This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
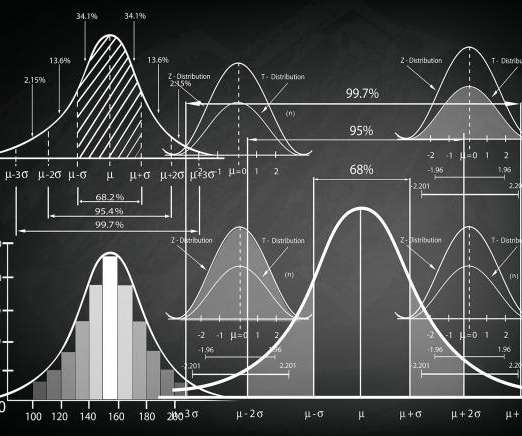
This article was published as a part of the DataScience Blogathon Introduction to StatisticsStatistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimentaldata or real-world studies. Data processing is […].
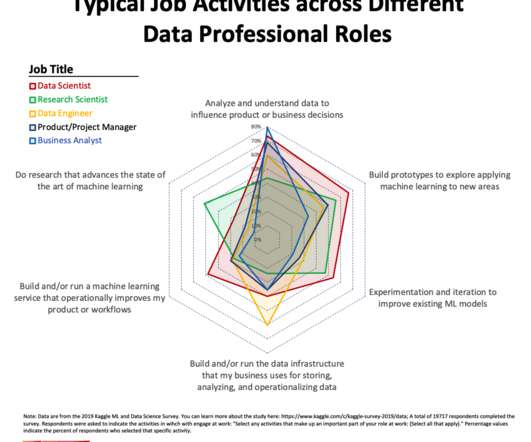
Different data roles have different work activity profiles with Data Scientists engaging in more different work activities than other data professionals. We know that data professionals, when working on datascience and machine learning projects, spend their time on a variety of different activities (e.g.,
The US Bureau of Labor Statistics (BLS) forecasts employment of data scientists will grow 35% from 2022 to 2032, with about 17,000 openings projected on average each year. According to data from PayScale, $99,842 is the average base salary for a data scientist in 2024.
Savvy data scientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. These datascience teams are seeing tremendous results—millions of dollars saved, new customers acquired, and new innovations that create a competitive advantage.
I got my first datascience job in 2012, the year Harvard Business Review announced data scientist to be the sexiest job of the 21st century. Two years later, I published a post on my then-favourite definition of datascience , as the intersection between software engineering and statistics.
Analytics: The products of Machine Learning and DataScience (such as predictive analytics, health analytics, cyber analytics). Robotics: A branch of AI concerned with creating devices that can move and react to sensory input (data). Algorithm: A set of rules to follow to solve a problem or to decide on a particular action (e.g.,
The tools include sophisticated pipelines for gathering data from across the enterprise, add layers of statistical analysis and machine learning to make projections about the future, and distill these insights into useful summaries so that business users can act on them. A free plan allows experimentation. Per user, per month.
It seems as if the experimental AI projects of 2019 have borne fruit. In 2019, 57% of respondents cited a lack of ML modeling and datascience expertise as an impediment to ML adoption; this year, slightly more—close to 58%—did so. But what kind? Where AI projects are being used within companies.
What is a data scientist? Data scientists are analytical data experts who use datascience to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist salary. Data scientist skills.
Certification of Professional Achievement in DataSciences The Certification of Professional Achievement in DataSciences is a nondegree program intended to develop facility with foundational datascience skills. How to prepare: No prior computer science or programming knowledge is necessary.
In 2018 we saw the “datascience platform” market rapidly crystallize into three distinct product segments. Over the last couple years, it would be hard to blame anyone for being overwhelmed looking at the datascience platform market landscape. Proprietary (often GUI-driven) datascience platforms.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. And we can keep repeating this approach, relying on intuition and luck. Why experiment with several parameters concurrently?
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
This article presents a case study of how DataRobot was able to achieve high accuracy and low cost by actually using techniques learned through DataScience Competitions in the process of solving a DataRobot customer’s problem. Sensor Data Analysis Examples. The Best Way to Achieve Both Accuracy and Cost Control.
by AMIR NAJMI & MUKUND SUNDARARAJAN Datascience is about decision making under uncertainty. Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature.
Some pitfalls of this type of experimentation include: Suppose an experiment is performed to observe the relationship between the snack habit of a person while watching TV. Bias can cause a huge error in experimentation results so we need to avoid them. Validity: Valid data measures what we actually intend to find out.
In the past few years, the term “datascience” has been widely used, and people seem to see it in every field. Big Data”, “Business Intelligence”, “ Data Analysis ” and “ Artificial Intelligence ” came into being. For a while, everyone seems to have begun to learn data analysis. By Michael Milton.
So how do we get totally different results when breaking the data down by gender? This is an example of Simpon’s paradox , a statistical phenomenon in which a trend that is present when data is put into groups reverses or disappears when the data is combined. It’s time to introduce a new statistical term.
The top activities across all data roles were related to analyzing data to influence decisions and building prototypes. The practice of datascience is about extracting value from data to help inform decision making and improve algorithms. But what exactly do different data professionals do at work?
In addition, Jupyter Notebook is also an excellent interactive tool for data analysis and provides a convenient experimental platform for beginners. Data Analysis Libraries. In addition to the three types of tools mentioned above, there is actually a type of data analysis library that is more suitable for advanced data analysts.
Advanced Data Discovery allows business users to perform early prototyping and to test hypothesis without the skills of a data scientist, ETL or developer. Advanced Data Discovery ensures data democratization by enabling users to drastically reduce the time and cost of analysis and experimentation.
Data scientists typically come equipped with skills in three key areas: mathematics and statistics, datascience methods, and domain expertise. Most data scientists are strong in one or two of these areas, but not all three. This frees up data scientists to focus on more complex analytical tasks.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. They have the foundations of data infrastructure. Yet, this challenge is not insurmountable.
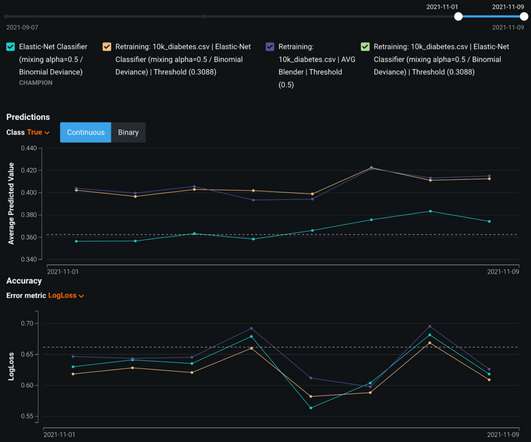
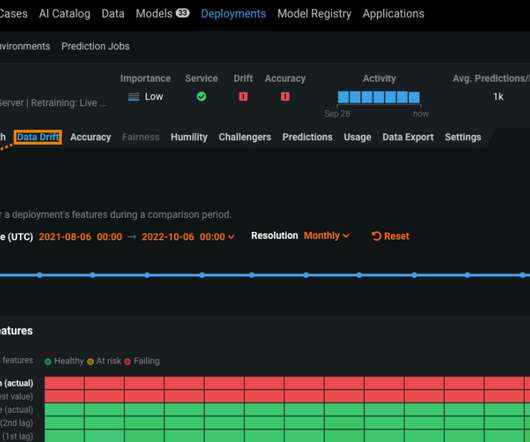
Zooming into that last week will help the user understand how quickly data is drifting and whether or not it’s a cause for concern. You might think that overall, the model’s features drifted relatively little in production, but in reality, the model’s drift statistics might be fluctuating quite a bit up and down.
But what if users don't immediately uptake the new experimental version? Background At Google, experimentation is an invaluable tool for making decisions and inference about new products and features. Naturally, this issue is of particular concern to us in the Play DataScience team.
Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. However, the downside of using a larger unit of randomization is that we lose experimental power. This simulation is based on the actual user network of GCP.
This tutorial will show how easy it is to integrate and use Pumas in the Domino DataScience Platform , and we will carry out a simple non-compartmental analysis using a freely available dataset. The Domino datascience platform empowers data scientists to develop and deliver models with open access to the tools they love.
Originally posted on Open DataScience (ODSC). In this article, we share some data-driven advice on how to get started on the right foot with an effective and appropriate screening process. Designing a DataScience Interview Onsite interviews are indispensable, but they are time-consuming. Length: Highly Variable.
Presto provides a long list of functions, operators, and expressions as part of its open source offering, including standard functions, maps, arrays, mathematical, and statistical functions. Uber chose Presto for the flexibility it provides with compute separated from data storage.
Our post describes how we arrived at recent changes to design principles for the Google search page, and thus highlights aspects of a data scientist’s role which involve practicing the scientific method. There has been debate as to whether the term “datascience” is necessary. Some don’t see the point.
This article covers causal relationships and includes a chapter excerpt from the book Machine Learning in Production: Developing and Optimizing DataScience Workflows and Applications by Andrew Kelleher and Adam Kelleher. You saw in the previous chapter that conditioning can break statistical dependence. Introduction.
To figure this out, let's consider an appropriate experimental design. In other words, the teacher is our second kind of unit, the unit of experimentation. This type of experimental design is known as a group-randomized or cluster-randomized trial. When analyzing the outcome measure (e.g.,
According to Gartner, companies need to adopt these practices: build culture of collaboration and experimentation; start with a 3-way partnership among executives leading digital initiative, line of business and IT. Also, loyalty leaders infuse analytics into CX programs, including machine learning, datascience and data integration.
By IVAN DIAZ & JOSEPH KELLY Determining the causal effects of an action—which we call treatment—on an outcome of interest is at the heart of many data analysis efforts. In an ideal world, experimentation through randomization of the treatment assignment allows the identification and consistent estimation of causal effects.
Wouldn't it be great if we didn't require individual data to estimate an aggregate effect? A geo experiment is an experiment where the experimental units are defined by geographic regions. This is a quantity that is easily interpretable and summarizes nicely the statistical power of the experiment. In the U.S.,
Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles. LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language.
This requires that data engineers embrace learning and integrating new technologies, such as AI tools. In DataOps, a variety of analytics & datascience skills , qualifications , tools, and roles are required for increased innovation and a productive team. It’s a Team Sport. Daily Interactions. Disposable environments.
Data scientists and researchers require an extensive array of techniques, packages, and tools to accelerate core work flow tasks including prepping, processing, and analyzing data. Utilizing NLP helps researchers and data scientists complete core tasks faster. Example 11.6 place an LSTM() layer. for a hands-on example.
Without clarity in metrics, it’s impossible to do meaningful experimentation. There’s a substantial literature about ethics, data, and AI, so rather than repeat that discussion, we’ll leave you with a few resources. Ongoing monitoring of critical metrics is yet another form of experimentation.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for datascience work. Instead, consider a “full stack” tracing from the point of data collection all the way out through inference. back to the structure of the dataset. Let’s look through some antidotes. Ergo, less interpretable.
1]" Statistics, as a discipline, was largely developed in a small data world. Data was expensive to gather, and therefore decisions to collect data were generally well-considered. Implicitly, there was a prior belief about some interesting causal mechanism or an underlying hypothesis motivating the collection of the data.
by MICHAEL FORTE Large-scale live experimentation is a big part of online product development. This means a small and growing product has to use experimentation differently and very carefully. This blog post is about experimentation in this regime. But these are not usually amenable to A/B experimentation.
In my opinion it’s more exciting and relevant to everyday life than more hyped datascience areas like deep learning. The book focuses on randomised controlled trials and well-defined interventions as the basis of causal inference from both experimental and observational data.
by AMIR NAJMI Running live experiments on large-scale online services (LSOS) is an important aspect of datascience. Because individual observations have so little information, statistical significance remains important to assess. We must therefore maintain statistical rigor in quantifying experimental uncertainty.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content