This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon Welcome readers to Part 2 of the Linear predictivemodel series. The post Introduction to Linear PredictiveModels – Part 2 appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction : Hello Readers, hope you all are doing well; In. The post Building A Gold Price PredictionModel Using Machine Learning appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Overview: Machine Learning (ML) and datascience applications are in high demand. The post ML-trained Predictivemodel with a Django API appeared first on Analytics Vidhya. The ML algorithms, on […].
ArticleVideos This article was published as a part of the DataScience Blogathon. Hello, There Datascience has been a vastly growing and improving. The post 5 Important things to Keep in Mind during Data Preprocessing! Specific to PredictiveModels). appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Hello readers. The post Linear predictivemodels – Part 1 appeared first on Analytics Vidhya. This is part-1 of a comprehensive tutorial on Linear.
ArticleVideo Book This article was published as a part of the DataScience Blogathon INTRODUCTION: Stroke is a medical condition that can lead to the. The post How to create a Stroke PredictionModel? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Objective An app is to be developed to determine whether an. The post App Building And Deployment of a PredictiveModel Using Flask and AWS appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Overview The core of the datascience project is data & using it to build predictivemodels and everyone is excited and focused on building an ML model that would give us a near-perfect result mimicking the real-world business scenario.
This article was published as a part of the DataScience Blogathon. Introduction The general principle of ensembling is to combine the predictions of various. The post Improve your PredictiveModel’s Score using a Stacking Regressor appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. What is equally important here is the ability to communicate the data and insights from your predictivemodels through reports and dashboards. PowerBI is used for Business intelligence.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction The real-world data can be very messy and skewed, which can mess up the effectiveness of the predictivemodel if it is not addressed correctly and in time.
This article was published as a part of the DataScience Blogathon. Introduction on AutoKeras Automated Machine Learning (AutoML) is a computerised way of determining the best combination of data preparation, model, and hyperparameters for a predictivemodelling task.
This article was published as a part of the DataScience Blogathon. Introduction Feature analysis is an important step in building any predictivemodel. It helps us in understanding the relationship between dependent and independent variables.
This article was published as a part of the DataScience Blogathon. Introduction Machine learning is about building a predictivemodel using historical data. The post Quick Guide to Evaluation Metrics for Supervised and Unsupervised Machine Learning appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Machine Learning is the method of teaching computer programs to do a specific task accurately (essentially a prediction) by training a predictivemodel using various statistical algorithms leveraging data.
This article was published as a part of the DataScience Blogathon. Introduction While trying to make a better predictivemodel, we come across. The post Out-of-Bag (OOB) Score in the Random Forest Algorithm appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Designing a deep learning model that will predict degradation rates at each base of an RNA molecule using the Eterna dataset comprising over 3000 RNA molecules.
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction Some time back, I was making the predictivemodel. The post STANDARDIZED VS UNSTANDARDIZED REGRESSION COEFFICIENT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Overview of Electric Vehicle Sector The supply of fossil fuels is constantly decreasing. The post Data Analysis and Price Prediction of Electric Vehicles appeared first on Analytics Vidhya. The situation is very alarming.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Deep Learning is a very powerful tool that has now. The post Pneumonia Prediction: A guide for your first CNN project appeared first on Analytics Vidhya.
I got my first datascience job in 2012, the year Harvard Business Review announced data scientist to be the sexiest job of the 21st century. Two years later, I published a post on my then-favourite definition of datascience , as the intersection between software engineering and statistics.
Chris Wiggins , Chief Data Scientist at The New York Times, presented “DataScience at the New York Times” at Rev. Wiggins also indicated that datascience, data engineering, and data analysis are different groups at The New York Times. Session Summary. Transcript. Feel free to email me.
2) MLOps became the expected norm in machine learning and datascience projects. MLOps takes the modeling, algorithms, and data wrangling out of the experimental “one off” phase and moves the best models into deployment and sustained operational phase.
The objective here is to brainstorm on potential security vulnerabilities and defenses in the context of popular, traditional predictivemodeling systems, such as linear and tree-based models trained on static data sets. If an attacker can receive many predictions from your model API or other endpoint (website, app, etc.),
by THOMAS OLAVSON Thomas leads a team at Google called "Operations DataScience" that helps Google scale its infrastructure capacity optimally. Over the life of the forecast, the data scientist will publish historical accuracy metrics. Our team does a lot of forecasting.
Smarten is pleased to announce that its Smarten Augmented Analytics solution is included as a Representative Vendor in the Market Guide for Augmented Analytics Published October 2, 2023 (ID G00780764). The Smarten solution requires no datascience skills, knowledge of statistical analysis or BI expertise.
AAI’s recently published “Now and Next State of RPA” report presents detailed results of that survey. The AAI report covers these industries: energy/utilities, financial/insurance, government, healthcare, industrial/manufacturing, life sciences, retail/consumer, services/consulting, technology, telecom, and transportation/airlines.
All predictivemodels are wrong at times?—just As the renowned statistician George Box once quipped , “All models are wrong, but some are useful.” Earlier this month, the FTC even published specific guidelines related to AI , hinting at enforcement actions to come. just hopefully less so than humans.
Since they consume a significant amount of time spent on most datascience projects, we highlight these two main classes of data quality problems in this post: Data unification and integration. An important paradigm for solving both these problems is the concept of data programming.
Arming datascience teams with the access and capabilities needed to establish a two-way flow of information is one critical challenge many organizations face when it comes to unlocking value from their modeling efforts. Domino Data Lab and Snowflake: Better Together. Writing data from Domino into Snowflake.
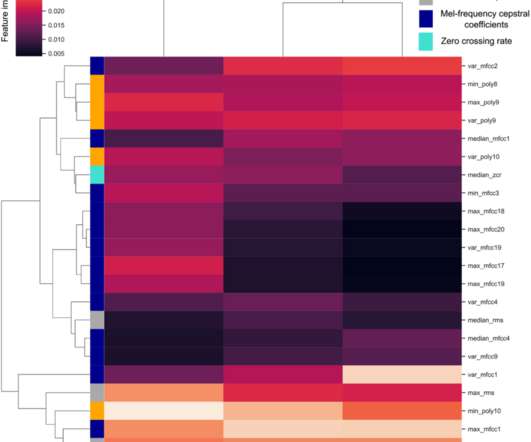
Photo by Devon Divine on Unsplash Originally published in Maslo - Your Virtual Self. This created a summary features matrix of 7472 recordings x 176 summary features, which was used for training emotion label predictionmodels. To prevent data-leakage issues, actors in the training dataset did not reappear in the test datasets.
While data scientists were no longer handling Hadoop-sized workloads, they were trying to build predictivemodels on a different kind of “large” dataset: so-called “unstructured data.” And it was good. For a few years, even. But then we hit another hurdle.
We also celebrated the first-ever winner of the Data Impact Achievement Award — a new award category that recognizes one customer who has consistently achieved transformation across their business, pursuing a diverse set of use cases and creating a culture of data-driven innovation. . Data Impact Achievement Award.
Even in the absence of a formal C-level sustainability mandate, proactive data leadership can lay the foundation for future ESG integration, helping businesses stay ahead of regulatory and market expectations. Investing in datascience and AI for sustainability Advanced analytics and AI can unlock new opportunities for sustainability.
Our previous Domino Blog on the Curse of Dimensionality [2] , describes weird behaviors that emerge in data when P >> N: Points move far away from each other. Points fall on the outer edges of the data distribution. Predictivemodels fit to noise approach 100% accuracy.
In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the datascience workflow.
However, data copy and duplication are allowed considering various consumption needs in terms of formats and latency. Data outbound Data is often consumed using structured queries for analytical needs. Also, datasets are accessed for ML, data exporting, and publishing needs.
The Gartner report entitled, ‘Augmented Analytics Is the Future of Data and Analytics, published on October 31, 2018, includes the following strategic assumptions: By 2025, a scarcity of data scientists will no longer hinder the adoption of datascience and machine learning in organizations.
Machine learning, artificial intelligence, data engineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of datascience, streaming, and machine learning (ML) as disruptive phenomena.
Using variability in machine learning predictions as a proxy for risk can help studio executives and producers decide whether or not to green light a film project Photo by Kyle Smith on Unsplash Originally posted on Toward DataScience. Are you interested in working on high-impact projects and transitioning to a career in data?
Chris Lysy is a professional data designer and illustrator constantly exploring the overlap between contemporary design practice, digital communications, and datascience. David Napoli has worked with data for over 20 years as an analyst, actuary, statistician, research manager, and director. Chris Lysy. Kylie Hutchinson.
Bias in Machine Learning Algorithms (Bottom Photos Source: ProPublica ; Top Photos Source: Pexels.com) Biases in predictivemodeling are a widespread issue Machine learning and AI applications are used across industries, from recommendation engines to self-driving cars and more. 5 is labeled as low.
Today, BI vendors are already introducing AI capabilities in their products for data preparation, data discovery, and datascience. Data from multiple sources was normally stored in silos, and research was typically presented in a fragmented, disjointed report that was open to interpretation.
The prod-hema-data-catalog is the production-grade catalog that supports data sharing across production services and, in some cases, pre-production services. After the request is received, the core data platform team assesses the requirements and initiates the creation of projects and environments in Amazon DataZone.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content