This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Designing a deeplearningmodel that will predict degradation rates at each base of an RNA molecule using the Eterna dataset comprising over 3000 RNA molecules.
Rapidminer is a visual enterprise datascience platform that includes data extraction, data mining, deeplearning, artificial intelligence and machine learning (AI/ML) and predictive analytics. Rapidminer Studio is its visual workflow designer for the creation of predictivemodels.
Imagine diving into the details of data analysis, predictivemodeling, and ML. The concept of DataScience was first used at the start of the 21st century, making it a relatively new area of research and technology.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction DeepLearning is a very powerful tool that has now. The post Pneumonia Prediction: A guide for your first CNN project appeared first on Analytics Vidhya.
Datascience has become an extremely rewarding career choice for people interested in extracting, manipulating, and generating insights out of large volumes of data. To fully leverage the power of datascience, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in datascience, realizing the return on these investments requires embedding AI deeply into business processes.
An education in datascience can help you land a job as a data analyst , data engineer , data architect , or data scientist. Here are the top 15 datascience boot camps to help you launch a career in datascience, according to reviews and data collected from Switchup.
Introduction Machine learning has revolutionized the field of data analysis and predictivemodelling. With the help of machine learning libraries, developers and data scientists can easily implement complex algorithms and models without writing extensive code from scratch.
According to data from PayScale, $99,842 is the average base salary for a data scientist in 2024. Check out our list of top big data and data analytics certifications.) The exam is designed for seasoned and high-achiever datascience thought and practice leaders.
2) MLOps became the expected norm in machine learning and datascience projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
Why is high-quality and accessible data foundational? The assumed value of data is a myth leading to inflated valuations of start-ups capturing said data. Generating data with a pre-specified analysis plan and running that analysis is good. Re-analyzing existing data is often very bad.”
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearningmodel.
The objective here is to brainstorm on potential security vulnerabilities and defenses in the context of popular, traditional predictivemodeling systems, such as linear and tree-based models trained on static data sets. It seems entirely possible to do the same with customer or transactional data.
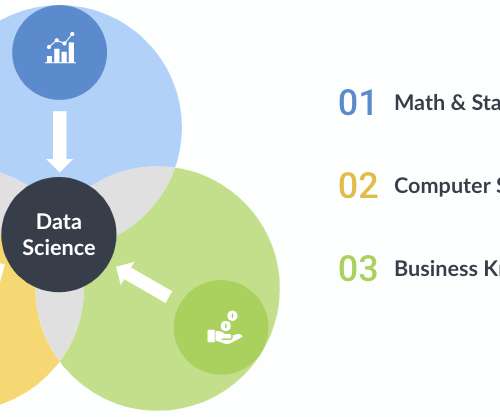
Datascience is an exciting, interdisciplinary field that is revolutionizing the way companies approach every facet of their business. DataScience — A Venn Diagram of Skills. Datascience encapsulates both old and new, traditional and cutting-edge. 3 Components of DataScience Skills.
Beyond the early days of data collection, where data was acquired primarily to measure what had happened (descriptive) or why something is happening (diagnostic), data collection now drives predictivemodels (forecasting the future) and prescriptive models (optimizing for “a better future”).
Predictive analytics, sometimes referred to as big data analytics, relies on aspects of data mining as well as algorithms to develop predictivemodels. These predictivemodels can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
Some people equate predictivemodelling with datascience, thinking that mastering various machine learning techniques is the key that unlocks the mysteries of the field. However, there is much more to datascience than the What and How of predictivemodelling. on KDNuggets).
Since they consume a significant amount of time spent on most datascience projects, we highlight these two main classes of data quality problems in this post: Data unification and integration. An important paradigm for solving both these problems is the concept of data programming.
More structured approaches to sensitivity analysis include: Adversarial example searches : this entails systematically searching for rows of data that evoke strange or striking responses from an ML model. Figure 1 illustrates an example adversarial search for an example credit default ML model.
Data scientist As companies embrace gen AI, they need data scientists to help drive better insights from customer and business data using analytics and AI. For most companies, AI systems rely on large datasets, which require the expertise of data scientists to navigate.
Predictive analytics applies techniques such as statistical modeling, forecasting, and machine learning to the output of descriptive and diagnostic analytics to make predictions about future outcomes. Data analysts and others who work with analytics use a range of tools to aid them in their roles.
One of the most-asked questions from aspiring data scientists is: “What is the best language for datascience? People looking into datascience languages are usually confused about which language they should learn first: R or Python. NLP can be used on written text or speech data. R or Python?”.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? What is machine learning?
There are four properties of high dimensional data: Points move far away from each other in high dimensions. The accuracy of any predictivemodel approaches 100%. Property 4: The accuracy of any predictivemodel approaches 100%. There should be no model to accurately predict even and odd rows with random data.
And even if they’re used, they may not be enough to prevent an attacker from inferring sensitive information by analyzing encrypted or masked data patterns. The new class often uses advanced techniques such as deeplearning, natural language processing, and computer vision to analyze and extract insights from the data.
In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the datascience workflow.
What is machine learning? ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Here, we’ll discuss the five major types and their applications.
Working from datasets you already have, a Time Series Forecasting model can help you better understand seasonality and cyclical behavior and make future-facing decisions, such as reducing inventory or staff planning. To accelerate the process, you can also increase the number of modeling workers (number of jobs running at the same time).
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Text representation In this stage, you’ll assign the data numerical values so it can be processed by machine learning (ML) algorithms, which will create a predictivemodel from the training inputs.
deeplearning) there is no guaranteed explainability. We will go through a typical ML pipeline, where we do data ingestion, exploratory data analysis, feature engineering, model training and evaluation. Knowledge and Data Engineering, IEEE Transactions on, 21, 1263-1284. References. [1] Pavía, Ernesto J.
Marketers use ML for lead generation, data analytics, online searches and search engine optimization (SEO). ML algorithms and datascience are how recommendation engines at sites like Amazon, Netflix and StitchFix make recommendations based on a user’s taste, browsing and shopping cart history.
The vision of big data freed organizations to capture more data sources at lower levels of detail and in vastly greater volumes. For example, datascience always consumes “historical” data, and there is no guarantee that the semantics of older datasets are the same, even if their names are unchanged.
Chris Wiggins , Chief Data Scientist at The New York Times, presented “DataScience at the New York Times” at Rev. Wiggins also indicated that datascience, data engineering, and data analysis are different groups at The New York Times. Session Summary. Transcript. Feel free to email me.
The interest in interpretation of machine learning has been rapidly accelerating in the last decade. This can be attributed to the popularity that machine learning algorithms, and more specifically deeplearning, has been gaining in various domains. Methods for explaining DeepLearning. References.
Machine learning, artificial intelligence, data engineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of datascience, streaming, and machine learning (ML) as disruptive phenomena. 221) to 2019 (No.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content