This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction According to Haines and Crounch, mathematical modelling is a process. The post Mathematical Modelling: Modelling the Spread of Diseases with SIRD Model appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction A language model in NLP is a probabilistic statistical model that determines the probability of a given sequence of words occurring in a sentence based on the previous words.
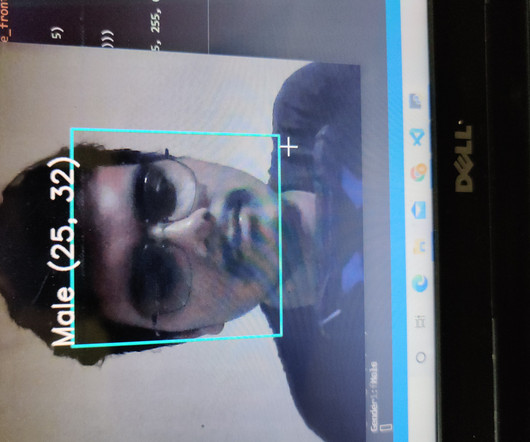
This article was published as a part of the DataScience Blogathon. Introduction In this section, we will build a face detection algorithm using Caffe model, but only OpenCV is not involved this time. The post Face detection using the Caffe model appeared first on Analytics Vidhya.
Each company hires the best tech experts to work with different algorithms and models with respect to data analytics, machine learning, artificial intelligence and so on.
Speaker: Judah Phillips, Co-CEO and Co-Founder, Product & Growth at Squark
Automating the sophisticated, complex aspects of datascience is now simple with the no-code platform Squark. Judah Phillips, the co-CEO & co-Founder of Squark answers the 5 Things You Always Wanted to Know About Automating DataScience, but Never Asked! What each model class is and how they're different from one another.
Datascience is a game-changer for marketing professionals in today’s digital age. With vast amounts of data available, marketers now have the power to unlock valuable insights and make data-driven decisions that drive business growth. appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Congratulations, you have deployed a model to production; it is an achievement for you and your team! The post What to Do After Deploying Your Model to Production? appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Building a simple Machine Learning model using Pytorch from scratch. Image by my great learning Introduction Gradient descent is an optimization algorithm that is used to train machine learning models and is now used in a neural network.
This article was published as a part of the DataScience Blogathon. link] Overview In this article, we will detail the need for data scientists to quickly develop a DataScience App, with the objective of presenting to their users and customers, the results of Machine Learning experiments.
Demand for data scientists is surging. With the number of available datascience roles increasing by a staggering 650% since 2012, organizations are clearly looking for professionals who have the right combination of computer science, modeling, mathematics, and business skills.
This article was published as a part of the DataScience Blogathon. The model for natural language processing is called Minerva. The post Minerva – Google’s Language Model for Quantitative Reasoning appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. In this article, we will learn about model explainability and the different ways to interpret a machine learning model. What is Model Explainability? Model explainability refers to the concept of being able to understand the machine learning model.
Introduction In datascience, where innovation meets opportunity, the demand for skilled professionals continues to skyrocket. Datascience is not merely a career; it’s a gateway to solving complex problems, driving innovation, and shaping the future.
This article was published as a part of the DataScience Blogathon. Introduction Topic models, an essential part of Natural Language Processing (NLP) workflows, can be used in multiple and diverse fields. The post Supervised Topic Models appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction After looking at the progress […]. The post Do Tree-based Models Outperform Deep Learning Models on Tabular Data?
This article was published as a part of the DataScience Blogathon. In deep learning, we add several hidden layers to gather the most minute details to learn the data for […]. The post Analyzing and Comparing Deep Learning Models appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon What is Anomaly Detection? Anomaly detection detects anomalies in the data. The post Multivariate Time Series Anomaly Detection using VAR model appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction The generalization of machine learning models is the ability of a model to classify or forecast new data. The post Non-Generalization and Generalization of Machine learning Models appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. In the previous articles, we have gone through the introduction, MLOps pipeline, model training, model testing, model packaging, and model registering. Introduction This article is part of blog series on Machine Learning Operations(MLOps).
This article was published as a part of the DataScience Blogathon. Introduction Asides from dedication to discovery and exploration, to succeed in a DataScience project, you must understand the process and optimize it to ensure that the results are reliable and the project is easy to follow, maintain and modify where necessary.
This article was published as a part of the DataScience Blogathon Solving Machine learning Problems in a local system is only not the case but making it able to community to use is important otherwise the model is up to you only. When it is able to serve then you came to know the feedback and […].
Imagine diving into the details of data analysis, predictive modeling, and ML. The concept of DataScience was first used at the start of the 21st century, making it a relatively new area of research and technology. Envision yourself unraveling the insights and patterns for making informed decisions that shape the future.
This article was published as a part of the DataScience Blogathon Image 1 Introduction In this article, I will use the YouTube Trends database and Python programming language to train a language model that generates text using learning tools, which will be used for the task of making youtube video articles or for your blogs. […].
This article was published as a part of the DataScience Blogathon. Introduction Kats model-which is also developed by Facebook Research Team-supports the functionality of multi-variate time-series forecasting in addition to univariate time-series forecasting.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction In 2018, GoogleAI researchers released the BERT model. However, the BERT model did have some drawbacks i.e. it was bulky and hence a little slow. It was a fantastic work that brought a revolution in the NLP domain.
This article was published as a part of the DataScience Blogathon. From this article, you will learn how to perform time series analysis using the ARIMA model (with code!). The usage time series data consist of the […]. Welcome to the World of Time Series Analysis!
This article was published as a part of the DataScience Blogathon. The post LOGOS: A Brand Independent logo detection model appeared first on Analytics Vidhya. The post LOGOS: A Brand Independent logo detection model appeared first on Analytics Vidhya. It’s a […].
This article was published as a part of the DataScience Blogathon. Various robust AI Models have been made that perform far better than the human brain, like deepfake generation, image classification, text classification, etc. The post How to Make an Image Classification Model Using Deep Learning?
This article was published as a part of the DataScience Blogathon. Machine learning is the process of learning from data and applying math to increase accuracy. The post Machine Learning Models Comparative Analysis appeared first on Analytics Vidhya. Machine learning is a part of Artificial Intelligence.
This article was published as a part of the DataScience Blogathon. Introduction Datasets are to machine learning models what experiences are to human beings. The post Outliers and Overfitting when Machine Learning Models can’t Reason appeared first on Analytics Vidhya. Have you ever witnessed a strange occurrence?
Introduction Generalized Additive Models (GAMs) constitute a powerful framework in datascience, capable of discovering complex relationships within data. Understanding GAMs is crucial for anyone navigating intricate data patterns, as they offer a unique approach to modeling non-linear dependencies.
This article was published as a part of the DataScience Blogathon. The post Image Classification Model trained using Google Colab appeared first on Analytics Vidhya. Introduction Image classification is the process of classifying and recognizing groups of pixels inside an image in line with pre-established principles.
This article was published as a part of the DataScience Blogathon. The post Audio Denoiser: A Speech Enhancement Deep Learning Model appeared first on Analytics Vidhya. Some of us may live in a noisy environment where we can […].
This article was published as a part of the DataScience Blogathon. Regression analysis is used to solve problems of prediction based on data statistical parameters. In this article, we will look at the use of a polynomial regression model on a simple example using real statistic data.
This article was published as a part of the DataScience Blogathon. It is challenging to train and monitor multiple models. It’s possible that each model has unique characteristics or parameters. Assessing and exploiting these models without suitable performance monitoring and model […].
This article was published as a part of the DataScience Blogathon. Introduction Do you think you can derive insights from raw data? Wouldn’t the process be much easier if the raw data were more organized and clean? Here’s when Data […]. The post What are Schemas in Data Warehouse Modeling?
This article was published as a part of the DataScience Blogathon. Introduction Training and inference with large neural models are computationally expensive and time-consuming. While new tasks and models emerge so often for many application domains, the underlying documents being modeled stay mostly unaltered.
This article was published as a part of the DataScience Blogathon. The post Image Classification Using Resnet-50 Deep Learning Model appeared first on Analytics Vidhya. We will […].
Introduction Git is a powerful version control system that plays a crucial role in managing and tracking changes in code for datascience projects. Whether you’re working on machine learning models, data analysis scripts, or collaborative projects, understanding and utilizing Git commands is essential.
This article was published as a part of the DataScience Blogathon. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT. The key […].
This article was published as a part of the DataScience Blogathon. The post A Complete Guide for Deploying ML Models in Docker appeared first on Analytics Vidhya. The post A Complete Guide for Deploying ML Models in Docker appeared first on Analytics Vidhya.
Introduction Temporal graphs are a powerful tool in datascience that allows us to analyze and understand the dynamics of relationships and interactions over time. They capture the temporal dependencies between entities and offer a robust framework for modeling and analyzing time-varying relationships.
This article was published as a part of the DataScience Blogathon. The post Understanding Word Embeddings and Building your First RNN Model appeared first on Analytics Vidhya. The post Understanding Word Embeddings and Building your First RNN Model appeared first on Analytics Vidhya.
Dear readers, Are you ready to learn some additional datascience this weekend? Brush up your skills with our industry expert Mohammad Shahebaz, Data Scientist at DataRobot. In this edition of DataHour, learn to deploy a deep learning model in production. If yes, then this week’s DataHour can help you do so.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content