This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction Machine learning is about building a predictivemodel using historical data. The post Quick Guide to Evaluation Metrics for Supervised and Unsupervised Machine Learning appeared first on Analytics Vidhya.
The way that I explained it to my datascience students years ago was like this. The semantic layer delivers data insights discovery and usability across the whole enterprise, with each business user empowered to use the terminology and tools that are specific to their role. That’s data democratization. That’s empowering.
2) MLOps became the expected norm in machine learning and datascience projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase. And the goodness doesn’t stop there.
by THOMAS OLAVSON Thomas leads a team at Google called "Operations DataScience" that helps Google scale its infrastructure capacity optimally. Over the life of the forecast, the data scientist will publish historical accuracy metrics. Our team does a lot of forecasting.
If a model is going to be used on all kinds of people, it’s best to ensure the training data has a representative distribution of all kinds of people as well. Interpretable ML models and explainable ML. The debugging techniques we propose should work on almost any kind of ML-based predictivemodel.
Hotels try to predict the number of guests they can expect on any given night in order to adjust prices to maximize occupancy and increase revenue. There are plenty of big data examples used in real life, shaping our world, be it in the buying experience or managing customers’ data.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into datamodels to ensuring ESG data integrity and fostering collaboration with sustainability teams.
This article presents a case study of how DataRobot was able to achieve high accuracy and low cost by actually using techniques learned through DataScience Competitions in the process of solving a DataRobot customer’s problem. Sensor Data Analysis Examples. The Best Way to Achieve Both Accuracy and Cost Control.
Moreover, as most predictive analytics capabilities available today are in their infancy — they have simply not been used for long enough by enough companies on enough sources of data – so the material to build predictivemodels on was quite scarce. Last but not least, there is the human factor again.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? This post will dive deeper into the nuances of each field.
Although the oil company has been producing massive amounts of data for a long time, with the rise of new cloud-based technologies and data becoming more and more relevant in business contexts, they needed a way to manage their information at an enterprise level and keep up with the new skills in the data industry.
One of the most-asked questions from aspiring data scientists is: “What is the best language for datascience? People looking into datascience languages are usually confused about which language they should learn first: R or Python. NLP can be used on written text or speech data. R or Python?”.
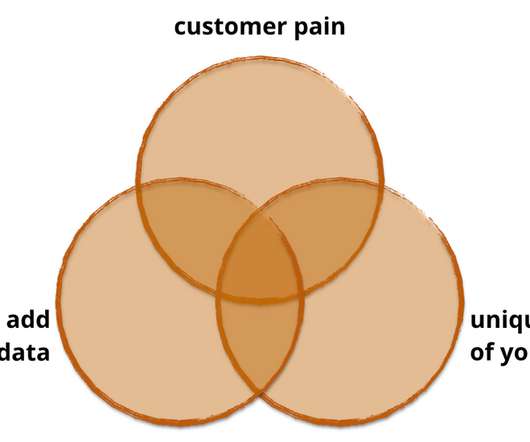
However, the data was essentially stored in old copies of the paper magazine, not a format that was conducive to delivering insights to their target audience. (3) Pain Points We’ve noticed a temptation with data products to forget the cardinal rule of any product: it needs to solve a specific problem.
In especially high demand are IT pros with software development, datascience and machine learning skills. While crucial, if organizations are only monitoring environmental metrics, they are missing critical pieces of a comprehensive environmental, social, and governance (ESG) program and are unable to fully understand their impacts.
In our world of Big Data, marketers no longer need to simply rely on their gut instincts to make marketing decisions. Through the application of datascience principles, marketing professionals now have a way of making evidence-based decisions to improve their marketing activities. underspecified) due to omitted metrics.
What if some of these datascience tasks could be automated using AI, increasing datascience productivity to tackle more AI use cases? Automating datascience tasks leaves room to build more AI applications with the same amount of datascience resources. Source: Gartner (April 2018).
Without understanding the shift in workflow, responsibilities and how the use of data will change the enterprise, it is unlikely that the business will succeed in its Citizen Data Scientist initiative.
It includes business intelligence (BI) users, canned and interactive reports, dashboards, datascience workloads, Internet of Things (IoT), web apps, and third-party data consumers. Popular consumption entities in many organizations are queries, reports, and datascience workloads.
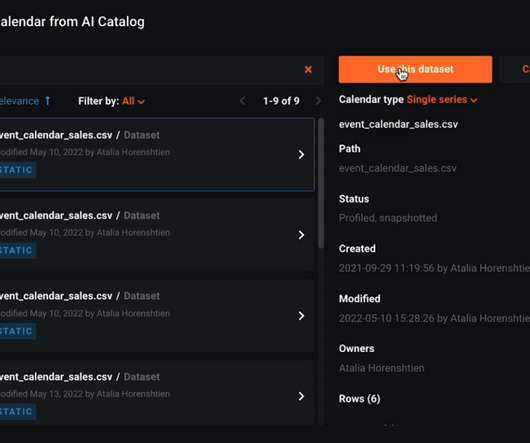
Working from datasets you already have, a Time Series Forecasting model can help you better understand seasonality and cyclical behavior and make future-facing decisions, such as reducing inventory or staff planning. A variety of models are been trained in parallel. The Leaderboard of trained models—ordered based on your metric.
Smarten CEO, Kartik Patel says, ‘Smarten SnapShot supports the evolving role of Citizen Data Scientists with interactive tools that allow a business user to gather information, establish metrics and key performance indicators.’
In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the datascience workflow.
Data scientists and researchers require an extensive array of techniques, packages, and tools to accelerate core work flow tasks including prepping, processing, and analyzing data. Utilizing NLP helps researchers and data scientists complete core tasks faster. Natural Language Processing.] together at Stanford University.
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. What is machine learning?
Linear regression is a form of supervised learning (or predictivemodeling). In supervised learning, the dependent variable is predicted from the combination of independent variables. When a single independent variable is used to predict the value of a dependent variable, it’s called simple linear regression. Clustering.
from sklearn import metrics. With this criterion in mind, we can define a distance metric to the top left corner of the curve and find a threshold that minimises it. Knowledge and Data Engineering, IEEE Transactions on, 21, 1263-1284. The class label is titled Class where 0 denotes a genuine transaction and 1 signifies fraud.
For a number of years, Gartner and other technology research and analysis firms have predicted and monitored the growth of this phenomenon. In fact, Gartner predicted that, ‘…40% of datascience tasks will be automated, resulting in increased productivity and broader usage by citizen data scientists.’
These individuals may already be ‘power users’ of business applications and may have developed and reported or presented data to others with an eye toward clarifying their decision-making. Citizen Data Scientist candidates may also be IT team members who are interested in datascience.
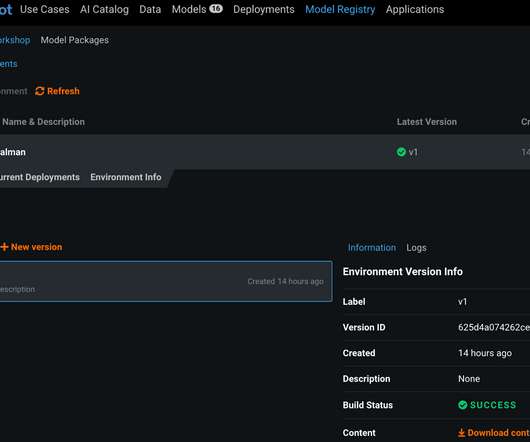
ML model builders spend a ton of time running multiple experiments in a datascience notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. Deep Dive into DataRobot Notebooks. Auto-scale compute.
By providing this course as a free online offering Smarten hopes to further support and encourage users and businesses to embrace the very real benefits of the Citizen Data Scientist approach to analytics and objective, data-driven metrics and results. About Smarten.
Whether a project aims to improve suicide prevention using datascience or to create new revenue streams by reimagining an organization’s core business, CIO 100 Award winners demonstrate the innovative spirit of today’s IT in the face of rapidly evolving organizational challenges.
‘Augmented analytics is the use of enabling technologies such as machine learning and AI to assist with data preparation, insight generation and insight explanation to augment how people explore and analyze data in analytics and BI platforms. What is self-service analytics? We should probably explain before we move on.
Marketers use ML for lead generation, data analytics, online searches and search engine optimization (SEO). ML algorithms and datascience are how recommendation engines at sites like Amazon, Netflix and StitchFix make recommendations based on a user’s taste, browsing and shopping cart history.
Adopting Augmented Analytics: How to Get Started Gartner has predicted that, in the future ‘…40% of datascience tasks will be automated, resulting in increased productivity and broader usage by citizen data scientists.’ What problems will it solve? What opportunities does it present? in the discussion.
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Text representation In this stage, you’ll assign the data numerical values so it can be processed by machine learning (ML) algorithms, which will create a predictivemodel from the training inputs.
Eighty percent of this problem is collecting the data and then transforming the data. The other 20 percent is ML- and datascience–related tasks like finding the right model, doing EDA, and feature engineering. Gathering the Data. there is a list of data sources to extract and transform. In Figure 6.1,
Intrinsic methods – this technique is based on ANNs that have been designed to output an explanation alongside the standard prediction. Because of its architecture, intrinsically explainable ANNs can be optimised not just on its prediction performance, but also on its explainability metric. References.
Bias in Machine Learning Algorithms (Bottom Photos Source: ProPublica ; Top Photos Source: Pexels.com) Biases in predictivemodeling are a widespread issue Machine learning and AI applications are used across industries, from recommendation engines to self-driving cars and more. 5 is labeled as low.
Using variability in machine learning predictions as a proxy for risk can help studio executives and producers decide whether or not to green light a film project Photo by Kyle Smith on Unsplash Originally posted on Toward DataScience. This may give a more accurate representation in the variability of predictions.
Data pipelines are designed to automate the flow of data, enabling efficient and reliable data movement for various purposes, such as data analytics, reporting, or integration with other systems. It also includes data validation and quality checks to ensure the accuracy and integrity of the data being processed.
These tools do not require IT skills or datascience knowledge. When the team uses these tools, they can adopt a common language and techniques to work with IT and data scientists to create use cases and refine and share reports, formats and outcomes.
Predictive analytics: Turning insight into foresight Predictive analytics uses historical data and statistical models or machine learning algorithms to answer the question, What is likely to happen? This is where analytics begins to proactively impact decision-making. Whats holding us back?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content