloud computing, more data professionals have access to the data, too. Data analysts have access to the data warehouse using BI tools like Tableau; data scientists have access to datascience tools, such as Dataiku. Better Data Culture. Good data warehouses should be reliable.
No more lock-in, unnecessary datatransformations, or data movement across tools and clouds just to extract insights out of the data. Exploratory datascience and visualization: Access Iceberg tables through auto-discovered CDW connection in CML projects.
Example data The following code shows an example of raw order data from the stream: Record1: { "orderID":"101", "email":" john. To address the challenges with the raw data, we can implement a comprehensive datatransformation process using Redshift ML integrated with an LLM in an ETL workflow.
In perhaps a preview of things to come next year, we decided to test how a Data Catalog might work with Tableau on the same data. You can check out a self service data prep flow from catalog to viz in this recorded version here. Rita Sallam Introduces the Data Prep Rodeo. It’s a process.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks. Within the watsonx.ai
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. But what does this mean from a practitioner perspective?
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machine learning life cycles.
Through meticulous testing and research, we’ve curated a list of the ten best BI tools, ensuring accessibility and efficacy for businesses of all sizes. In essence, the core capabilities of the best BI tools revolve around four essential functions: data integration, datatransformation, data visualization, and reporting.
It may well be that one thing that a CDO needs to get going is a datatransformation programme. This may purely be focused on cultural aspects of how an organisation records, shares and otherwise uses data. It may be to build a new (or a first) Data Architecture. Creating and managing a DataScience capability.
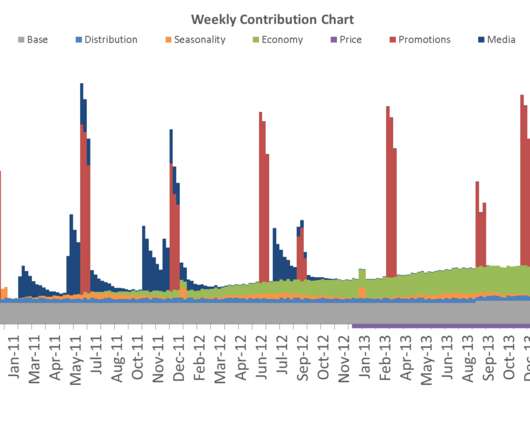
Before the data is put into the model comes a process called feature engineering – transforming the original data columns to impose certain business assumptions or simply increase model accuracy. The classical approach is to assume the adstock function (typically linear ) and test out various values of ? Request a demo.
The Project Kernel framework utilizes templates and AI augmentation to streamline coding processes, with the AI augmentation generating test cases using training models built on the organization’s data, use cases, and past test cases. This enabled the team to expose the technology to a small group of senior leaders to test.
Conduct data quality tests on anonymized data in compliance with data policies Conduct data quality tests to quickly identify and address data quality issues, maintaining high-quality data at all times. The challenge Data quality tests require performing 1,300 tests on 10 TB of data monthly.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content