This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. This supports the growing emphasis on event-drivendata pipelines. When we announced support for version 2.9.2
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
At AWS, we are committed to empowering organizations with tools that streamline data analytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. Plus, AI can also help find key insights encoded in data.
Data is the foundation of innovation, agility and competitive advantage in todays digital economy. As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Data quality is no longer a back-office concern.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly datadriven.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
In today’s rapidly evolving financial landscape, data is the bedrock of innovation, enhancing customer and employee experiences and securing a competitive edge. Like many large financial institutions, ANZ Institutional Division operated with siloed data practices and centralized data management teams.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that you can use to analyze your data at scale. Redshift Data API provides a secure HTTP endpoint and integration with AWS SDKs. Calls to the Data API are asynchronous.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Data lineage is the journey data takes from its creation through its transformations over time. Tracing the source of data is an arduous task. With all these diverse data sources, and if systems are integrated, it is difficult to understand the complicated data web they form much less get a simple visual flow.
Part 2: Introducing Data Journeys. Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their data analytics processes. The goal of DataOps is to help organizations make better use of their data to drive business decisions and improve outcomes.
Such a solution should use the latest technologies, including Internet of Things (IoT) sensors, cloud computing, and machine learning (ML), to provide accurate, timely, and actionable data. To take advantage of this data and build an effective inventory management and forecasting solution, retailers can use a range of AWS services.
Replace manual and recurring tasks for fast, reliable data lineage and overall data governance. It’s paramount that organizations understand the benefits of automating end-to-end data lineage. The importance of end-to-end data lineage is widely understood and ignoring it is risky business. Doing Data Lineage Right.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with data engineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog.
As the world is gradually becoming more dependent on data, the services, tools and infrastructure are all the more important for businesses in every sector. Data management has become a fundamental business concern, and especially for businesses that are going through a digital transformation. What is data management?
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
The difference is in using advanced modeling and data management to make faster scenario planning possible, driven by actionable key performance measures that enable faster, well-informed decision cycles. This may sound like FP&A’s mission today. Today, FP&A organizations perform much of this work manually.
Alerts and notifications play a crucial role in maintaining data quality because they facilitate prompt and efficient responses to any data quality issues that may arise within a dataset. It simplifies your experience of monitoring and evaluating the quality of your data.
This means we can double down on our strategy – continuing to win the Hybrid Data Cloud battle in the IT department AND building new, easy-to-use cloud solutions for the line of business. It also means we can complete our business transformation with the systems, processes and people that support a new operating model. .
Today’s healthcare providers use a wide variety of applications and data across a broad ecosystem of partners to manage their daily workflows. Integrating these applications and data is critical to their success, allowing them to deliver patient care efficiently and effectively. What is HL7? What is the FHIR Standard?
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. The data in the machine-readable files can provide valuable insights to understand the true cost of healthcare services and compare prices and quality across hospitals.
Different communication infrastructure types such as mesh network and cellular can be used to send load information on a pre-defined schedule or eventdata in real time to the backend servers residing in the utility UDN (Utility Data Network).
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. What is data integrity? Data integrity risks.
If you can’t make sense of your business data, you’re effectively flying blind. Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. Azure Data Factory.
This is a guest post co-written by Alex Naumov, Principal Data Architect at smava. smava believes in and takes advantage of data-driven decisions in order to become the market leader. smava believes in and takes advantage of data-driven decisions in order to become the market leader.
We just announced the general availability of Cloudera DataFlow Designer , bringing self-service data flow development to all CDP Public Cloud customers. In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service data pipeline development.
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow , a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery.
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications.
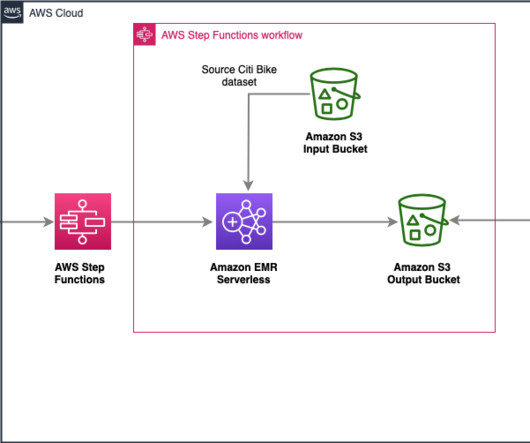
You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. AWS Step Functions is a serverless orchestration service that enables developers to build visual workflows for applications as a series of event-driven steps.
Infomedia Ltd (ASX:IFM) is a leading global provider of DaaS and SaaS solutions that empowers the data-driven automotive ecosystem. In this post, we share how Infomedia built a serverless data pipeline with change data capture (CDC) using AWS Glue and Apache Hudi.
You can’t talk about data analytics without talking about data modeling. The reasons for this are simple: Before you can start analyzing data, huge datasets like data lakes must be modeled or transformed to be usable. Building the right data model is an important part of your data strategy.
In recent years, driven by the commoditization of data storage and processing solutions, the industry has seen a growing number of systematic investment management firms switch to alternative data sources to drive their investment decisions. Each team is the sole owner of its AWS account.
This allows you to simplify security and governance over transactional data lakes by providing access controls at table-, column-, and row-level permissions with your Apache Spark jobs. Many large enterprise companies seek to use their transactional data lake to gain insights and improve decision-making.
In this post, we share how the AWS Data Lab helped Tricentis to improve their software as a service (SaaS) Tricentis Analytics platform with insights powered by Amazon Redshift. Although Tricentis has amassed such data over a decade, the data remains untapped for valuable insights.
Where they have, I have normally found the people holding these roles to be better informed about data matters than their peers. Prelude… I recently came across an article in Marketing Week with the clickbait-worthy headline of Why the rise of the chief data officer will be short-lived (their choice of capitalisation).
To build a data-driven business, it is important to democratize enterprise data assets in a data catalog. With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. GenericInMemoryCatalog stores the catalog data in memory.
Healthcare is changing, and it all comes down to data. Data & analytics represents a major opportunity to tackle these challenges. Indeed, many healthcare organizations today are embracing digital transformation and using data to enhance operations. How can data help change how care is delivered?
Many thanks to AWP Pearson for the permission to excerpt “Manual Feature Engineering: Manipulating Data for Fun and Profit” from the book, Machine Learning with Python for Everyone by Mark E. Feature engineering is useful for data scientists when assessing tradeoff decisions regarding the impact of their ML models.
Its AI/ML-driven predictive analysis enhanced proactive threat hunting and phishing investigations as well as automated case management for swift threat identification. Options included hosting a secondary data center, outsourcing business continuity to a vendor, and establishing private cloud solutions.
A data pipeline is a series of processes that move raw data from one or more sources to one or more destinations, often transforming and processing the data along the way. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content