This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Introduction to Statistics Statistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimentaldata or real-world studies. Data processing is […]. Data processing is […].
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
It has far-reaching implications as to how such applications should be developed and by whom: ML applications are directly exposed to the constantly changing real world through data, whereas traditional software operates in a simplified, static, abstract world which is directly constructed by the developer. DataScience Layers.
Testing and Data Observability. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Genie — Distributed big data orchestration service by Netflix.
Are you ready to move beyond the basics and take a deep dive into the cutting-edge techniques that are reshaping the landscape of experimentation? Get ready to discover how these innovative approaches not only overcome the limitations of traditional A/B testing, but also unlock new insights and opportunities for optimization!
encouraging and rewarding) a culture of experimentation across the organization. These rules are not necessarily “Rocket Science” (despite the name of this blog site), but they are common business sense for most business-disruptive technology implementations in enterprises. Test early and often. Launch the chatbot.
According to data from PayScale, $99,842 is the average base salary for a data scientist in 2024. Check out our list of top big data and data analytics certifications.) The exam consists of 60 questions and the candidate has 90 minutes to complete it.
One of them is Katherine Wetmur, CIO for cyber, data, risk, and resilience at Morgan Stanley. Wetmur says Morgan Stanley has been using modern datascience, AI, and machine learning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space.
Bayer Crop Science sees generative AI as a key catalyst for enabling thousands of its data scientists and engineers to innovate agricultural solutions for farmers across the globe. Plans for the first major release of Decision Science Ecosystem are within the next couple of months.
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. Over the years, he has helped multiple customers on data platform transformations across industry verticals.
It’s official – Cloudera and Hortonworks have merged , and today I’m excited to announce the availability of Cloudera DataScience Workbench (CDSW) for Hortonworks Data Platform (HDP). Trusted by large datascience teams across hundreds of enterprises —. Sound familiar? What is CDSW?
Datascience is an incredibly complex field. Framing datascience projects within the four steps of the datascience lifecycle (DSLC) makes it much easier to manage limited resources and control timelines, while ensuring projects meet or exceed the business requirements they were designed for.
In Bringing an AI Product to Market , we distinguished the debugging phase of product development from pre-deployment evaluation and testing. During testing and evaluation, application performance is important, but not critical to success. require not only disclosure, but also monitored testing. Debugging AI Products.
Be sure to listen to the full recording of our lively conversation, which covered Data Literacy, Data Strategy, Data Leadership, and more. The data age has been marked by numerous “hype cycles.” We build models to test our understanding, but these models are not “one and done.” The Age of Hype Cycles.
This Domino DataScience Field Note covers Pete Skomoroch ’s recent Strata London talk. Pete indicates, in both his November 2018 and Strata London talks, that ML requires a more experimental approach than traditional software engineering. These steps also reflect the experimental nature of ML product management.
Some people equate predictive modelling with datascience, thinking that mastering various machine learning techniques is the key that unlocks the mysteries of the field. However, there is much more to datascience than the What and How of predictive modelling. The hardest parts of datascience.
CIOs seeking big wins in high business-impacting areas where there’s significant room to improve performance should review their datascience, machine learning (ML), and AI projects. Are datascience teams set up for success? Have business leaders defined realistic success criteria and areas of low-risk experimentation?
Organization: AWS Price: US$300 How to prepare: Amazon offers free exam guides, sample questions, practice tests, and digital training. CDP Data Analyst The Cloudera Data Platform (CDP) Data Analyst certification verifies the Cloudera skills and knowledge required for data analysts using CDP.
Models are so different from software — e.g., they require much more data during development, they involve a more experimental research process, and they behave non-deterministically — that organizations need new products and processes to enable datascience teams to develop, deploy and manage them at scale.
While many organizations are successful with agile and Scrum, and I believe agile experimentation is the cornerstone of driving digital transformation, there isn’t a one-size-fits-all approach. Here are some force-multiplying differences achievable by agile data teams: Want that dashboard, then update the data catalog.
ML model builders spend a ton of time running multiple experiments in a datascience notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. 42% of data scientists are solo practitioners or on teams of five or fewer people.
Once a datascience project has progressed through the stages of data cleaning and preparation, analysis and experimentation, modeling, testing, and evaluation, it reaches a critical point.
Another reason to use ramp-up is to test if a website's infrastructure can handle deploying a new arm to all of its users. The website wants to make sure they have the infrastructure to handle the feature while testing if engagement increases enough to justify the infrastructure. We offer two examples where this may be the case.
But most enterprises can’t operate like young startups with complete autonomy handed over to devops and datascience teams. High-performance teams are self-organizing and want significant autonomy in prioritizing work, solving problems, and leveraging technology platforms.
We present data from Google Cloud Platform (GCP) as an example of how we use A/B testing when users are connected. Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups.
Recently, Chhavi Yadav (NYU) and Leon Bottou (Facebook AI Research and NYU) indicated in their paper, “ Cold Case: The Lost MNIST Digits ”, how they reconstructed the MNIST (Modified National Institute of Standards and Technology) dataset and added 50,000 samples to the test set for a total of 60,000 samples. Did they overfit the test set?
As health and care delivery converges, analytical staff will be required to work across more boundaries with larger volumes of data than ever before. . The DataRobot and Snowflake platforms include extensive built-in trust features to enable explainability and end-to-end bias and fairness testing and monitoring over time.
To find optimal values of two parameters experimentally, the obvious strategy would be to experiment with and update them in separate, sequential stages. Our experimentation platform supports this kind of grouped-experiments analysis, which allows us to see rough summaries of our designed experiments without much work.
The companies that are most successful at marketing in both B2C and B2B are using data and online BI tools to craft hyper-specific campaigns that reach out to targeted prospects with a curated message. Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated.
In the 2023 State of DataScience and Machine Learning Report , only 18% of respondents said that at least half their machine learning models make it into production. If CIOs don’t improve conversions from pilot to production, they may find their investors losing patience in the process and culture of experimentation.
Joanne Friedman, PhD, CEO, and principal of smart manufacturing at Connektedminds, says orchestrating success in digital transformation requires a symphony of integration across disciplines : “CIOs face the challenge of harmonizing diverse disciplines like design thinking, product management, agile methodologies, and datascienceexperimentation.
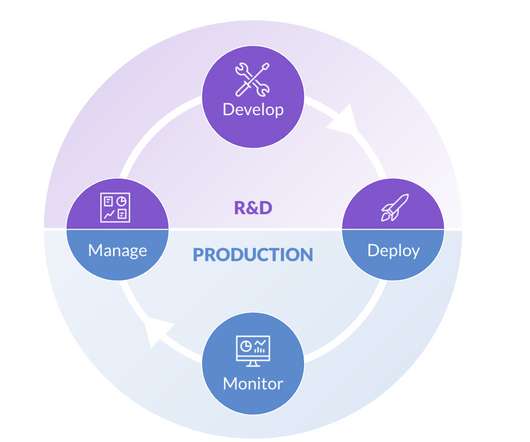
The datascience lifecycle (DLSC) has been defined as an iterative process that leads from problem formulation to exploration, algorithmic analysis and data cleaning to obtaining a verifiable solution that can be used for decision making. The datascience process in a business environment begins with the Manage stage.
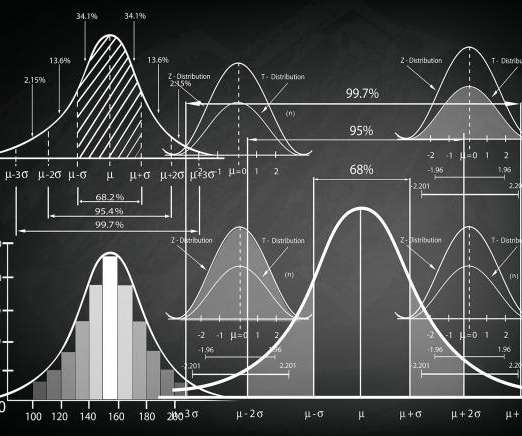
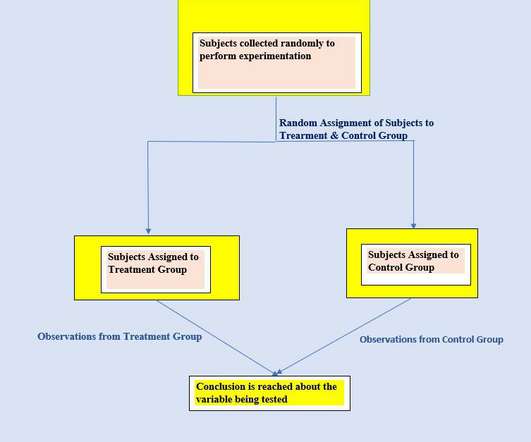
Researchers/ scientists perform experiments to validate their hypothesis/ statements or to test a new product. Suppose we want to test the effectiveness of a new drug against a particular disease. Bias can cause a huge error in experimentation results so we need to avoid them. We randomly recruit subjects for that.
Experimentation and collaboration are built into the core of the platform. This ability enhances the efficiency of operational management and optimizes the cost of experimentation. Our scientists and teams are familiar with working in Spark on EMR and using data with our existing feature store and data warehouse.
Where cloud is most effective: One area I think cloud is just going to be really effective is any area which involves experimentation and has a high opportunity cost. Because when you can experiment, you can potentially enter a new business quickly, test an idea. At its core, it is sophisticated and complex math on data.
1 for CIOs, CTOs, and CDOs is to enable secure, scalable access to a growing range of generative AI models and enable datascience teams to develop and operationalize fine-tuned LLMs tailored for the organization’s data and use cases,” says Kjell Carlsson, head of datascience strategy and evangelism at Domino.
This Domino DataScience Field Note covers Chris Wiggins ‘s recent data ethics seminar at Berkeley. He also encouraged data scientists to understand how new datascience algorithms rearrange power as well as how the history of data is a story of truth and power.
Cloud-based XaaS solutions provide scalability, flexibility and access to a wide range of AI tools and services, while on-premises XaaS offerings enable greater control over data governance, compliance and security. Embracing a culture of experimentation helps businesses drive innovation while minimizing financial risk.
In general, it is not possible to give a rule of thumb about when data should be partitioned or combined. A new drug promising to reduce the risk of heart attack was tested with two groups. Now, let’s check a slightly different case in which grouping the data leads to incorrect results. It really depends on the circumstances.
A/B testing is used widely in information technology companies to guide product development and improvements. For questions as disparate as website design and UI, prediction algorithms, or user flows within apps, live traffic tests help developers understand what works well for users and the business, and what doesn’t.
If I had more room for experimentation though, I’d definitely give svelte and solidjs a try. Everything related to spinning up a web server in development, writing code, hot reloading, running tests, cicd, deployments, etc. Honestly, the answer to this question changes every day for me. Learn JavaScript, and then TypeScript.
Given the speed required, Lowden established a specialized team for the project to encourage a culture of experimentation and “moving fast to learn fast.” “You Three layers of content integrity Another big part of ensuring the integrity of the content was testing, which consisted of three layers. We don’t write all the code.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges. Transcript.
To effectively leverage their predictive capabilities and maximize time-to-value these companies need an ML infrastructure that allows them to quickly move models from data pipelines, to experimentation and into the business. A/B testing). model packaging, deployment and serving. model monitoring. The ML Use Case.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content