This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. The model for natural language processing is called Minerva. Recently, experimenters have developed a very sophisticated natural language […]. Recently, experimenters have developed a very sophisticated natural language […].
This article was published as a part of the DataScience Blogathon Introduction to Statistics Statistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimentaldata or real-world studies. Data processing is […].
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in datascience, realizing the return on these investments requires embedding AI deeply into business processes.
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deep learning models in particular—are much larger than before.
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities. So, if you have 1 trillion data points (g.,
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
Here in the virtual Fast Forward Lab at Cloudera , we do a lot of experimentation to support our applied machine learning research, and Cloudera Machine Learning product development. Only through hands-on experimentation can we discern truly useful new algorithmic capabilities from hype. Not all of them require a unique front-end.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Meta-Orchestration . DevOps Infrastructure Tools.
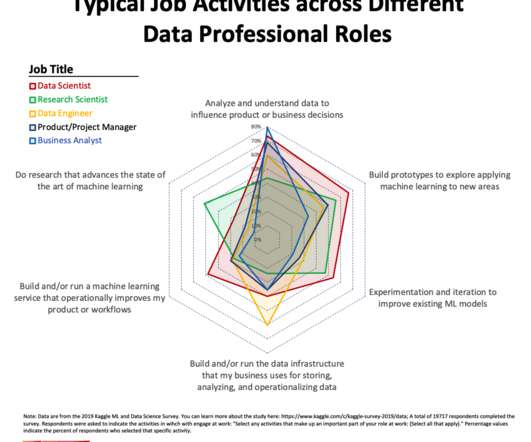
Different data roles have different work activity profiles with Data Scientists engaging in more different work activities than other data professionals. We know that data professionals, when working on datascience and machine learning projects, spend their time on a variety of different activities (e.g.,
According to data from PayScale, $99,842 is the average base salary for a data scientist in 2024. Check out our list of top big data and data analytics certifications.) The exam is designed for seasoned and high-achiever datascience thought and practice leaders.
2) MLOps became the expected norm in machine learning and datascience projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
Bayer Crop Science sees generative AI as a key catalyst for enabling thousands of its data scientists and engineers to innovate agricultural solutions for farmers across the globe. Plans for the first major release of Decision Science Ecosystem are within the next couple of months.
Even simple use cases had exceptions requiring business process outsourcing (BPO) or internal data processing teams to manage. With traditional OCR and AI models, you might get 60% straight-through processing, 70% if youre lucky, but now generative AI solves all of the edge cases, and your processing rates go up to 99%, Beckley says.
Whether it’s controlling for common risk factors—bias in model development, missing or poorly conditioned data, the tendency of models to degrade in production—or instantiating formal processes to promote data governance, adopters will have their work cut out for them as they work to establish reliable AI production lines.
Savvy data scientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. These datascience teams are seeing tremendous results—millions of dollars saved, new customers acquired, and new innovations that create a competitive advantage.
Many companies whose AI model training infrastructure is not proximal to their data lake incur steeper costs as the data sets grow larger and AI models become more complex. The cloud is great for experimentation when data sets are smaller and model complexity is light.
It’s official – Cloudera and Hortonworks have merged , and today I’m excited to announce the availability of Cloudera DataScience Workbench (CDSW) for Hortonworks Data Platform (HDP). Trusted by large datascience teams across hundreds of enterprises —. Sound familiar? What is CDSW?
Similarly, in “ Building Machine Learning Powered Applications: Going from Idea to Product ,” Emmanuel Ameisen states: “Indeed, exposing a model to users in production comes with a set of challenges that mirrors the ones that come with debugging a model.”.
I got my first datascience job in 2012, the year Harvard Business Review announced data scientist to be the sexiest job of the 21st century. Two years later, I published a post on my then-favourite definition of datascience , as the intersection between software engineering and statistics. But what does it mean?
This Domino DataScience Field Note covers Pete Skomoroch ’s recent Strata London talk. Over the years, I have listened to data scientists and machine learning (ML) researchers relay various pain points and challenges that impede their work. These steps also reflect the experimental nature of ML product management.
Today, we announced the latest release of Domino’s datascience platform which represents a big step forward for enterprise datascience teams. I’m also proud to announce an exciting new product: Domino Model Monitor (DMM). Domino’s best-in-class Workbench is now even more powerful for data scientists.
Be sure to listen to the full recording of our lively conversation, which covered Data Literacy, Data Strategy, Data Leadership, and more. The data age has been marked by numerous “hype cycles.” We build models to test our understanding, but these models are not “one and done.” The Age of Hype Cycles.
The next chapter is all about moving from experimentation to true transformation. We are helping businesses activate data as a strategic asset, with desire to maximize the impact of AI as core to the business strategy. Companies are entering “chapter two” of their digital transformation. It’s about gaining speed and scale.
Datascience is an incredibly complex field. When you factor in the requirements of a business-critical machine learning model in a working enterprise environment, the old cat-herding meme won’t even get a smile. Deploy: includes validating, publishing and delivering working models into a business environment.
CIOs seeking big wins in high business-impacting areas where there’s significant room to improve performance should review their datascience, machine learning (ML), and AI projects. Are datascience teams set up for success? Have business leaders defined realistic success criteria and areas of low-risk experimentation?
Some people equate predictive modelling with datascience, thinking that mastering various machine learning techniques is the key that unlocks the mysteries of the field. However, there is much more to datascience than the What and How of predictive modelling. The hardest parts of datascience.
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. Over the years, he has helped multiple customers on data platform transformations across industry verticals.
Analytics: The products of Machine Learning and DataScience (such as predictive analytics, health analytics, cyber analytics). A reference to a new phase in the Industrial Revolution that focuses heavily on interconnectivity, automation, Machine Learning, and real-time data. Examples: Cars, Trucks, Taxis. See [link].
The certification focuses on the seven domains of the analytics process: business problem framing, analytics problem framing, data, methodology selection, model building, deployment, and lifecycle management. Organization: Columbia University Price: Students pay Columbia Engineering’s rate of tuition (US$2,362 per credit).
Our mission at Domino is to enable organizations to put models at the heart of their business. Today we’re announcing two major new capabilities in Domino that make model development easier and faster for data scientists. This pain point is magnified in organizations with teams of data scientists working on numerous experiments.
Leveraging DataRobot’s JDBC connectors, enterprise teams can work together to train ML models on their data residing in SAP HANA Cloud and SAP Data Warehouse Cloud, as well as have an option to enrich it with data from external data sources.
In 2018 we saw the “datascience platform” market rapidly crystallize into three distinct product segments. Over the last couple years, it would be hard to blame anyone for being overwhelmed looking at the datascience platform market landscape. Proprietary (often GUI-driven) datascience platforms.
Most, if not all, machine learning (ML) models in production today were born in notebooks before they were put into production. 42% of data scientists are solo practitioners or on teams of five or fewer people. 42% of data scientists are solo practitioners or on teams of five or fewer people. Deep Dive into DataRobot Notebooks.
This Domino DataScience Field Note covers a proposed definition of interpretability and distilled overview of the PDR framework. Model interpretability continues to spark public discourse among industry. Model interpretability continues to spark public discourse among industry. Insights are drawn from Bin Yu, W.
Our mental models of what constitutes a high-performance team have evolved considerably over the past five years. Pre-pandemic, high-performance teams were co-located, multidisciplinary, self-organizing, agile, and data-driven. These sentiments align with research from Dale Carnegie on creating a culture of high-performance teams.
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. Model Visibility.
— Collaborating via Snowflake Data Cloud and DataRobot AI Cloud Platform will enable multiple organizations to build a community movement where experimentation, innovation, and creativity flourish. Looking forward through data. Grasping the digital opportunity.
With the generative AI gold rush in full swing, some IT leaders are finding generative AI’s first-wave darlings — large language models (LLMs) — may not be up to snuff for their more promising use cases. With this model, patients get results almost 80% faster than before. It’s fabulous.”
What is a data scientist? Data scientists are analytical data experts who use datascience to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist salary. Semi-structured data falls between the two.
This post is for people making technology decisions, by which I mean datascience team leads, architects, dev team leads, even managers who are involved in strategic decisions about the technology used in their organizations. Motivations for Ray: Training a Reinforcement Learning (RL) Model. Introduction. that work best.
While many organizations are successful with agile and Scrum, and I believe agile experimentation is the cornerstone of driving digital transformation, there isn’t a one-size-fits-all approach. CIOs should consider technologies that promote their hybrid working models to replace in-person meetings.
Companies are emphasizing the accuracy of machine learning models while at the same time focusing on cost reduction, both of which are important. As a DataRobot data scientist , I have worked with team members on a variety of projects to improve the business value of our customers. Sensor Data Analysis Examples.
Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well. That is true generally, not just in these experiments — spreading measurements out is generally better, if the straight-line model is a priori correct.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content